 夜雨聆风
夜雨聆风
引子:那一万两千个岗位,像一座山
拿到船票那天晚上,我失眠了。不是兴奋,是焦虑。
军转安置,每个转友都躲不过这一关。接到通知,翻开历史积累的岗位信息表——好家伙,一万两千多条岗位密密麻麻地铺在眼前。每一条都有单位、部门、岗位名称,后面跟着一串条件描述:“中共党员,具有三年以上机关工作经历,有较强的文字综合能力,熟悉科研项目管理全流程,有军级以上机关工作经历者优先……”
我根据自己的情况做了初步筛选,然后开始一条一条地看。看了五十条,眼睛开始发花;看了两百条,已经分不清哪条更适合我了。那一刻我意识到:靠人力硬扛,不是办法。可我偏偏不是什么技术大牛——管过信息系统论证项目,写过技术方案,但要说写代码,距离上次编程还是十八年前刚工作的那两年,而现在从头开始学编程,明显来不及也不现实。
我就这么卡住了。一边是历史积累的一万两千个岗位,一边是有限的精力和技术能力。那种感觉怎么形容呢——就像站在一个巨大的迷宫入口,你知道出口的大致方向,但手里的地图却是细密繁复,各类信息交织混杂,找不到头绪。
直到我遇见了AI智能体。
就在我准备认命、打算靠Excel加肉眼继续死磕的时候,我刷到了一个关于AI Agent(AI智能体)的介绍视频。视频里演示了一件事,彻底改变了我的思路:AI现在已经能听懂人话了。你不需要会写代码,只需要用自然语言告诉它你想干什么。你说“帮我分析这个Excel表格”,它能理解;你说“这条判断逻辑不对,帮我查一下”,它能在几百行代码里找到问题;你说“记住这个规则,以后别再犯”,它真的能记住。
看到这里,我心里动了一下:军转选岗这件事,也许AI真的能帮上忙。
但我没有选择豆包——三个绕不过去的坎
说实话,我最朴素的想法就是打开豆包,把简历和岗位表一股脑丢进去,让它帮着匹配。我试了。很快放弃了。不是豆包不好用,而是选岗这件事,有三个问题豆包解决不了:
第一,数据安全这根弦不能松。
军转人的简历里写满了单位信息、职务经历、项目成果、工作成绩。这些内容一旦上传到公网平台,安全就不再受控。服务商承诺再多,也无从验证数据的安全性。信息安全是底线,没得商量。
第二,岗位推荐的随机性。
豆包的推荐结果是个黑盒——你不知道它是怎么得出结论的。可能被某个关键词误导了,可能忽略了你明确标注的排除领域。等到临近提交报名的时候才发现完全不匹配,那之前的时间和精力就全白费了。选岗容错率太低,我不敢赌。
第三,它记不住你的规则。
这是最让我难受的一点。当我发现某条岗位匹配结果不对,想让豆包“记住这个规则,下次别再犯”——做不到。每次对话都是从零开始,完全积累不了任何经验。但选岗不是一次性选择题,它是一个需要反复打磨判断标准的过程。你今天觉得某个条件重要,明天看了更多岗位后又想调整权重,这种迭代式的思考过程,豆包的交互方式天然不支持。
豆包、元宝等 | AI 智能体 | |
工作方式 | 一次性问答,每次从头来 | 持久化规则,持续迭代 |
可控性 | 黑盒输出,无法追踪 | 步步可查,随时改规则 |
可积累性 | 没有记忆,几次就归零 | 修一个Bug就固化一条规则 |
说白了,豆包这类工具和AI智能体之间有一个本质区别:前者是一次性聊天机器人,每次问完就忘;后者是一个能持久记忆、持续迭代的数字工作伙伴。选岗需要的恰恰是后者。
于是我自己搭了一个工具
既然现成的工具满足不了需求,那就自己动手。我的思路其实很简单,分两步走:
第一步:把简历变成机器能读懂的样子。
先把个人简历中涉及敏感信息的内容做脱敏处理,然后提取出一份“个人画像”——我有什么能力?科研管理、后勤保障、新闻宣传、人事工作……把这些能力标签按核心程度排个序,只保留那些有据可查的真实能力,不吹不黑。
第二步:让工具逐条理解岗位要求。
从岗位信息表中,将每一岗位的条件描述中提取关键词——科研、后勤、财务、审计、宣传……然后把它们和用户的个人画像放在一起比对。
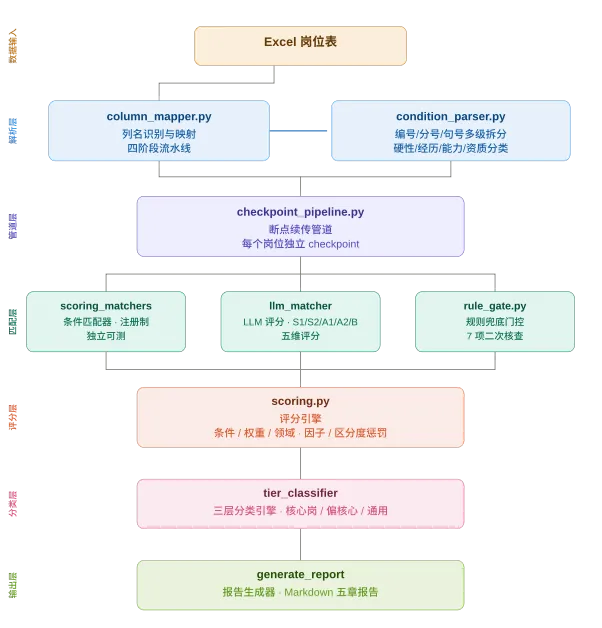
但这里有个关键点:光靠数关键词是不够的。比如岗位要求“具有科研项目管理经验”,而你简历写的是“十年装备科研管理经历”——字面上不完全一样,但意思高度相关。这种“意思对不对”的判断,必须依靠AI的语言理解能力,而不是简单的文字匹配。这就是为什么我最终选择了大模型来做这件事。
打分也不是笼统给一个总分。工具会从多个维度分别评测:条件匹配度怎么样?领域适不适合?综合推荐值多少?评完之后还有一套“安检门”——学历够不够?英语等级达标吗?有职业资格证要求吗?专业对口吗?这些硬性条件逐一核验,一条都不能漏。
你可以把它想象成两条线在配合工作:AI负责“理解”——读懂每条岗位到底在要什么;规则系统负责“把关”——硬性条件一条条过。两条线互相制衡,谁也替不了谁。
所有岗位评分完成后,工具会把它们分成三类:核心岗(最匹配的主赛道选择)、偏核心岗(次优备选)、通用岗(你有资格报但不是首选)。每个岗位归到哪一类、为什么,全部可以追溯——不是我拍脑袋决定的,是每一步都有依据。

语义理解的准确度直接决定了整个工具的靠谱程度。这方面我实测了几种方案:目前DeepSeek的效果最好,是我正在使用的核心引擎;本地部署的开源模型在复杂条件的理解上明显差一截,而且非常依赖电脑配置;智谱GLM比本地模型强不少,但跟DeepSeek比还有差距。所以我特意把“评分引擎”和“底层模型”设计成解耦的——现在用DeepSeek保质量,等将来本地模型能力追上来了,直接替换就行,不需要改动任何一条匹配规则。另外,你的个人画像始终在本地处理,只有岗位条件描述会调用云端API做分析和比对——在隐私保护和效果之间,找一个能接受的平衡点。
从选岗到全流程
真正让我兴奋的,不只是匹配本身,而是这套思路可以延伸到更远的地方。选岗之后是什么?面试准备——这家单位主要做什么?面试可能会问什么?怎么回答更有针对性?通勤评估——家到单位多远?开车、公交、骑车各要多久?待遇比较——不同单位的收入水平大概什么量级?这些问题,每一个都需要大量信息搜集和分析。而AI恰好擅长这些。
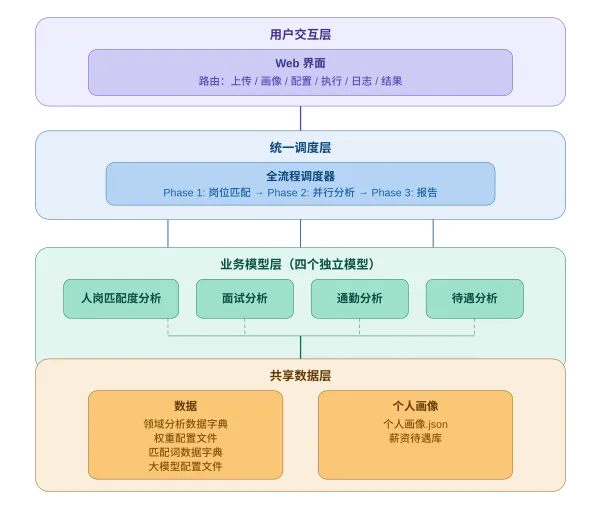
所以我把整个平台设计成了四个环节:
第一个环节就是前面说的岗位匹配——核心引擎,解析岗位表、拆解条件、完成评分排序。
模型 | 做什么 | 怎么做的 |
面试分析 | 生成结构化面试准备指南 | 结合单位公开信息(职能、架构、重点工作、领导讲话)和《梦回谈面试》,生成有针对性的面试题与答题思路 |
通勤分析 | 评估三种通勤方式 | 调用高德地图API,分析驾车、公交、骑行的距离与耗时 |
待遇分析 | 评估岗位经济待遇水平 | 基于互联网收集的数据做初步评估 |
匹配出重点岗位之后,同时启动三条并行分析线:
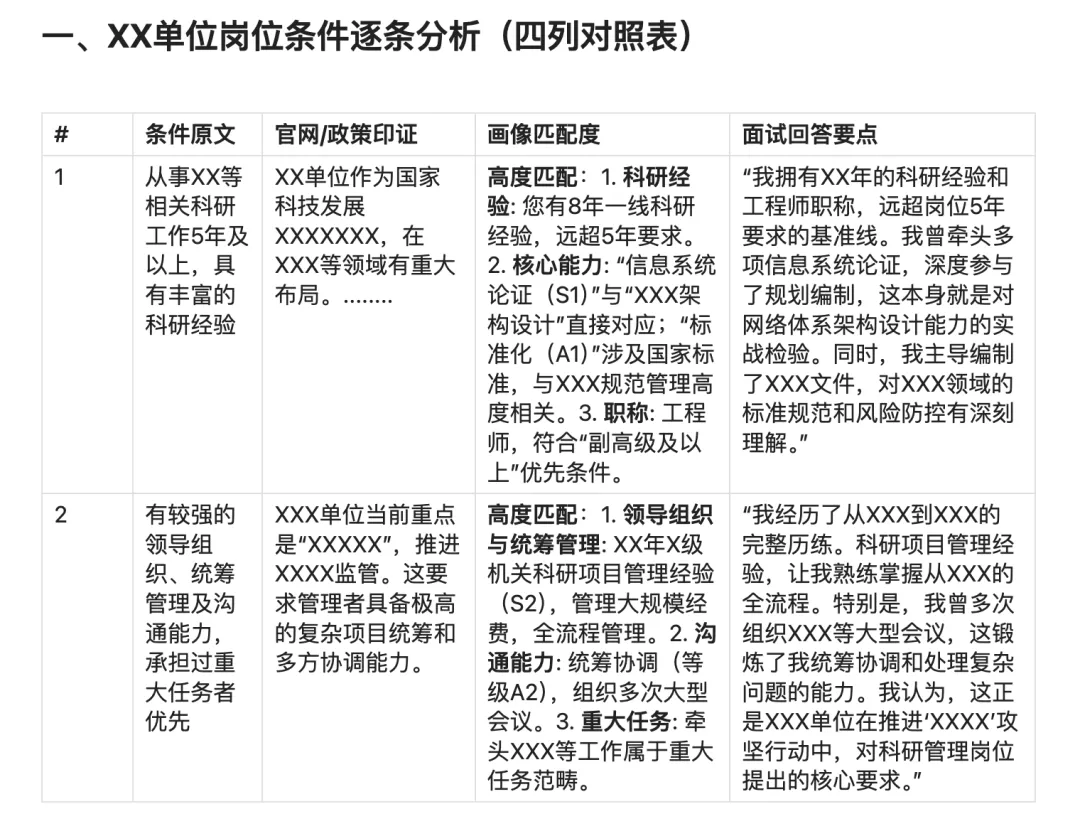
1.面试分析:结合单位公开信息和《梦回谈面试》,生成针对性的面试准备指南:这家单位最近在推什么重点工作?领导在会上强调了什么?面试官可能关心什么?
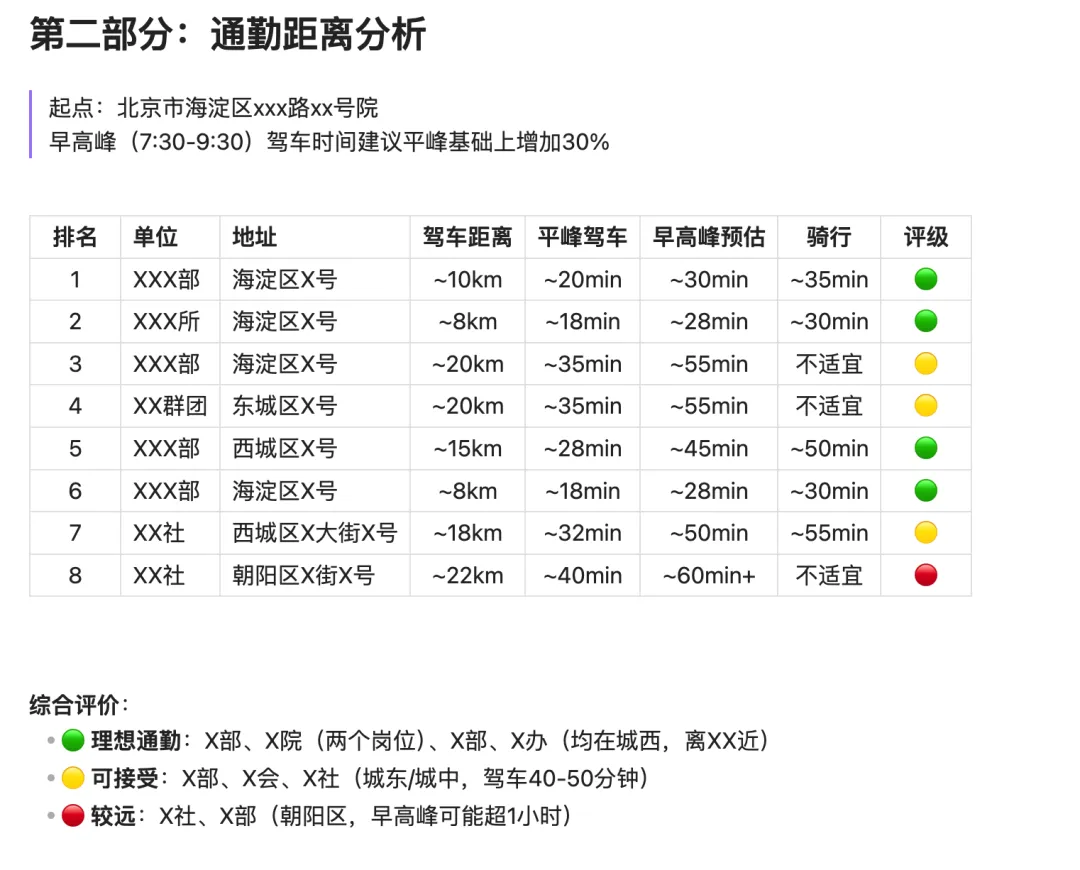
2.通勤分析:调用地图数据,帮你算清楚三种通勤方式的距离和时间。
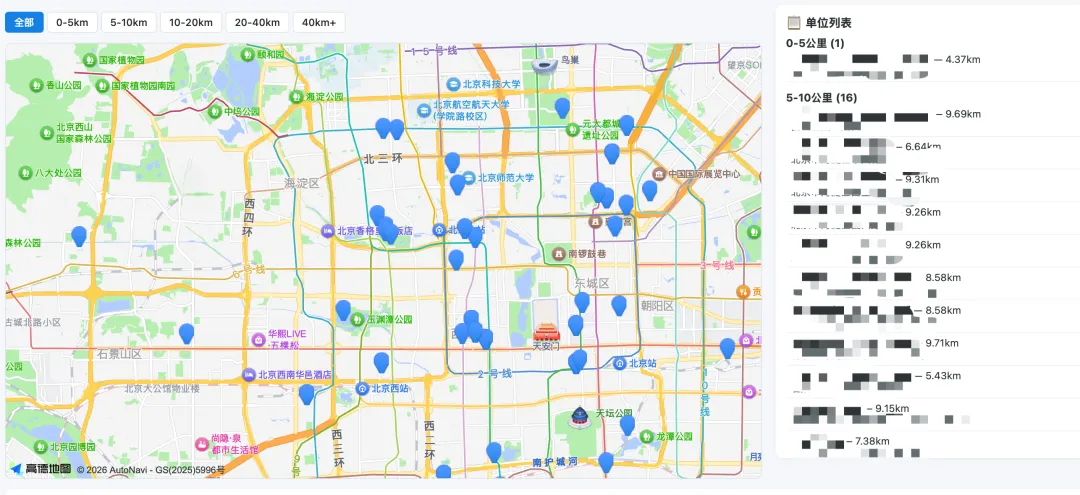
3.待遇分析:基于互联网公开数据,对岗位的经济待遇做一个初步评估。
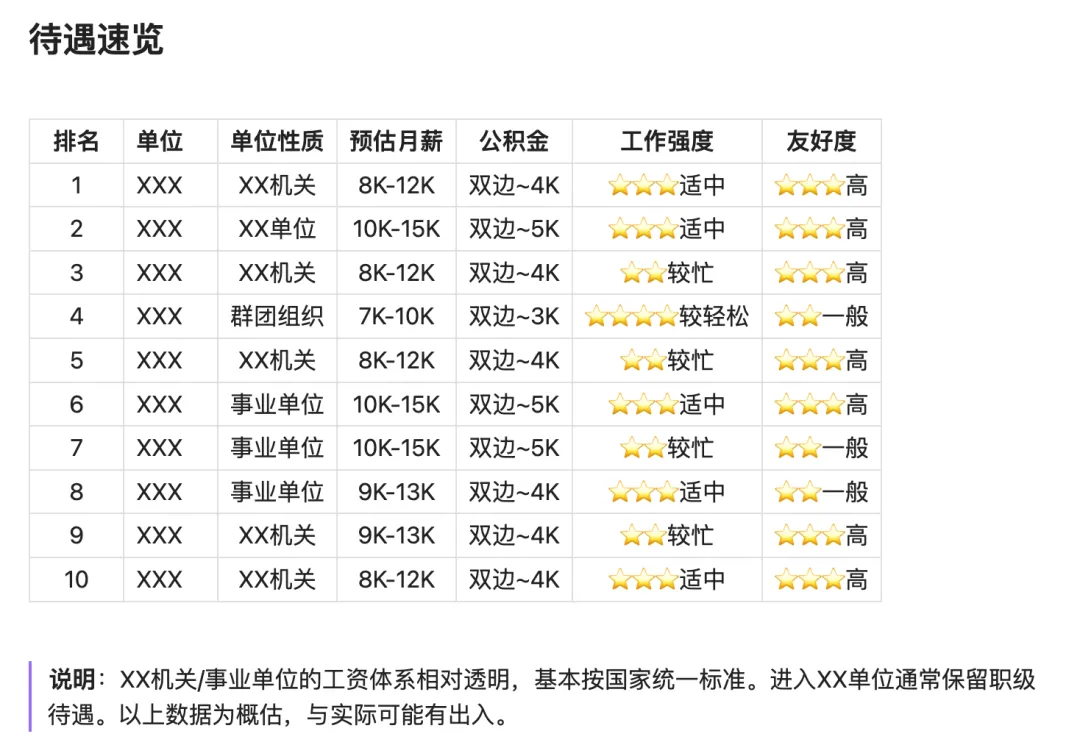
最后,所有分析汇总成一份完整的决策报告——从匹配排名到面试建议,从通勤方案到待遇对比,一目了然。
坦诚地讲,目前除了岗位匹配引擎相对成熟之外,其他几个环节还在完善中。但框架已经搭好了,就像盖房子,地基和结构有了,后续就是一间一间地装修。
工具帮忙,但不替你拍板
用了这段时间,有一个感受越来越强烈:
AI确实能把效率提上去。以前花几个小时翻岗位表、做Excel比对、纠结哪个该报哪个不该报——现在跑一遍评分,三层分类清清楚楚,省下来的时间和精力可以真正用在刀刃上,比如准备面试。
但是,“尽信老转不如无老转,尽信工具也不如不信工具。”语义匹配的边界在哪里?排除条件的颗粒度设多大?规则门控的阈值定多高?样本少的时候不容易暴露问题,一旦更多转友使用、更多样的情况涌进来,一定会出现新的状况。工具需要大量的真实反馈和持续迭代,才能真正变得可靠。
说到底,这个工具本质上是一个“翻译器”。
一头帮转友把多年的军旅经历,“翻译”成地方用人单位能看懂的能力语言;另一头把晦涩的岗位条件,“翻译”成你能理解的匹配分析。但翻译得准不准,最终还得人来判断。
在整个过程中,最有价值的不是写了多少行代码,而是三件事:知道自己要什么、知道哪里不对、知道怎么一步步逼近正确答案。AI把技术的门槛降到了接近零,但“说清楚自己要什么”这件事——它替不了人类。

最后想说的话
做了这段时间的探索,最大的感触其实是这句话——军转安置这条路,信息不对称、时间紧、决策压力巨大,这三座大山压在每个转友身上。AI不能替你做决定,但它可以把一万两千条筛到几十条,帮你看清每条岗位匹配在哪、红线在哪。AI智能体不是魔法棒,但它确实能让复杂的事情变简单一点,哪怕只是一点点。
回到最开始的问题:我的核心竞争力从来不是编程,而是清楚地知道自己想要什么、敏锐地察觉哪里有问题、耐心地把需求一步步转化为可执行的方案。AI把技术门槛降低了,但“知道自己要什么”这件事,每个转友都需要在转途中不断梳理和自我认知,确定“个人画像”具体长什么样子。多年的军旅生涯,判断力、直觉、认知,这些才是真正不可替代的东西。
我现在仍在备考阶段,时间有限,但这个工具会一直沿着“人人为我,我为人人”精神往前走:不求一步到位,只求每一步都比上一步更靠谱。
分享出来,是想告诉每一位转友:如果你也在为选岗发愁,不妨试试用AI智能体帮自己一把。不需要懂技术,不需要会编程,你需要做的只有一件事——想清楚自己要什么。
特别感谢两位摆渡人在技术思路上的无私帮助和建议。这种帮助与扶持,大概是这条路上最暖心的东西了。
欢迎留言交流。让AI多干点活,让每一位转友的军转路,走得比昨天更清楚一点点。


