 夜雨聆风
夜雨聆风当 AI 学会"听"和"等":Audio-Interaction 给音频大模型装上交互本能
一句话总结
把"必须给完整音频才回答"的离线范式,转成"持续听、按语义决定何时回应"的在线统一模型。一个模型,同时做流式 ASR、语音对话、同声传译、主动援助。
论文:arxiv.org/abs/2606.05121
项目:xzf-thu.github.io/Audio-Interaction
数据:huggingface.co/datasets/zhifeixie/StreamAudio-2M
现有音频大模型的"离线病"
过去两年,大型音频语言模型(LALM)突飞猛进:能识别情绪、能做多步推理、能调用工具,甚至能从声音里直接生成代码。
但它们有一个根本缺陷——都是离线的。
y = f(x, A)
必须给完整音频 A 和文本指令 x,模型才肯答一次。这跟 LLaVA 等多模态设计一脉相承,却和音频"天生是流"的本质南辕北辙。
为了补这个窟窿,业界搞了一堆专用流式模型:流式 ASR、流式语音对话、同声传译……一个能力一个模型,从零训练。结果就是:
- • Moshi 会聊天但听不懂咳嗽、读不出犹豫
- • 流式 ASR 只能转写,遇到问句直接懵
- • 同声传译模型不会判断"现在该不该翻"
是时候换个范式了。
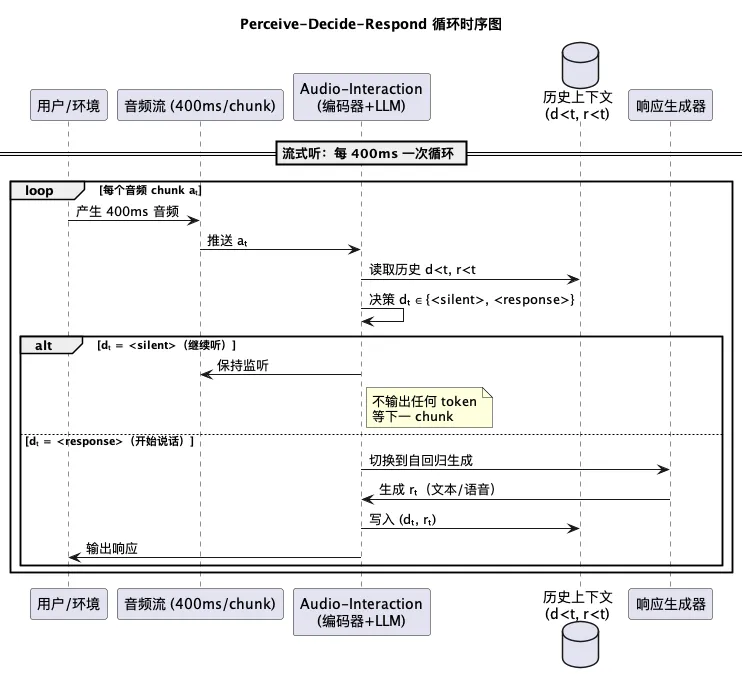
核心范式:Perceive–Decide–Respond 循环
论文提出 Audio Interaction Model (AIM),并实现成 Audio-Interaction:
(dₜ, rₜ) = f(a≤ₜ, d<ₜ, r<ₜ)
- • 每 400ms 一个音频 chunk
aₜ - • 模型在每步预测一个特殊 token
<silent>或<response> - • 选
<silent>就继续听;选<response>就切到自回归生成模式 - • 历史
d<ₜ, r<ₜ一起进上下文,长程记忆有保障
传统 ASR、翻译、对话,全都成了这条流上的"指令"——一模型打天下。
三个拦路虎
把范式从离线搬到流式,作者点出三个新挑战:
C1:理解到位的响应触发。 离线模型是被动等喂完整段再答;交互模型必须自己判断现在该说还是该等。监督信号又稀疏又有时间歧义,公开数据里没有"流 + 何时插嘴"的标注。
C2:chunk 推理下的上下文连续性。 400ms 一切,破坏了声学连续性,长程上下文又不能堆爆显存。模型得跨 chunk 重建连续性。
C3:实时性。 第一帧延迟直接决定能不能用,编码解码不能互相等。
SoundFlow:端到端闭环框架
围绕这三大挑战,论文提出 SoundFlow 框架,从数据到训练到部署全包。
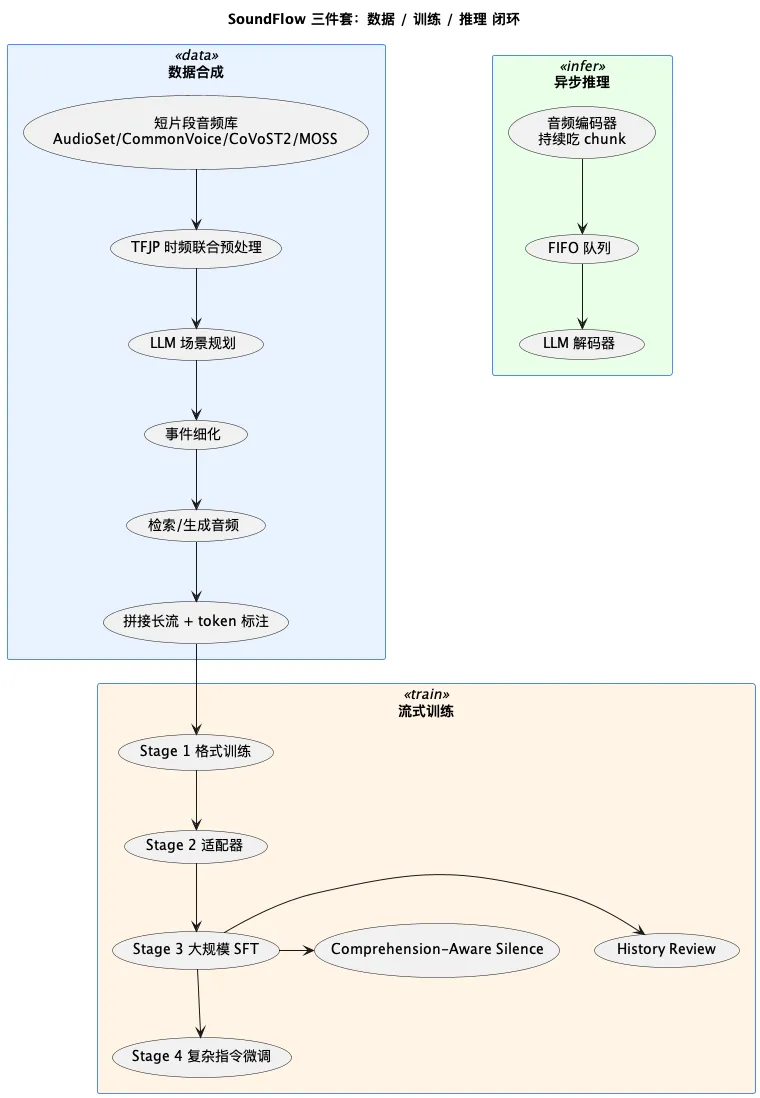
第一件套:流式数据合成
两块:
① TFJP 时频联合预处理。 不是简单切静音,而是:
- • 估底噪 → 频域去噪
- • 定位最稠密的信息段(core_locate)
- • 边界半 chunk 对齐 + 短窗频谱平滑
- • 迭代稳定后再剪一次
这样切出来的片段,缝起来才像真实录音。
② 层次化事件策划。 简单随机拼接会"车喇叭和人说话撞一起"这种破事。论文用:
- • LLM 先规划场景(多个 topic)
- • 再把 topic 细化成具体事件
- • 事件 → 检索音频库 Top-3 候选 → 不行就用生成模型造
场景一致,事件不打架,缝出来的长流才有意义。
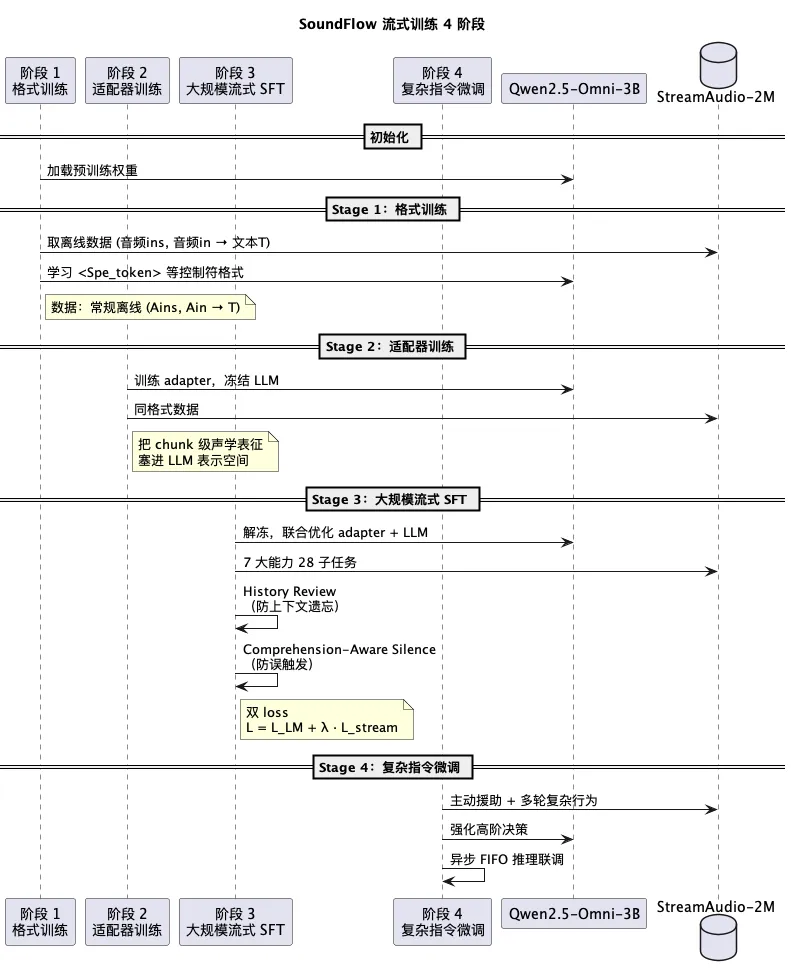
第二件套:流式训练
双 loss 联合优化:
- • 语言模型 loss(标准 next-token 预测)
- • 流式控制 token loss(预测
<silent>/<response>) - • 权重
λ调平衡
四阶段训练流程:
- 1. 格式训练:教模型认识
<Spe_token>这类新控制符 - 2. 适配器训练:把 chunk 级声学表征塞进 LLM 空间
- 3. 大规模流式 SFT:联合优化适配器 + LLM,覆盖 ASR、对话、音频理解
- 4. 复杂指令微调:多轮、主动援助等高阶行为
针对两个常见病加药:
- • 上下文遗忘 → 在序列后段插入"前面讲过啥"的提问做 history review
- • 误触发 → 喂大量"应该沉默"的负样本,做 comprehension-aware silence
第三件套:异步推理
异步 FIFO 编码/解码解耦:
- • 编码器持续吃 chunk、塞进队列
- • 解码器从队列拿,独立自回归生成
- • 首帧延迟砍 4.5×
编码解码互不阻塞,稳定 24/7 实时互动。
数据 & 评测
StreamAudio-2M
- • 2.6M 样本 / 302k 小时 / 7.4M 轮
- • 7 大能力 28 子任务(ASR、翻译、对话、音频理解、主动响应、环境感知 agent …)
- • 每个样本 3–15 轮交互,带稀疏的"上下文相关"响应触发
ProactiveSound-Bench
- • 644 个人工设计事件
- • 专门测"没指令也主动出手"这种新能力
- • 现有模型在这上面几乎全挂
效果
8 个 benchmark:
- • 基础能力不掉点:MMAU 58.15 vs SOTA 57.81
- • 全语音 / 多轮场景全面胜出
- • 主动介入能力最强
现场对比(项目页直接可看):
→ 数重复声音:Audio-Interaction 喊 "once / twice / three / four / five";gpt-realtime & seeduplex 全程沉默
→ 咳嗽 + 背景音乐:Audio-Interaction 主动说"你咳嗽了多喝水" + 准确识别音乐风格;gpt-realtime 只识别音乐、seeduplex 全沉默
Moshi 类模型干脆把非语音当背景;GPT-realtime 在开放场景答非所问;只有 Audio-Interaction 听懂、决定、说话。
值得借鉴的思路
论文最大的三个启示,跨模态也通用:
① "何时说话"是可独立学习的目标。 把"是否响应"和"响应什么"解耦,前者作为一个独立的二分类 / 序列决策,可以学到很强的触发策略。这思路直接能搬去视频监控、工业 agent 主动报警。
② 层次化数据合成 >> 随机拼接。 "场景规划 + 事件拆解 + 检索/生成" 这套流水线,在视频、长文档、机器人轨迹数据合成上都是同构问题。
③ 异步解耦是实时多模态的工程银弹。 编码/解码解耦 + 异步队列,把"必须等编完才能解"这个串行瓶颈打掉。首帧延迟砍 4.5× 是真金白银。
写在最后
Audio-Interaction 的野心,不是"再造一个更准的 ASR",而是把"音频模型"这个物种,从"工具"升级成"会听会等的智能体"。
一旦"何时说话"成为模型可学习的目标,"流"就不再是工程负担,而成了新的能力维度。
下一代实时多模态 agent,大概率会从这条范式里长出来。
📎 论文:arxiv.org/abs/2606.05121
🌐 项目:xzf-thu.github.io/Audio-Interaction
📊 数据:huggingface.co/datasets/zhifeixie/StreamAudio-2M
🏛 单位:NTU / NUS / CUHK
