 夜雨聆风
夜雨聆风周一上午的内部会,经常会出现一个很像的场景。
老板说,最近 AI 这么热,我们是不是也该做一个。业务负责人马上能举出几个痛点:销售线索太多跟不过来、客服升级单整理太慢、新员工培训问答重复度很高。技术团队接着问,要接哪些系统、谁给权限、怎么审计、出了错谁兜底。会开到最后,大家都觉得这事重要,但还是没有人能回答一个最基本的问题:这个项目现在到底该不该立,先从哪一步试,什么情况下应该直接打回。
所以今天这篇不讨论哪个模型更强,也不讨论哪个平台连接器更多。我更想把立项前最容易被跳过的一步补上:在试点之前,先用一张评估清单,把“值得不值得做、能不能做、怎么验收”问清楚。
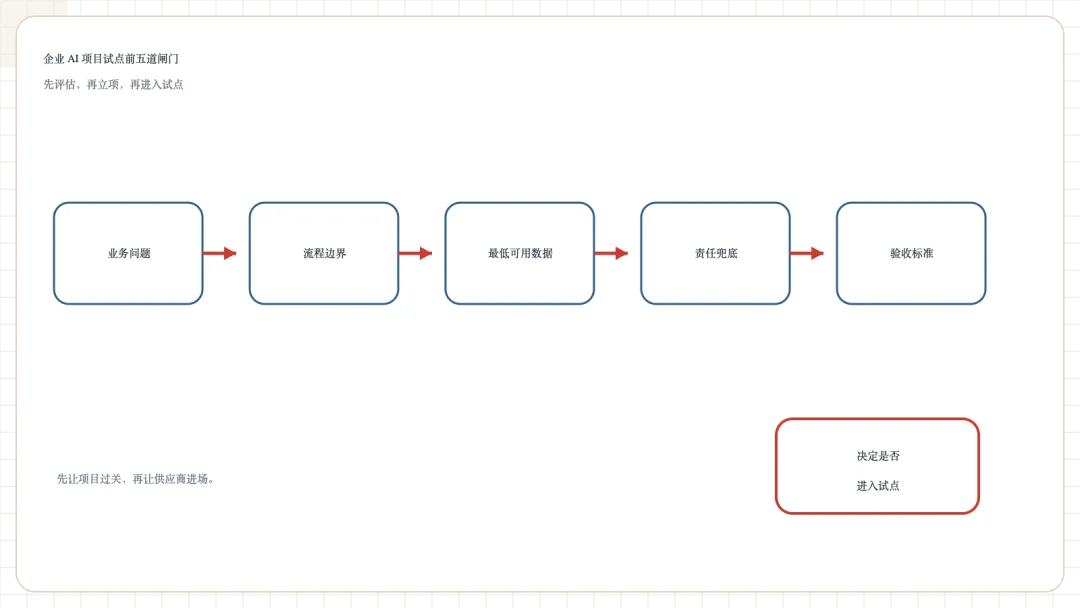
很多企业的 AI 项目,不是死在技术实现,而是死在立项顺序。
顺序一旦反过来,事情就会很快失控。先看 Demo,团队会被效果带着走;先谈平台,范围会越收越大;先谈 ROI,大家又容易在没有基线的情况下承诺结果。等到真正进入业务现场,才发现流程边界没说清、数据权属没说清、使用责任没说清,最后只能一边做一边补洞。
这不是少数企业的个别问题。麦肯锡 2025 年全球 AI 调查显示,88% 的受访企业已经在至少一个业务功能里常态化使用 AI,但大多数仍停留在实验或试点阶段,真正开始规模化推进的大约只有三分之一。微软 2025 Work Trend Index 也给出了一组很有代表性的信号:82% 的领导者认为 2025 年是重构战略和运营的关键年份,但同时 80% 的全球员工表示自己缺少完成工作的时间或精力。换句话说,企业现在缺的往往不是“要不要做 AI”的共识,而是“什么项目值得往前推、什么项目应该先打回”的判断能力。
所以,试点前评估清单的作用,不是帮企业把所有问题一次想完,而是先淘汰伪需求,收住范围,把第一轮验证压到一个能看见证据的尺度。
第一组问题,只看业务价值,不看技术想象。
企业内部说“想做一个销售 AI”时,往往是在说很多不同的事情。有人想缩短新线索初筛时间,有人想让客户拜访纪要更快进入 CRM,有人只是觉得同行都在做,自己不能落后。三种出发点,后面的项目路径完全不同。
所以立项前至少要问四个问题:
•这个问题是不是高频出现,而不是偶发性抱怨。
•如果今天不做 AI,业务团队会用什么办法继续处理。
•当前最痛的不是“人觉得累”,而是哪个明确动作慢、乱、容易漏。
•这件事一旦做好,最先改善的是时间、质量、转化、响应,还是培训复制效率。
这里最容易踩的坑,是把“方向正确”误当成“现在就该做”。方向正确不代表项目成熟。比如很多企业都想做内部知识问答,但如果真正痛的是新人一周内找不到最新 SOP,那立项对象就不是“做一个知识助手”,而是“缩短新人找到有效答案的时间”。
第二组问题,问的是流程,不是部门。
第一次看一个 AI 项目,我最警惕的说法通常不是“这个项目太难”,而是“这个项目可以覆盖整个销售流程”或者“把客服、销售、交付全串起来”。一旦这样定义,第一轮就很容易变成平台工程,而不是可验证试点。
更稳的问法应该是:它准备进入哪个具体动作?
拿三个常见场景来说:
•销售线索初筛:不是“做销售 AI”,而是“对新进线索做首轮分级,并给出跟进建议”。
•客服升级单:不是“做智能客服”,而是“把升级单摘要、问题归类和历史相似案例先整理给人工处理人”。
•新员工培训:不是“做 AI 培训平台”,而是“让岗位新人先问到最新制度、产品规则和常见错题解释”。
流程边界说清以后,要继续补三件事:
•这一动作的输入从哪里来。
•输出交给谁,最后写回哪里。
•超出边界时,转人工的节点在哪里。
真实案例里,跑得比较顺的项目通常都不是从“大而全”开始。比如微软今年 1 月披露的 Hertz 案例,它没有先做一个覆盖全部客服的通用智能体,而是在单一场景里先试一个路边救援客服 Agent,限定知识来源,只在一个站点试点,结果是早期试点就把客户问题处理时间压低了 15% 以上。这个案例最有价值的地方,不是“15%”这个数字本身,而是它说明:先收窄流程,再验证效果,比一开始就做全链路更现实。
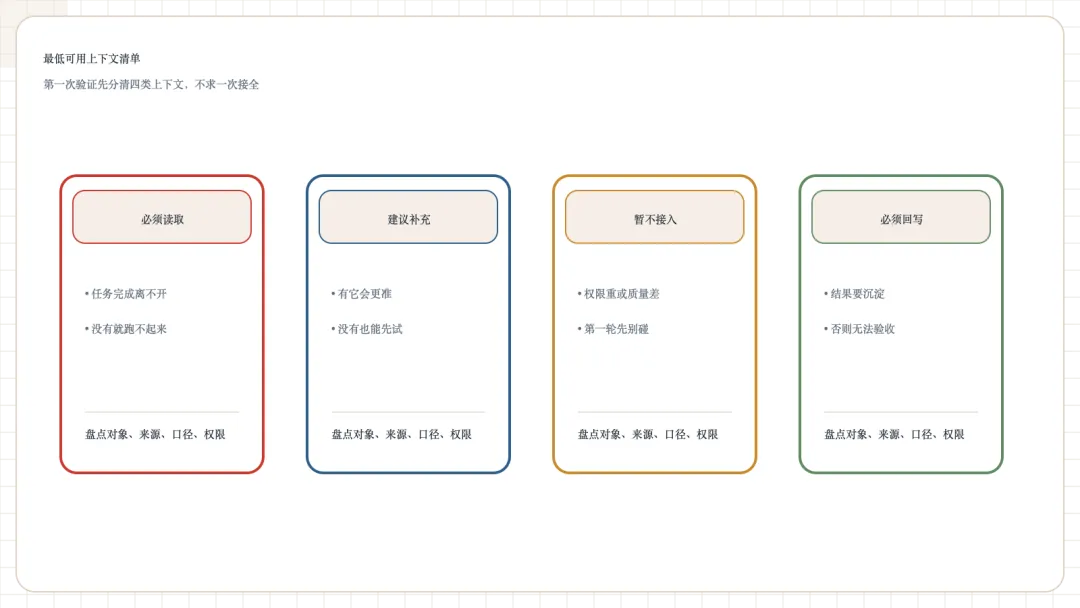
第三组问题,不追求数据完美,只追求最低可用。
很多项目在这一关不是卡死,而是卡悬空。大家都知道需要 CRM、工单、知识库、审批流,甚至提到要接企业微信、ERP、会议纪要,但没人能说清:第一次验证到底非接不可的是哪几项,哪些可以先不碰,哪些数据只能读不能写。
这里更建议企业做一个“最低可用上下文清单”,分成四列:
•必须读取:没有它,任务根本无法完成。
•建议补充:有它会更准,没有也能先跑。
•暂不接入:权限太重、质量太差、第一轮没必要。
•必须回写:否则结果没法沉淀,也无法验收。
比如销售拜访纪要辅助,第一轮也许只要客户基本信息、最近三次互动、产品规则和 CRM 回写入口;价格政策、合同条款、返利例外就不一定适合首轮接入。
第四组问题,核心不是合规口号,而是谁真的负责。
AI 项目最容易出现的一种假象,是大家都参与了,但没有人对结果负责。业务说这是技术工具,技术说这是业务规则,最后一线用户成了默认兜底人。这样的项目即使上线,也很难持续用起来。
所以评估时要把三类责任拆开:
•业务 owner:定义为什么做、什么结果算有效、哪些例外必须人工判断。
•系统 owner:负责接口稳定、日志、权限、回写和异常处理。
•使用 owner:负责真实使用反馈,告诉团队哪些建议被采纳、哪些反而增加负担。
然后再问四个风险问题:
•这个动作出错后,后果能不能恢复。
•哪些输出只能建议,不能自动执行。
•需要人工确认的节点是不是写清楚了。
•出现异常时,升级给谁,多久处理。
这一点也和外部调研结论一致。麦肯锡在 2025 年调查里提到,真正拿到更高价值的企业,更可能去重构流程,也更可能提前定义哪些地方必须做人类校验。落到企业项目里,可以翻成一句很朴素的话:先让 AI 做建议、摘要、初筛、整理这些可回退动作,把直接影响价格、合同、审批、客户承诺的步骤放在人工确认之后。这样既能看到真实价值,也不至于把第一轮验证做成高风险实验。
第五组问题,决定这是不是一个能停、能过、能继续的项目。
IBM 在 2024 年底的一项企业调研里给过一个很有参考价值的信号:58% 的受访公司表示,自己通常能在一年内把 AI 试点推进到正式生产;但同一份调研也显示,企业衡量 AI 的方式并不只是硬 ROI,排在前面的还有更快的软件开发、更快的创新和生产率节省。这个信号很重要,因为它说明企业不是不能往前走,而是要先定义“我们到底拿什么判断这个试点值不值得继续”。
更务实的做法,是在开始前就写三张小表:
•基线表:现在人工怎么做,平均耗时多久,错误主要出现在哪。
•试点表:连续 2 到 4 周,谁来用,样本量多大,记录哪些证据。
•决策表:达到什么条件进入下一轮,什么情况应该暂停或重做。
第一次试点不需要追求“省了多少人”这种大结果,更适合看三类小证据:
•时间证据:处理同类任务是否更快。
•采纳证据:AI 产出有多少能被直接使用或少量修改后使用。
•流程证据:结果有没有顺利写回原流程,团队有没有连续使用。
第一轮不是为了证明 AI 改造了公司,而是为了证明这个场景值得进入下一轮。
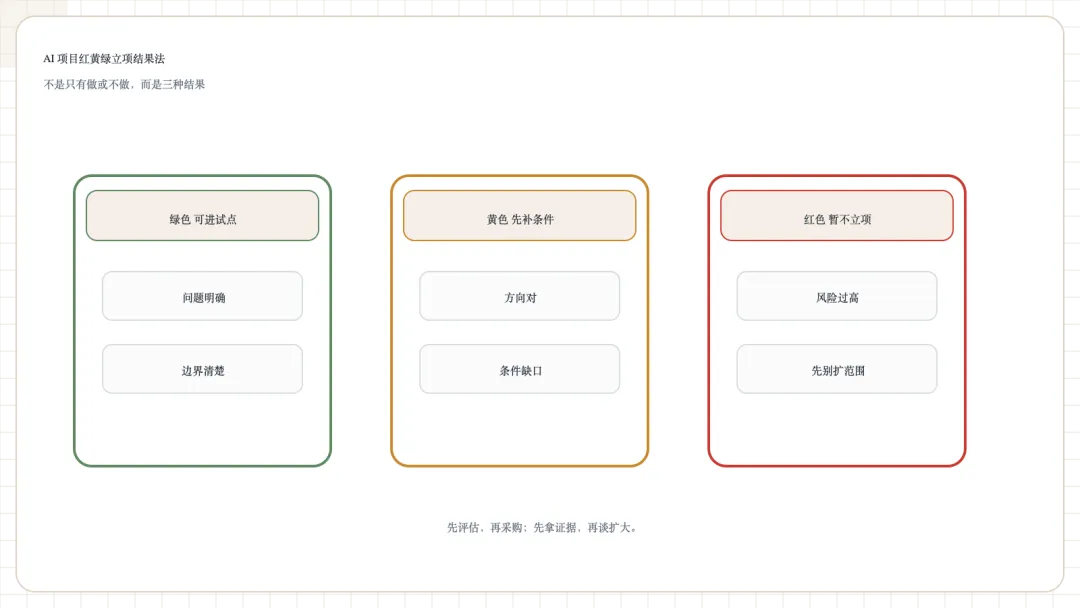
如果要让这张清单真正能拿去用,我建议不要写成讨论材料,而是直接做成一个立项门槛表。
最简单的用法,就是五组问题各给一个结果:
•绿色:问题明确,边界清楚,可以进试点设计。
•黄色:方向对,但缺关键条件,要先补材料再立项。
•红色:暂时不适合做,继续推进只会扩大范围。
一个项目什么时候该先按下暂停键?我会重点看这五种情况:
•业务问题说不成一个具体动作。
•流程边界收不住,总想一步覆盖多个部门。
•关键数据拿不到,或没人能确认口径。
•风险节点没人兜底,默认靠一线用户补锅。
•没有基线,也没有 2 到 4 周的验证计划。
如果你希望这套东西更容易直接用,我建议再往下压一层,做成一张 10 分评估卡。每一组问题只打 0、1、2 三档:

•业务问题:2 分 是已经对应到一个高频动作和一个明确指标;1 分 是知道痛点,但还没有清楚动作;0 分 是只有“我们也想做 AI”。
•流程边界:2 分 是已经能说清输入、输出、转人工节点;1 分 是知道流程大概在哪,但边界还混;0 分 是按部门或大场景在说。
•数据系统:2 分 是必须读取、暂不接入、必须回写都能列出来;1 分 是知道要接哪些系统,但口径和权限还没确认;0 分 是连关键数据在哪都不确定。
•责任兜底:2 分 是业务 owner、系统 owner、人工兜底都明确;1 分 是有人负责,但异常处理没写清;0 分 是默认谁都能管,也等于谁都不管。
•验收扩展:2 分 是已有基线、试点周期和继续/暂停条件;1 分 是有想看的指标,但没有阈值;0 分 是先做出来再说。
这张卡怎么用也很简单:
•8 到 10 分:可以进试点设计,但范围仍要收窄。
•5 到 7 分:先补条件,不急着立项。
•0 到 4 分:先回到业务定义阶段,不建议直接启动。
这样做的好处是,企业内部不需要每次从头争论“这事值不值得做”,而是能先用一张简化工具把分歧压到台面上。
在真正投入预算、选平台、找供应商之前,企业先问自己五件事:
•这是一个值得做的业务问题吗。
•它到底进入哪个动作,而不是哪个宏大部门。
•第一次验证的最低可用数据和系统条件是什么。
•谁负责规则,谁负责系统,谁负责使用反馈。
•什么证据出现了,项目才算值得继续。
如果这五组问题大部分都答不上来,最好的动作不是马上做 Demo,而是先把项目打回到业务定义阶段。如果这五组问题已经答得比较清楚,那企业做的就不只是一个试点,而是在建立一套以后还能复用的 AI 项目评估能力。
这套能力,比第一次选中了哪个模型,往往更值钱。
