 夜雨聆风
夜雨聆风你有没有遇过这种情况:用 Claude Code 做了一个下午的代码调试,让 AI 查日志、搜代码、分析报错,结束时一看账单——287 美元。
这不是你 prompt 写太长,也不是 AI 「变贵了」。问题出在那些工具返回的内容上。MCP 工具查数据库,返回 500 行数据,你只需要其中的 3 行;查日志,返回 1000 行条目,报错的那条只有 2 行。但大模型是按 token 收费的——不管传进来的是精华还是噪音,照单全收。
一个 50KB 的 API 响应,有用的信息可能只有 200 字节。信息密度极低,但钱是按字数付的。你花的钱,90% 在买噪音。
Headroom 就是来解决这个问题的。它不是让你「写更短的 prompt」,而是在信息到达大模型之前先做一次提纯。

token 节省 92%
装好只需一分钟
最省心的方式是用 Docker 一键安装:
curl -fsSL https://raw.githubusercontent.com/chopratejas/headroom/main/scripts/install.sh | bash如果你用 Python,一行 pip:
pip install 「headroom-ai[all]」装完跑 headroom --version 看到版本号,说明成了。
第一个操作:包装你的 AI 编码工具
安装好后,最直接的用法就一个命令:
headroom wrap claude这行命令会在后台启动一个代理,然后把 Claude Code 的 API 请求自动指向 Headroom。你不需要改任何代码,使用习惯完全不变。
想知道省了多少?跑一下:
headroom stats根据官方 benchmark,代码搜索场景 token 节省 92%——17,765 tokens 压缩到 1,408。实时查看你的节省比例,比读任何宣传文章都有说服力。
三个递进任务,从入门到精通
任务一:基础——包装你的编码工具
适合:第一次上手。
操作:headroom wrap claude 或 headroom wrap cursor 或 headroom wrap codex。支持的 AI 编程工具全覆盖。
关键要点:包装前先完全退出目标工具,然后重新启动。如果正在运行的旧实例没退出,包装模式会连接失败。如果你用 Windows 的 PowerShell,wrap 命令可能需要额外配置环境变量——查官方文档的 proxy 配置章节。
任务二:进阶——在 Python 代码里精准控制压缩
适合:在用 LangChain 做 RAG 应用,或在代码中需要精细控制压缩粒度的场景。
from headroom import compress result = compress( messages, model=「claude-opus-4-20250514」, compress_user_messages=True, target_ratio=0.5 # 压缩到原来的一半 ) # result.messages 就是压缩后的内容,直接发给 LLM加一行代码就能在发请求前压缩上下文。你还可以通过 target_ratio 参数精确控制压缩比例。
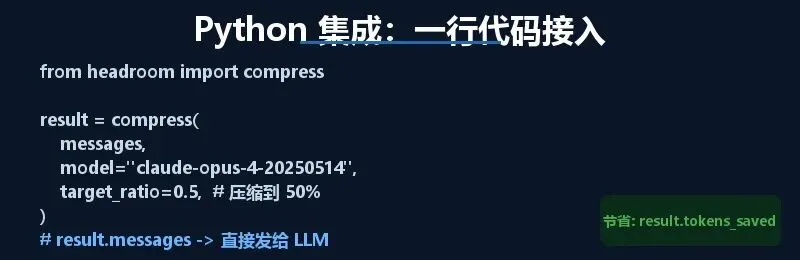
compress() 函数示例
有一个细节需要注意:target_ratio 更像一个「建议值」,不是硬性目标。不同的内容类型(JSON、代码、自然语言)会被不同的压缩器处理,最终的实际比例是整体平均,取决于你的具体内容分布。
任务三:高阶——用 MCP Server 让多个 AI 工具共享压缩记忆
适合:同时用 Claude Code 和 Cursor 做同一个项目,两边各自读文件、建索引,token 重复浪费。
启动 Headroom 的 MCP Server:
headroom mcp运行后会暴露三个 MCP 工具:headroom_compress(压缩内容)、headroom_retrieve(取回原文)、headroom_stats(查看统计)。在 Claude Code 和 Cursor 里分别配置指向同一个 MCP 地址,两个工具就能共享一份被压缩过的项目记忆。
再配合 headroom learn 命令,让 Headroom 从一个会话里学习关键信息,另一个工具的 AI 可以直接调用共享记忆,不用重新读一遍全量文件。
它跟其他工具怎么选?
和 LLMLingua 的区别:LLMLingua 的目标是「压得越狠越好」,不惜牺牲准确性;Headroom 的设计首要目标是「准确率不变」。在 BFCL 基准测试中,LLMLingua-2 压缩 JSON 时准确率掉了 20% 以上,而 Headroom 保持在基线附近(-3% 以内)。你要的是「狠压但可能出错」,还是「稳健压且尽量不出错」?
和 Prompt Caching 的关系:两者是正交的,甚至可以叠加使用。Headroom 的 CacheAligner 组件专门做了一件事——稳定化请求前缀,让 prompt caching 的命中率更高。用 Headroom 不影响 caching,反而能帮它更好地工作。
黄金三件套:Headroom + RTK + MemStack

RTK + Headroom + MemStack 三层压缩
据社区讨论和官方推荐,最经典的组合是这三个工具各司其职:
- RTK
:压缩终端输出(在你看到它之前) - Headroom
:压缩整个上下文(在请求发往 LLM API 的路上) - MemStack
:管理跨会话的项目记忆(避免重复读同样的内容)
RTK 先把终端输出压一压,这些输出进入 Headroom 再压一遍,三个工具叠在一起,那个累积的 token 节省效果才是真正的「账单杀手」。如果有人觉得分别配置这三个太麻烦,还有个叫 Whetstone 的工具,一条 whetstone setup 命令同时装好配好。
三个最容易踩的坑
坑一:包装模式启动慢,有时候「空转」。headroom wrap claude 跑起来后 Claude Code 启动慢了十几秒,而且有时候压缩完全没生效。老手的绕法:直接用 headroom proxy --port 8787 模式,手动配置 Claude Code 的 base URL,代理日志一目了然,心里有底得多。
坑二:CCR 可逆压缩「看起来很美」。 Headroom 的理念是压缩时不丢东西,生成一个短的摘要版放进上下文,模型需要时可以主动调用 headroom_retrieve 取回原文。问题在于——大模型没有「自我意识」,不会主动觉得自己「缺信息」。如果几百行日志被压缩成几条摘要,模型看到摘要就直接回答了,它可能完全不知道原文里还藏着另外两种模式的错误。把 CCR 当「容灾工具」而不是「核心功能」。 依然相信第一次压缩的结果,CCR 是兜底用的。
坑三:Python 版本坑。 Headroom 核心要求 Python >= 3.10,某些扩展在 3.9 以下跑不起来。老手建议:用 Docker 版本,完全绕过 Python 环境问题。
工具选对了,一顿午饭钱可能就是你一个月的 API 账单。
Headroom 只做一件事——压缩「发给 LLM 的内容」,但它把这一件事做得足够好。下次你看到 Claude Code 的账单时,别只心疼钱,花 5 分钟试试 Headroom,先从 headroom wrap claude 开始。
