 夜雨聆风
夜雨聆风最近我越来越明显地感觉到一件事:
程序员用 AI 以后,最该补的不是提示词能力,而是调度能力。
这句话不是说 prompt 不重要。
prompt 当然重要。你要把目标、约束、上下文说清楚,Agent 才知道往哪走。
但当 AI 编程工具开始能读仓库、改文件、跑命令、开 PR、接 MCP、调用外部工具,问题就变了。
以前你面对的是一个聊天框。
现在你面对的是一组会动手的 Agent。
一个复杂任务如果还全部塞进同一个长会话,前半段它在理解需求,中段它在改代码,后段它又开始自我修复、跑测试、补文档、解释 diff。
看起来很顺。
最后你打开改动,发现自己真正要做的不是“接受 AI 结果”,而是重新搞清楚:
- 它到底改了哪些文件。
- 哪些改动是任务需要的。
- 哪些改动是顺手扩出来的。
- 哪些测试真的跑过。
- 哪些风险还得人来兜底。
这时候,问题已经不是“AI 会不会写代码”。
问题是:你会不会调度它。
多 Agent 不是多开几个窗口
很多人听到多 Agent,第一反应是同时开几个模型窗口。
一个查资料,一个写代码,一个审查,一个写文档。
这只是表面。
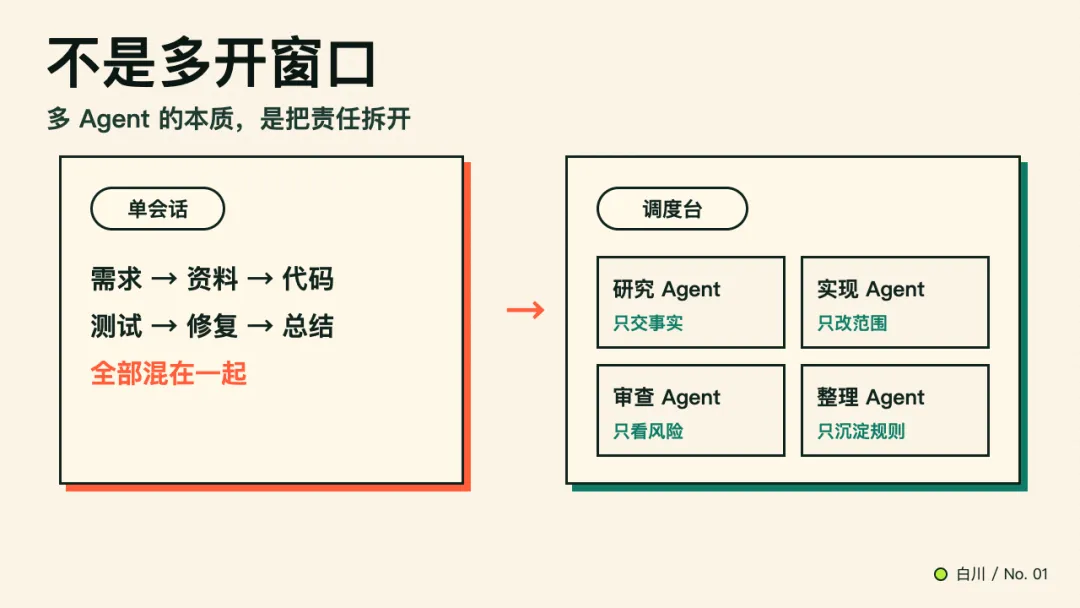
真正的多 Agent 工作流,不是数量变多,而是责任被拆开。
单 Agent 长会话里,所有事情混在一起:
理解需求 -> 找资料 -> 改代码 -> 跑测试 -> 修失败 -> 写总结 -> 等人验收多 Agent 调度要做的,是把这条长链拆成几个可交接的任务单:
研究 Agent:只负责查清事实和方案,不改代码实现 Agent:只负责按任务卡改指定范围审查 Agent:只负责看 diff、风险和测试,不继续扩需求整理 Agent:只负责把结果沉淀成文档或规则差别不在“几个 Agent”。
差别在每个 Agent 有没有自己的输入、边界、交付物和验收方式。
没有这些东西,多 Agent 只是多几个聊天窗口同时制造上下文。
有了这些东西,它才像一个调度台。
工具形态已经在往这里走
这不是我凭空想出来的趋势。
GitHub Copilot 的官方文档里,Agent 已经不是单独一个功能点。你能看到 cloud agent、agent management、custom agents、automations、MCP、risks and mitigations、hooks、third-party coding agents、OpenAI Codex、Anthropic Claude、agent skills 这些栏目放在同一套体系里。
到了 Copilot CLI 和 Copilot SDK,文档里还会出现 parallel task execution、session data、custom agents、hooks、MCP、remote sessions、skills、steering and queueing 这类词。
这些词背后,其实都是同一件事:
AI 编程正在从“单次对话生成代码”,转向“多个可管理会话围绕任务推进”。
OpenAI 近期关于 Codex 的公开叙事,也在不断从“写代码”扩展到“不同角色、不同工具、不同工作流”。我这里不把它写成具体教程,因为官网细节还需要按当前页面再核验,但方向已经很清楚:AI 编程工具竞争的重点,正在从单次生成能力,转向工作流融合能力。
这对程序员意味着什么?
不是你马上要搭一个复杂平台。
而是你得先学会一件更朴素的事:把任务拆到 Agent 可以接、你也能验收的颗粒度。
用写作做个例子
用公众号 AI 写作举例。
它不是传统业务系统,但结构很像一个 Agent 工程项目:有输入源,有状态流转,有不同角色,有审查闸门,也有发布风险。
把公众号生产拆成了这些阶段:
热点选题 -> 确认选题和标题 -> 大纲 -> 文章创作 -> 审稿 -> 生图 -> 排版 -> 发布每个阶段都有自己的子 Agent、Skill、输入和输出。
热点调研不直接写正文。
标题阶段不扩写文章。
没有大纲,不进入完整正文。
没有审稿通过,不进入排版和发布。
没有用户明确确认,不上传草稿箱。
你看,这就是调度。
它的本质不是“让 AI 更自由”,而是让 AI 在每一步只做该做的事。
如果把这套结构换成一个代码项目,也差不多:
需求澄清 -> 技术方案 -> 实现 -> 测试 -> 代码审查 -> 文档更新 -> 合并发布很多人用 AI 编程出问题,不是因为没有 Agent。
而是因为所有阶段都被塞进了一个会话。
调度能力先从一张任务卡开始
多 Agent 工作流最小的单位,不是 Agent。
是任务卡。
一个 Agent 能不能被调度,取决于你有没有把任务写成它能接、别人能验收的形式。
我会用这张表:
举个例子。
如果我要让 Agent 修改这篇文章对应的工作流,不会这么交代:
帮我把这篇文章写好。这句话太大。
它可以调研,可以起标题,可以改正文,可以生成图片,可以排版,甚至可能试图发布。
我会拆成几张卡。
## 任务卡:研究 Agent任务目标:核对多 Agent 编程工作台的公开事实,只输出事实边界和来源,不进入实现。允许范围:- 读取需求卡、issue、现有代码和官方文档链接。- 联网核验 GitHub Copilot agent 文档和 OpenAI / Codex 公开页面。禁止范围:- 不修改业务代码。- 不改任务状态。- 不把媒体转述写成官方事实。交付物:- 已核验事实、合理判断和不能下结论的风险点。- 可以进入正文的 3 条事实。- 不能写成结论的风险点。验收方式:- 每条事实必须有来源。- 证据不足的内容不能写成确定结论。再给实现 Agent 一张卡:
## 任务卡:写作 Agent任务目标:基于已通过的大纲,写一篇可发布初稿。允许范围:- 读取需求说明、设计文档、项目规则和相关代码。- 创建或修改任务允许范围内的文件。禁止范围:- 不新增未经核验的产品能力。- 不伪造亲测、读者反馈、后台数据。- 不跳过审查直接合并或发布。交付物:- 可审查的改动结果。- 改动文件列表和验证结果。验收方式:- 任务目标被完整覆盖。- 至少包含 diff、验证命令、未覆盖风险三类信息。你会发现,任务卡写清楚以后,Agent 反而更好用。
因为它不用猜“我要做到什么程度”。
人也不用在最后猜“它到底有没有越界”。

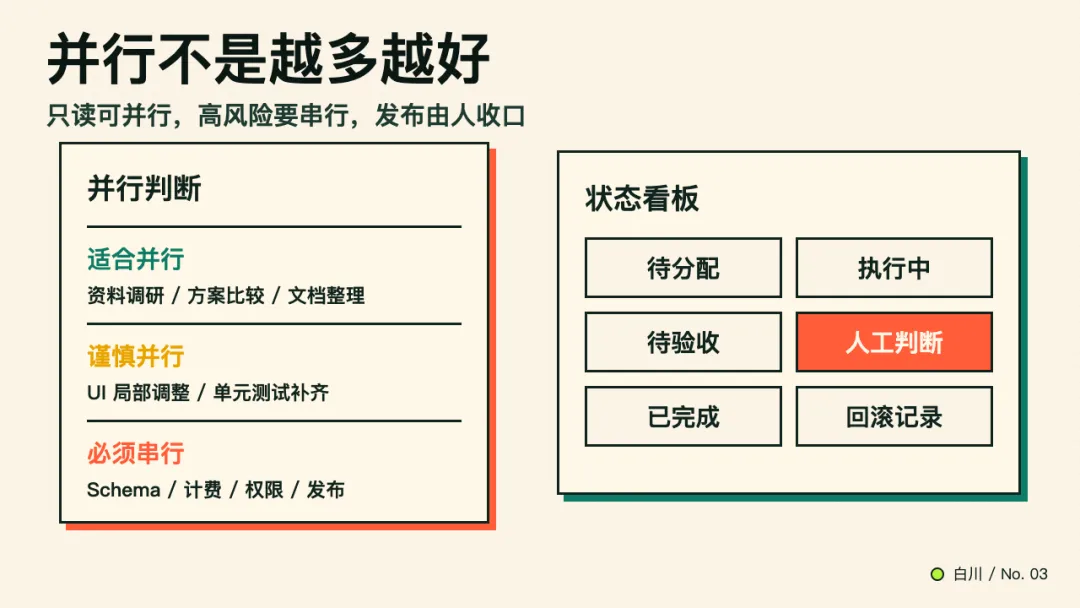
哪些任务适合并行,哪些必须串行
调度不是把任务全部并行。
并行越多,最后合并越难。
我会先用这张表判断:
这张表背后的规则很简单:
只读任务更适合并行。
写入同一片代码的任务要谨慎。
会改变状态机、数据结构、计费、安全、发布的任务,必须串行,而且要有人收口。
拿这个写作工作台来说,热点调研和视觉风格参考可以并行。
但目标定义和实现步骤不能乱序。
审稿没过,排版就不能进入。
用户没确认,草稿箱就不能上传。
换成代码项目也一样。
需求没定,别让 Agent 直接重构。
schema 没确认,别让两个 Agent 同时改迁移。
测试没跑过,别让它自动合并。
调度台要看状态,不只看结果
很多人用 AI 编程,只看最后输出。
这不够。
只看结果,你只能知道它交了什么。
看状态,你才知道任务卡现在卡在哪里。
最小的 Agent 工作台,不需要复杂系统。一个 Markdown 表格就够:
这个看板的价值,不是管理感。
它能防止一个常见问题:Agent 把不确定性藏在最终答案里。
比如它说“已完成修改并通过测试”。
你要继续追:
- 跑了哪个测试。
- 测试覆盖的是哪个行为。
- 有没有没跑的检查。
- 有没有跳过的风险。
- 有没有改到任务卡之外的文件。
所以我更喜欢让 Agent 最后按这个格式交付:
## 交付摘要- 完成了什么:- 修改了哪些文件:- 没有修改哪些高风险区域:- 运行了哪些验证:- 验证结果:- 未覆盖风险:- 需要人工确认:这不是形式主义。
这是把“AI 说它完成了”变成“人能判断它是否完成”。
人类不是退出,而是换了位置
多 Agent 工作流最容易被误解的一点,是以为人会越来越少参与。
我的感觉正好相反。
在复杂任务里,人不是退出,而是从执行者变成调度者和验收者。
以前你自己写代码,问题出在手速、经验和注意力。
现在 Agent 帮你写,问题会转移到任务边界、上下文选择、并行冲突、验收标准和最终责任。
这也是为什么我说,程序员最该补的是调度能力。
调度能力至少包括四件事:
- 拆任务:把大任务拆成可交接的小任务。
- 派角色:决定哪个 Agent 只读、哪个 Agent 可改、哪个 Agent 只审查。
- 看状态:知道任务现在是执行中、待验收,还是需要人工判断。
- 做收口:最后由人决定是否合并、发布、回滚、沉淀规则。
这四件事听起来不像写代码。
但它会越来越像真实开发的一部分。
因为 AI 编程越自动,越需要有人定义“自动到哪里停”。
今天可以怎么开始
不用等一个完美的多 Agent 平台。
今天就可以从一个复杂任务开始。
找一个你原本想丢给 AI 的任务,不要直接发一句“帮我做完”。
先拆成三张卡:
资料卡:只查资料和现有代码,不修改。实现卡:只改指定范围,必须列出 diff 和验证。审查卡:只审查实现结果,不继续扩需求。然后给每张卡写清楚:
目标输入允许范围禁止范围交付物验收方式停止条件如果这一步你都写不清,说明任务还不该交给 Agent。
不是 Agent 不够强。
是你还没有把工作拆成可以被代理执行的形状。
这也是我最近越来越确定的判断:
AI 编程的下一步,不是让 prompt 变得更长。
而是让任务变得更可调度。
程序员真正要练的,也不只是怎么让 AI 写代码。
而是怎么让一组 Agent 在正确的边界里做事,最后还能被人验收。
