 夜雨聆风
夜雨聆风想象一下这个极度让人血压飙升的场景:
你正在用某个大模型写一份至关重要的年终总结报告。 你语重心长地铺垫:“小A啊,这次的项目背景是关于新能源汽车下乡的,我们的目标受众主要是三线城市的年轻家庭用户,预算控制在10万以内。” AI信誓旦旦:“好的老板!我都牢牢记在心里了,保证完成任务!”
(半小时过去了,你们经历了几轮修改,讨论了营销渠道、海报设计……)
你终于松了一口气:“好了,万事俱备,现在根据我们刚才讨论的,帮我写个铿锵有力的总结段落吧。” AI自信满满地输出:“综上所述,我们在推广高端奢华跑车时,应该更加注重北上广深一线城市的高净值人群,突出车辆的极致百公里加速性能……” 你看着屏幕,满头问号:“???我刚才说的新能源汽车下乡呢?!那10万以内的预算呢?!你难道只有七秒钟的鱼的记忆吗?!!”
是不是有一种似曾相识的崩溃感?这几乎是每个重度AI用户的日常“劫难”。
我们最初满心欢喜,以为拥有了一个全知全能的贴身超级秘书。结果真正用起来才发现,它常常表现得像个健忘的老大爷,或者注意力极易分散的小孩。刚交代清楚的前提条件,转头就忘得一干二净。为了让它保持在正轨上,你需要一遍又一遍地在Prompt(提示词)里反复强调前情提要,最终的沟通成本甚至比你自己动手写还要高!
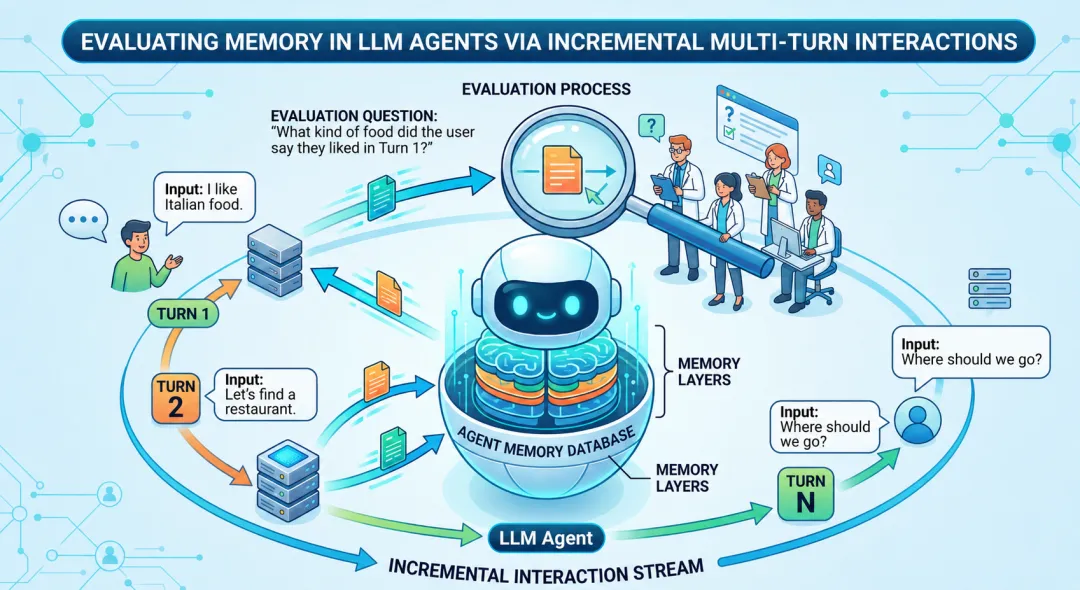
为什么现在的AI,明明号称算力滔天,却常常表现得像只有“七秒记忆”?
别急着摔键盘,不只是你发现了这个让人抓狂的问题,全球顶级的学术圈大佬们也看不下去了。
今天,我们就来硬核科普一下近期学术界的一篇重磅论文:《Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions》(通过增量式多轮交互评估LLM Agent的记忆力)。
在这篇论文中,大佬们不仅像老中医一样精准把脉,指出了AI“失忆”的真正病因,还为这些大模型量身定制了一套严苛的“记忆力体检方案”。
传统测试的骗局:为什么测不出AI的真实记忆力?
在了解新方案之前,我们先来看看过去是怎么糊弄事的。在此之前,人们怎么测试AI的记忆力呢?通常采用的是简单粗暴的“填鸭式”或者叫“大海捞针”式测试。
就像考前突击的学渣一样,测试人员把一大堆资料(比如一整本几十万字的英文原版小说,或者长长的财务报表)一次性全部塞进AI的对话框里,然后像老师抽查一样问它:“第58页第三段,主人公喝的是什么咖啡?”
如果AI准确答出了“卡布奇诺”,大家就欢呼雀跃:“哇塞!这个AI的上下文窗口好长啊!几十万字都能记住,记忆力天下第一!”
但这真的靠谱吗?这真的能反映AI在你日常工作中的表现吗?
显然不能!试想一下,你在真实的工作生活中,是怎么和你的真实人类助理交流的?你绝对不会在入职第一天,就一次性扔给他一本10万字的《工作指南》让他背熟。
你们的交流是在每天的琐碎沟通中进行的,信息是一点一点补充的: 上午:“对了,下午那个会议加上这组最新的销售数据。” 中午:“小王,昨天那个重要客户的对接人换了,电话记一下,改成了138xxxx……” 下午:“之前说的那个线下活动因为天气原因取消了,立刻启动Plan B。”
在学术上,这种交流方式被称为多轮交互 (Multi-Turn Interactions)。在这种场景下,信息呈现出三个极其要命的特点:碎片化、增量式出现,而且最关键的是,还会随时更新和反转。
传统的那种“一次性塞入全量静态信息”的测试方法,就像是在温室里测跑步,根本无法模拟我们真实、复杂甚至混乱的对话场景。这也就是为什么,很多厂商吹嘘自家AI支持“百万上下文”,你在做简单的阅读理解时觉得它很神,但在真实的连续对话拉扯中,它依然会常常“断片”,甚至胡言乱语。
新框架登场:大佬们如何“严刑拷打”AI的真实记忆力?
为了戳破“百万上下文”的虚假繁荣,解决这个实际应用中的痛点,论文的作者们提出了一套全新的、极其刁钻的评估框架。简单来说,就是用更接近真实人类沟通、甚至更恶劣的环境去“拷打”AI。
这个新框架有三个非常硬核的测试维度,堪称AI记忆力的“照妖镜”:
1. 模拟真实聊天:把关键线索藏在漫长的对话里不再是一次性给全资料。测试像是一场漫长的闲聊,在十几次甚至几十次对话中,把关键信息拆散了、揉碎了喂给AI。比如,第一轮不经意地说“主角的宠物是一只猫”;到了第七轮,顺嘴提一句“那只猫叫咪咪”;等到第十五轮,突然冷不丁地问:“主角的宠物叫什么名字?”这极其考验AI跨越超长多轮对话,提取并整合碎片化信息的能力。很多AI在第十五轮时,早就忘了第一轮在聊什么了。
2. 考验动态更新能力:旧记忆必须能被覆盖这是最贴近真实工作、也是AI最容易翻车的一环。真实世界的情况是随时变化的。如果我在第一轮明确告诉AI:“这周的周会定在周二下午两点”。然后在第四轮告诉它:“哦对了,老板周二出差,周会推迟到了周三上午十点”。新测试不仅要求AI能记住信息,还要能极其精准地识别出冲突,并用新信息覆盖旧记忆。事实证明,很多AI“死脑筋”,认死理,它们会将新旧信息混淆,或者依然顽固地坚持最初的“周二下午两点”,很难被纠正。
3. 终极抗干扰测试:废话、噪音与恶意误导现实沟通中往往充满了无关紧要的废话。在这个测试环节,研究人员会在对话中故意掺杂大量无关紧要的水分,甚至是似是而非的误导性信息。比如在聊项目的过程中,突然穿插几句中午吃了什么、天气怎么样的闲聊。看AI能不能像一个老练的职场精英一样,自动过滤掉这些“噪音”,在乱花渐欲迷人眼的对话中,依然精准提取出有价值的核心指令。
这项研究的出现,相当于一锤定音,给整个AI行业的记忆力评估定下了一个极其严苛的新标准:未来的AI,不仅要记得多(大容量),还要记得准(能更新),更要在与人类漫长而随意的对话拉扯中,始终保持清醒(抗干扰)。
对普通打工人来说,懂这个有什么用?
你可能会问,懂了这篇高深的论文,除了能出去跟不懂行的朋友吹吹牛,对我们实际“调教”AI有什么实质性的帮助呢?
帮助太大了!它能彻底改变你使用AI的习惯:
第一,彻底放下不切实际的幻想,接受它还是个“半成品”。现阶段,请认清现实:即便是目前市面上最顶级的模型(比如GPT-4等),在经历超长、复杂的多轮对话后,其记忆力依然会不可避免地衰退。不要指望它能像神一样永远记住你第一句话说过的每一个字。核心策略:重要的事情,请在让它生成最终关键内容之前,务必再次、甚至三次重复强调前提条件!(这是目前高级Prompt师的核心保命技巧之一)。
第二,用“照妖镜”挑选真正好用的AI工具。未来,面对那些只吹嘘自己能“一秒读完几百万字”的AI,你可以一笑而过了。真正决定一个AI在日常工作中是否好用的,是它在真实交互中是否拥有“长且准、能动态更新的记忆力”。能够顺畅处理复杂多轮对话、不轻易失忆的AI Agent,才是未来真正的王者。这套新评估标准,就是你挑选工具的指南针。
第三,满怀期待地迎接更懂你的“数字生命”。这篇论文的出现是一个极其明确的信号:学术界和各大AI厂商都已经意识到了这个问题,并开始死磕“记忆机制”(比如引入更先进的Memory Bank机制、向量数据库检索等)。我们可以充满期待,在不久的将来,你的AI助理能真正拥有长期记忆,记住你的写作喜好、你的口语习惯、你未竟的工作进度,真正进化成一个永远在线、永不失忆的超级数字帮手。
