AI重构数仓:不是加个模型就完事了文/华哥聊数据 | 十年磨一剑的大数据老兵,个人微信ID:bba80108
做了多年的兄弟,你有没有这种感觉:每天写的ETL脚本越来越长,调度的任务越来越慢,业务那边催报表催得越来越凶,手里维护的表已经上千张,连自己都说不清哪张还能删。
这不是你一个人的问题。整个数仓行业都在经历一场阵痛,传统数仓架构,已经扛不住现在的数据规模和业务节奏了。数据量从TB级跃升到PB甚至EB级,数据源从结构化扩展到半结构化和非结构化,业务对时效性的要求从"隔天看报表"变成了"秒级响应"。传统数仓最初是为"批处理+定期报表"设计的,而今天的业务需要的是"实时+自助+智能"的数据服务能力。数据孤岛、ETL瓶颈、时效性不足、扩展性受限、治理能力薄弱——这些结构性矛盾,正在推动AI与数仓的深度融合。
数仓的四次架构大换血
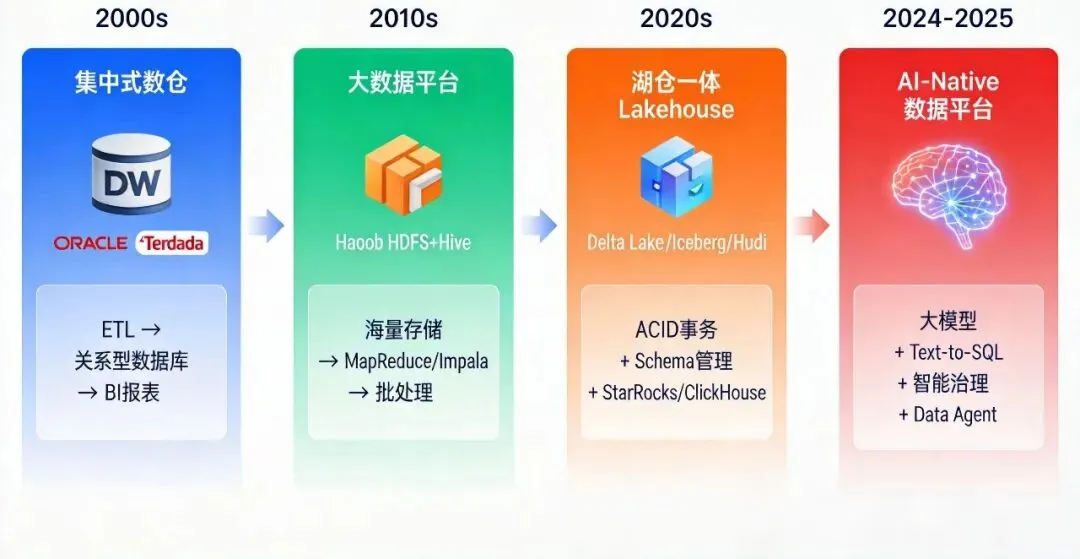
把时间线拉长看,数仓其实已经换了四次代。
2000年前后,Oracle Exadata、Teradata一统天下,ETL到中央仓库、BI出报表,标准化程度高但扩展成本贵得离谱,非结构化数据完全没法处理。2010年,Hadoop HDFS+Hive让海量数据存得下、成本低下来,但Hive跑MapReduce慢得怀疑人生,"管得好"和"查得快"没着落。2020年,湖仓一体来了,Delta Lake、Iceberg、Hudi在数据湖低成本之上补上了ACID事务和Schema管理,StarRocks、ClickHouse把查询速度拉满。
而现在正在发生的第四次演进,才是真正颠覆性的,AI-Native Data Platform。大模型不再只是上层分析工具,它下沉到了数据摄入、转换、存储、治理、服务的每一个环节。Databricks推出Data Intelligence Platform,把大模型嵌进数据管道每个环节;Snowflake在数据云里集成了Cortex AI,提供原生ML和LLM推理能力;阿里云MaxCompute升级为SaaS化智能云数仓,内置智能调优诊断。这不是功能叠加,是数据架构的一次范式转换。
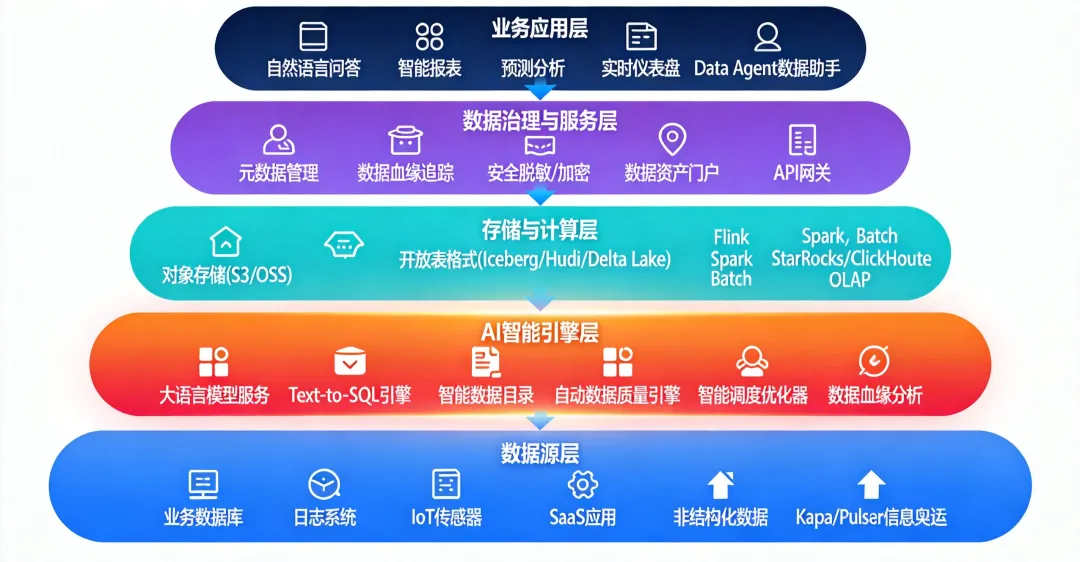
新的架构从底向上分五层:数据源层(业务库、日志、IoT流、SaaS数据、非结构化数据通过Kafka等消息队列摄入)-> 存储与计算层(对象存储做底座,开放表格式提供ACID能力,Flink负责实时流处理,Spark负责批量,StarRocks/ClickHouse负责OLAP)-> AI智能引擎层(大模型服务、Text-to-SQL、智能数据目录、自动数据质量引擎、智能调度优化器)-> 数据治理与服务层(统一元数据管理、血缘追踪、安全脱敏、API网关)-> 业务应用层(自然语言问答、智能报表、预测分析、Data Agent助手)。
AI重构数仓的五大核心能力
能力一:智能数据管道。传统ETL靠人工写逻辑、配调度、处理告警,一旦上游数据结构变更下游就牵一发动全身。AI赋能后,大模型能根据上游Schema和下游分析需求自动生成转换脚本,根据历史运行数据识别性能瓶颈并优化执行计划,根据上游变更自动检测影响范围并生成适配方案。简单场景准确率80%以上,但复杂业务逻辑(多表关联、条件聚合、窗口函数嵌套)仍需工程师审核。推荐"AI生成初稿+工程师审核调优"的协作模式。实践提示:简单场景下AI生成ETL脚本准确率可达80%以上,但复杂逻辑仍需工程师审核。不要期望AI完全替代人工,而是把工程师从重复编码中解放出来。 |
能力二:自然语言查询(Text-to-SQL)。这是AI重构数仓最具代表性的能力。业务人员用自然语言提问,系统自动转SQL返回结果。核心挑战不是"生成SQL",而是"准确理解业务语义"。表名消歧(CRM和订单系统中同一字段可能含义不同)、业务口径对齐("活跃用户"各部门定义不同)、复杂查询拆解,每环都是坑。行业里有三种路线:大模型直接生成SQL、基于向量检索的语义匹配、混合路线先检索再生成。实际生产中混合路线准确率和稳定性最好。
关键前提:Text-to-SQL的准确率高度依赖元数据质量。表没注释、字段没描述、没示例数据,大模型根本没法干活。引入之前先把元数据治理做到位。 |
能力三:智能数据治理。数据治理是公认最苦最累的活。AI进来之后能做很多实在的事:自动识别敏感信息(手机号、身份证号、银行卡号)并按安全策略打分类分级标签;自动扫描Schema生成字段级语义描述;基于统计模型检测空值率突增、分布偏移、重复率上升等质量异常,在被消费前发出预警。从"人工检查"变成"AI执行+人工复核"的混合模式。能力四:智能调度与资源优化。上千个调度任务靠人工调优根本搞不过来。AI能根据历史运行数据预测任务耗时,自动调整并行度和资源分配,减少资源浪费和任务排队;还能识别"长期占资源但使用率低"的查询,推荐分区策略调整、索引建议、物化视图方案。能力五:Data Agent,数据交互的新范式。不是简单ChatBot,而是能自主规划、执行多步数据操作的AI Agent。比如用户问"上季度各区域销售额下滑原因",Data Agent能自动定位相关表、写SQL查询、做多维下钻分析、生成可视化图表、输出分析结论。瓴羊Dataphin基于阿里巴巴OneData方法论构建了全链路Data Agent平台,Databricks的AI/BI也在发力。但目前还处早期阶段,复杂场景下可靠性和可控性有较大提升空间。落地三步走,别一上来就全铺开
根据行业实践,建议分三个阶段推进。
第一阶段,夯实数据基座。把分散在各业务系统的数据统一入湖,用对象存储做底座,引入Iceberg或Delta Lake做开放表格式,关键是不丢数据、不改结构。同时建立元数据中心,给核心表补中文注释和业务口径,这是后续所有AI能力发挥作用的前提。计算引擎迁移建议"双写双读"过渡,新老并行验证一致性和性能后再逐步下线老系统。第二阶段,智能化升级。Text-to-SQL选高价值低风险场景先行试点,比如管理层经营分析报表、客服数据查询,基于元数据质量做针对性优化。智能数据质量引擎初期以"监控+告警"为主,别上来就自动阻断,容易搞出业务事故。数据血缘追踪基于Apache Atlas或OpenLineage搭建,为变更影响分析和问题排查提供基础。第三阶段,全面深化。AI驱动数据管道覆盖摄入、转换、调度的全生命周期。Data Agent先内部数据团队试用,验证可靠性后再推广到业务侧。统一数据资产门户整合数据目录、血缘追踪、质量报告和使用分析,让数据资产的"查找、理解、使用"体验明显提升。
加入我们,内部VIP社群知识星球,获取更多数据仓库、AI与大数据内容与干货!
五个必踩的坑,提前知道能省半年
坑一,元数据质量不行就急着上Text-to-SQL。最常见的错误。表名是缩写(t_order_log到底什么意思?)、字段没注释、业务口径没文档,大模型根本理解不了你的数据。优先覆盖Top 20高频查询表,求精不求全。坑二,低估开放表格式的运维复杂度。Iceberg、Delta Lake、Hudi解决了ACID和Schema演进,但快照积累导致存储膨胀、小文件过多拖慢查询,这些坑容易被忽视。要建立定期维护SOP:快照过期清理、Orphan File清理、小文件合并,纳入日常调度。坑三,盲目追"全实时"。一上来就要求所有数据秒级延迟,结果付出巨大复杂度和成本。大部分场景根本不需要真正的实时,日报周报月报T+1延迟完全可以接受,管理层看的是趋势而非秒级变化。按需分级:实时用Flink流处理,近实时用微批,批量用传统批处理。坑四,AI上线后不管了。大模型可能产生幻觉,质量规则需要随业务变化调整。没有持续运营机制,AI能力使用率会断崖下降。要建立反馈闭环:记录用户采纳和修正情况,持续优化Prompt和检索策略;定期回顾质量告警有效性,调整阈值和规则。坑五,安全合规的盲区。自然语言查数据如果权限和脱敏机制不完善,Text-to-SQL可能成为数据泄露通道。企业数据发送到外部大模型API也存在出域风险。必须在内部权限体系内运行,敏感字段查询结果自动脱敏,优先私有化部署方案。再强的AI引擎,也跑在数据的地基上
AI重构数仓不是展望,是正在发生的现实。但不是引入某个大模型就能一蹴而就。需要存储计算架构的现代化改造,需要元数据和治理的扎实积累,需要AI与数据管道的深度融合,更需要数据团队的组织能力跟上技术变革。
建议很朴素:先想清楚业务真正需要什么,从元数据治理和数据基座建设开始,逐步叠加AI能力。不要被营销术语裹挟,一步一步走稳了,比什么都重要。
如果你觉得这篇文章有启发,欢迎点赞 + 在看 + 转发,让更多数据同行看到!
更重要的是——点个关注【华哥聊数据】,追更不迷路!
博主留言:
加入我们,内部VIP社群知识星球,获取更多数据仓库、AI与大数据内容与干货!
我们不止讲概念,更输出可落地的解决方案。
下期见
 夜雨聆风
夜雨聆风