 夜雨聆风
夜雨聆风过去两年里,AI 工具的收费方式越来越复杂了。一开始无非是按用量计费,或者给一个包月的会员制度;现在则出现了 Credits、Token Plan、API 用量、缓存命中价......对于很多非专业人士,这些概念未免过于复杂。本文意在对这些概念进行解释,并试图解答两个问题:为何在互联网时代大行其道的包月制度,在 AI 工具收费领域濒临破产?以及,作为一个普通的用户,我们在 AI 时代应该怎么选择适合自己的订阅方式?
1.概念简介
在讲故事之前,先把几个会反复出现的概念说清楚。
•Token:AI 处理文本的最小单位。一个英文单词大概 1 个 Token,一个中文字大概 1-2 个 Token。你在 ChatGPT 里发一句"今天天气不错",系统会把它拆成 5-8 个 Token,然后逐个处理。所有 AI 工具的计费,最底层都是按 Token 算的。
•API 调用:程序员直接调用 AI 模型的方式。你给服务器发个请求,服务器返回结果,按你用了多少 Token 扣费。OpenAI、DeepSeek、月之暗面的 API 都是这个逻辑:输入多少 Token、输出多少 Token,每百万 Token 多少钱,用多少扣多少。
•Coding Plan:国内几家厂商推出的"包月套餐"。你每月付固定费用,获得一定额度的 AI 编程使用权。这个额度可能按"次数"算(比如 500 次请求),也可能按 Token 量算。特点是"看起来不限量,实际有上限"。
•Token Plan:还是按 Token 扣费,但包装成了订阅套餐。你每月付 ¥39 或 ¥99,系统给你一定额度的 Credits(积分),用一次扣一次。用完了要么充值,要么等下个月。
简单说:Token 是计量单位,API 是调用 AI 模型的通道,Coding Plan 和 Token Plan 是两种"卖你 Token 使用权"的方式。前者像健身房年卡(固定次数),后者像加油卡(按用量扣)。
2.曾经存在过的“套餐”
我第一次用 AI 是 2023 年初,那时候 GitHub Copilot 刚开始支持学生免费。它的功能很简单:你写代码的时候,它在旁边帮你补全几行。注册个学生会员,或者直接按月订阅,基本上可以随便用。
图 1:VS Code Copilot 界面。本质上,我仍然在用一个代码编辑器,只是旁边多了一个可以对话的 AI 助手
那时候大部分人用 AI 都是这样:要么用 ChatGPT 网页版,要么就是 Copilot 这类嵌在编辑器里的补全工具。偶尔有人会去调 API——就是程序员直接调用 OpenAI 或者 DeepSeek 的接口,按用量计费。API 的定价逻辑很直接:输入多少 Token、输出多少 Token,每百万 Token 多少钱,用多少扣多少。 GPT 贵,DeepSeek 便宜,但逻辑都一样。
那时候我自己用得也不多。改改代码、写个文档,顶多一个月几十块钱。我记得有一次用 Maimbot 把 DeepSeek 接入群聊,几个人聊了一晚上,五块钱就没了。当时算了一下,要是用 GPT,我早破产了。
2025 年之后,伴随着 GPT-5、Claude Opus 4.5 等强力模型的发布,Agent 时代到了。AI 编程工具开始分化成两种:
第一种是编辑器里的 AI。 你仍然在代码编辑器里工作,左边是文件,右边是代码,AI 通常在侧边栏或者内嵌窗口里跟你对话。Cursor、GitHub Copilot Chat、通义灵码这类工具,大体都属于这个形态。你写一段代码,AI 给建议;你问个问题,AI 回答一下。这类工具的 Token 消耗可控——一次补全几十到几百个 Token,一次对话几千个 Token,一天用不了多少。
图 2:编辑器增强工具的代表:Cursor。这类工具本质上仍然是代码编辑器,AI 扮演的是"助手"角色。
第二种是对话式 Agent。 你面对的不是一个代码编辑器,而是一个对话窗口或者命令行。你把任务说清楚,它自己去读代码、改文件、跑命令、看报错,再回来告诉你结果。Claude Code 开了这个头,后来的 Codex CLI、OpenCode 也走了这条路。
图 3:Agent 模式的代表:Claude Code。这类工具转向了面向对话的模式,用户和 AI 直接对话,AI 对项目的管理和操作被隐藏在折叠的工具地哦啊用提示里
Agent 模式下,Token 消耗直接爆炸。 AI 每做一件事,都要把整个代码库的上下文加载进来;每次调用工具、每次读文件、每次看报错,都要重新处理一遍上下文。一个任务下来,可能触发几十次模型调用,每次都是几万甚至十几万 Token。编辑器模式一天的消耗,Agent 模式可能十分钟就烧完了。
再然后,龙虾来了。
OpenClaw——国内开发者叫它"龙虾"——是个开源的 AI 助理工具。它跟 Cursor 不一样,不嵌在编辑器里。你可以把它挂在后台,给它一个任务,它自己去干。读代码、写代码、跑测试、改 bug,一轮接一轮,24 小时不停。你早上醒来,它可能已经帮你重构了三个模块。

图 4:OpenClaw 官网页面。它不是"编辑器里多一个聊天框",而是面向普通用户的 Agent 助手:你给任务,它在后台处理邮件、日程、代码或其它工作流。
龙虾火了之后,开发者圈子里出现了一种新的需求:怎么才能便宜地、大量地烧 Token?
于是,Coding Plan 应运而生。国内几家厂商——智谱、阿里云、字节——先后推出了按"次数"计费的包月套餐:你每月付一笔固定费用,获得一定次数的 Agent 操作额度。注意,Coding Plan 是按次数计费的,不是按 Token 用量——GitHub Copilot 的 Agent 模式就是最早的几类工具之一,刚开始一次操作也就是一轮对话,消耗不算太大。
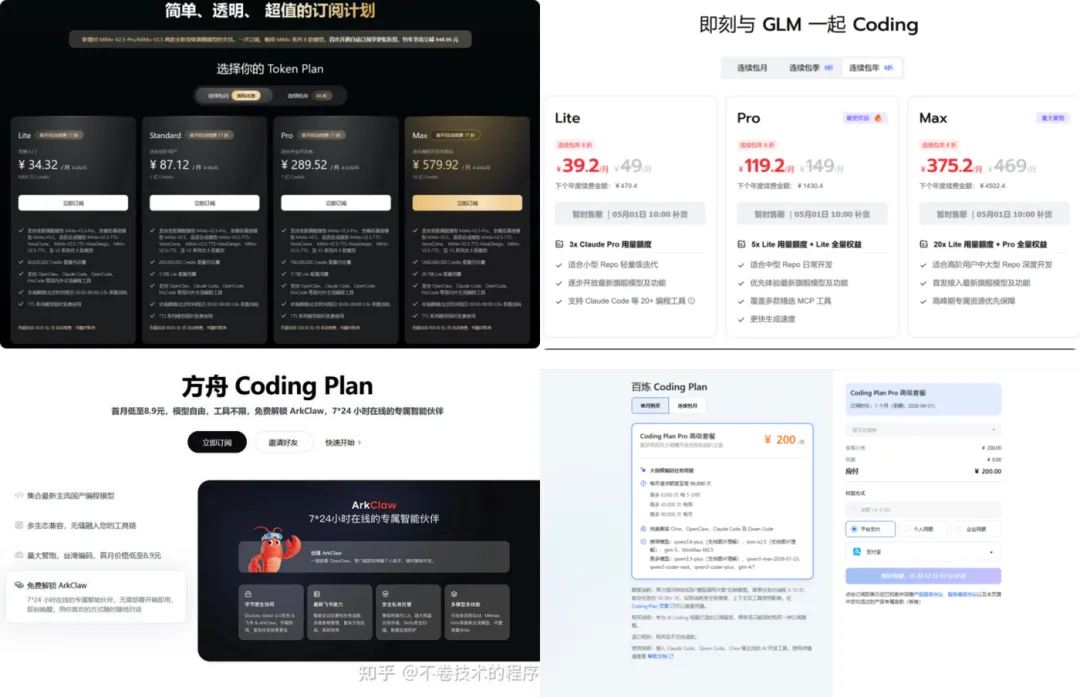
图 5:几类典型 Coding Plan / Token Plan 官网截图。不同厂商的名字、额度都不一样,但核心无非是把 Token 的成本包装成方便用户购买的套餐。
这段时期,AI 编程的使用成本确实降了不少。但好景不长。
2025 年 6 月,Cursor 率先把"包月包次"改成了"按 API 用量计费"。2026 年 4 月,GitHub Copilot 暂停了大部分个人套餐的新注册。2026 年 6 月 1 日,Copilot 正式全面启用 GitHub AI Credits 额度系统——按模型和 Token 用量扣费。国内的智谱、阿里云、字节的 Coding Plan 也陆续转向了 Token Plan——回到了按量计费的老路。
这个来去如风的 Coding Plan,去哪了?
3.“包月”为何在 AI 领域行不通
AI 和传统互联网的成本结构根本不一样。
传统互联网的边际成本极低。你做一个 App,多一个用户,服务器还是那么多。只有当用户量级翻几倍的时候,才需要一批一批地扩容。一个日活百万的产品,多来一万用户,成本几乎不变。所以互联网公司习惯了"先补贴,后收割":亏钱拉用户,等用户养成习惯,再涨价或者卖广告。
遗憾的是,AI 圈的成本结构截然不同。 每一个用户、每一次请求,都直接消耗 GPU 算力。一个重度 Agent 用户,24 小时挂着龙虾,一天烧的 Token 可能顶一百个轻度用户一个月的量。当所有人都开始"认真用"的时候,厂商的算力直接撑不住。
具体的账是这样:现在的模型都运行在大型 GPU 集群上。以 DeepSeek V4 Pro 为例——它的总参数量是 1.6 万亿(1.6T),每次推理激活约 490 亿参数。部署这样一个全精度模型,即使只做推理,也需要大约 40-50 张 NVIDIA H100(80GB 显存版)来装下模型权重和 KV Cache。如果使用 DGX H200 集群(每节点 8 张 H200),也需要 4-5 个节点。
这些 GPU 并不便宜。目前一张 H100 的价格在 25-30 万人民币(京东自营约 ¥24.9 万),40 张就是千万级的硬件投入。而 GPU 是有寿命的——数据中心环境下 24 小时不间断运行,实际寿命大约 3-5 年,财务上一般按 4-6 年折旧。也就是说,即使不算电费,每天光是设备折旧就在数千元的量级。
但电费不可能不算。以一组中型推理集群(约 1000 张 H100)为例:一张 H100 SXM 版的功耗是 700W,加上制冷和配套(按 PUE 1.3 算),实际功耗约 910W。1000 张集群一天的耗电量约 21840 度。按中国工业电价约 0.7 元/度计算,一天的电费就是 ¥15,288,一年超过 550 万元。
大型模型只要跑在集群里,每天就在烧钱——无论有没有人来调用。因此各大厂商都希望推理负载尽量跑满。服务器闲着就是纯亏,有人用至少能带来账单收入。
Coding Plan 本质上就是 AI 公司这个健身房的年卡。
健身房、瑜伽馆的逻辑是:你看起来买了无限次的服务额度,但实际上大部分人根本用不满——平均下来,办卡的人是不会"回本"的。2026 年 5 月,贵阳的孙女士花 1880 元办了一张 90 天不限次瑜伽季卡,连续上了 20 多天课之后,教练问她"天天来不累吗?",随后把她踢出了微信群。瑜伽馆的理由是"季卡定价低廉,运营成本承压"。
Coding Plan 赌的就是这个。我卖给你额度,赌你用不满,赚的是设备利用率和概率差。但龙虾的出现把这个概率打破了——当每个用户都开始认真用的时候,超卖模型就崩了。
这一点,行业内部最先意识到。龙虾火了之后,国内几家大厂为了推销自家的 Token,纷纷打起了价格战。2024 年到 2025 年间,智谱、阿里云、百度、字节先后推出 Coding Plan。你卖 ¥9.9/月,我卖 ¥19.9 包干;你送 500 次,我送 2000 次。价格战打到了什么程度?如果用户把额度用满,几乎所有的 Coding Plan 算下来都会亏本。但那段时期,行业里弥漫着一种"先圈用户、后谈赚钱"的互联网惯性:只要能拉到 DAU,亏的钱 VC 会买单。
2026 年 4 月 6 日,小米 MiMo 大模型负责人罗福莉在 X 上发了一段话,两个核心观点:第一,LLM 公司在搞清楚 Coding Plan 怎么定价不亏钱之前,不要盲目打价格战。第二,第三方 Agent 框架(如龙虾)的上下文管理做得极差,一个用户请求会触发多轮低价值的工具调用,实际消耗是原生框架的数十倍。

图 6:罗福莉在 X 上的发言全文。
就在罗福莉发言的几天前,Anthropic 刚刚切断了第三方 Agent 框架通过 Claude 订阅调用的通道。行业开始意识到:Coding Plan 的"无限",真的撑不住了。
果然,没过多久,各大厂商的 Coding Plan 开始收缩。GLM 的 Coding Plan 根本买不到,直接限购;更多产品则转向 Token Plan——回到了"按量计费"的老路。
罗福莉说的"搞清楚怎么定价不亏钱"就是这个意思。便宜是便宜不起的。
4.选套餐的判断框架
厂商不能亏着卖,但我们还是要用 AI。怎么选?
这里涉及一个我自己提出的判断框架:智能-价格有效前沿。 把市面上每一个模型放到一个坐标系里——横轴是价格(完成固定任务的总成本),纵轴是智能能力(不只是榜单最高分,而是极限发挥和中位发挥的综合)。所有模型放在一起,会形成一条"有效前沿":同样价格下更聪明、同样智能下更便宜的模型会站在前沿上。
模型不一定只是一个点——它还可以有一个"服务半径"。低延迟、长上下文、工具调用稳定、企业合规、生态集成,都会让模型获得额外加分。只要这个半径还能触及有效前沿,它就仍然有生存空间。
但如果一个模型既不便宜,也不聪明,附加价值又不足以弥补差距,它就会跌入"斩杀线"以下。
AI 时代的模型竞争,就是不断把智能-价格前沿往外推。这个模型的定量建模我还在做,后续会以专题文章的形式展开,这里先给出这个判断框架——选套餐的时候,可以用它来判断一个模型的定价到底是"物有所值"还是"在斩杀线以下挣扎"。
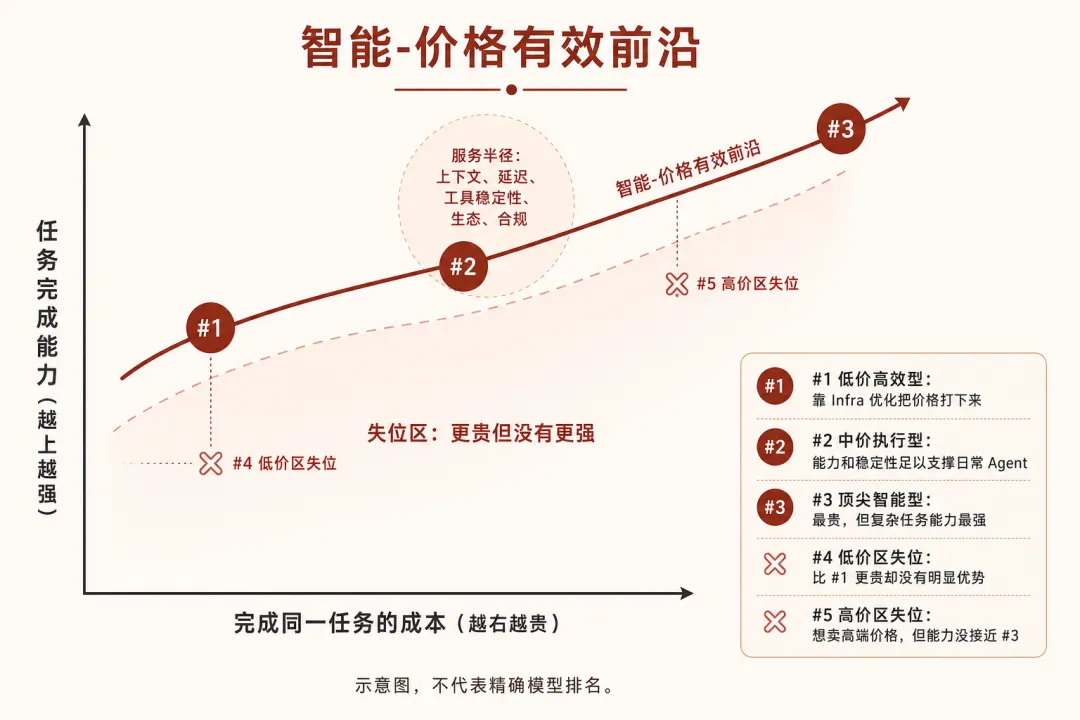
图 7:智能-价格有效前沿的简化示意。一个模型至少要在能力、性价比或者其他某个方面有独特优势,才能立足于有效前沿。
从这个框架来看,能活下来的厂商只有两类。
第一类是"顶尖智能"。 Claude Opus 4.8、GPT-5.5 Pro 这些旗舰模型,能力确实强,价格也确实贵。它们的用户不在乎价格——在高要求的编码任务、复杂推理、企业部署中,"能力够不够用"比"便宜不便宜"重要得多。很显然的是:只要你的模型足够聪明,足够不可替代,能解决其他人解决不了的问题,那无论价格多高你就注定站在前沿上。
第二类是"优化 Infra"。 DeepSeek 是这条路的标杆。从 V2 的 MLA(多头潜在注意力,KV Cache 减少 93.3%),到 V3 的 FP8 混合精度训练(训练成本仅 $557.6 万),再到 R1 的纯强化学习推理——DeepSeek 的每一代都在公开发论文、公开讲自己是怎么把成本打下来的。到 V4,DeepSeek V4 Flash 的输出价格约 ¥1.90/百万 Token,而 GPT-5.5 约 ¥203.4/百万——差了 107 倍。这个差距来自 Infra 而非营销。2026 年 5 月 22 日,DeepSeek 宣布 V4-Pro API 永久降价 75%。5 天后,小米 MiMo V2.5 系列跟进——Pro 版输出价格从 ¥21-42 暴降到 ¥6,缓存命中从 ¥2.8 砍到 ¥0.025,媒体报道口径是"最高降幅 99%"。
Deepseek 降价已经足够出乎意料,那小米为什么能降?官方说法是:"对 Infra 进行了优化"——技术博客标题叫《MiMo-V2.5 系列推理全链路优化:将 Hybrid SWA 效率推向极致》。优化关键词是 SGLang HiCache、SWA(滑动窗口注意力)、KV Cache 多级存储。
罗福莉之前说"不要盲目打价格战",一个月后小米降了 99%,乍一看是很打脸,不过小米降价的根本原因是 Infra 优化,不是补贴。补贴早晚得涨回来;但如此这般 Infra 优化做得到位,这个价格就是仍然能盈利的长期价格。
在笔者的体验中(上个月获得了小米赠送的一个月 MiMo Token Plan Max),MiMo 在我的 Hypo-Workflow Harness 下的表现和 DeepSeek 可以说各有千秋,并不明显逊色。一轮细致的 Infra 优化,就让一个本来毫无竞争力的模型变得相当有竞争力了。可见,对于算力规模和数据规模没有独特优势的厂商来说,优化 Infra 是一条非常行之有效的路径。
5.选对套餐,比选便宜套餐重要
框架有了,回到现实。以下是 2026 年 6 月的主流模型 API 定价(元/百万 Token),按输出价格从低到高排列:
汇率 1 USD = 6.78 CNY。数据截至 2026.06.08。
选套餐就是选需求。不存在"最划算的套餐",只存在"最匹配你当前任务的套餐"。
至于怎么选,取决于你把 AI 用在什么地方。
如果你只是偶尔用 AI,写个函数、查个 bug、改改文档:DeepSeek V4 Flash 或 MiMo-V2.5 的 Token Plan 就够了。输入约 ¥1、输出约 ¥2,一个月花不了几块钱。
日常 Agent 用户——龙虾常开,每天让 AI 帮你重构代码——一个务实的策略是"混用"。用顶尖模型(Claude Opus 4.8、GPT-5.5)做规划和复杂推理,用中等价格的国产模型(DeepSeek V4 Pro、MiMo-V2.5 Pro)做执行。¥3-6/百万的执行层价格,配合顶尖模型的规划能力,是目前性价比最高的组合。当然,如果你的任务偏中文场景,All in GLM-5.1 或 Kimi K2.6 也是可行的——¥24-28/百万的输出价格,虽然不是地板价,但比国际旗舰便宜不少。
作为超重度用户本人来讲:我用的是 $200/月的 GPT Pro,相当于 20 倍 GPT-Plus 的 API 额度,据我本地的统计,一个月有 $10000 的额度;而且我真的能用满。这个时候不用精打细算每百万 Token 便宜多少钱——直接猛蹬最贵、最强的模型。贵,但当你的时间成本足够高的时候,"最强模型"就是最便宜的选项。
至于订阅套餐——GitHub Copilot ($10-100/月)、Cursor ($20-200/月)、小米 MiMo Token Plan (¥39-659/月)——它们本质上都是"打包卖你一定额度的 Token 使用权"。区别在于额度多少、模型可选范围、以及超出后怎么计费。Coding Plan 时代那种"包月随便用"的日子已经过去了,现在每一份套餐都在用量表里精打细算。
选之前,得先想清楚自己的使用模式。
6.没什么可慌的
"随便用"的时代确实结束了。每一次 AI 调用都是笔账。会不会算这笔账,直接决定你能不能把 AI 用明白。
这件事还有个意外的好处:当 AI 不再"无限"的时候,反而会逼着你想清楚自己到底要什么。真正稀缺的东西,是你明确需求的能力。AI 的能力反而在其次。
说到这里,可能有人会担心:我不懂技术,不会写代码,看不懂这些表格和价格,是不是就用不好 AI 了?
正好相反。明确需求跟技术能力没什么关系。你做财务的,知道月底要出什么报表。你做销售的,知道客户在意什么、提案要突出什么重点。你管团队的,知道这个季度要推进哪几件事、哪些环节容易卡住。这些不都是明确需求么?
AI 的价值在于让你把已经明确的需求更快地落地。你不需要懂 Token 怎么算、不需要看懂技术博客里的 KV Cache 优化,你只需要知道:我现在要做什么、大概要花多少钱、这笔钱值不值得花。跟你决定打车还是坐地铁一样,就是个日常决策。
这年头 AI 卷得这么厉害,真正拉开差距的,反而是那些知道自己要干什么的人。技术会过时,工具会更新,但明确需求的能力不会。会用 AI 和不会用 AI 之间的差距,说到底就是"知道自己要什么"和"不知道自己要什么"的差距。
所以如果你现在还不太懂 AI,不用慌。先从小事开始:让 AI 帮你整理会议记录、写个周报、梳理一份清单。用多了,你自然会知道它能帮你做什么、不能帮你做什么。到那时候,选套餐就是选工具;而懂需求的人,选工具一向有优势。
本文说明:
本文是「AI 时代判断力」系列的第一篇试运行文章。关于"智能-价格有效前沿"的定量建模,将在后续专题文章中展开。
数据来源:
1.DeepSeek API Docs:Models & Pricing
2.OpenAI API Docs:Pricing
3.Anthropic API Docs:Claude pricing
4.GitHub Copilot Docs:Usage-based billing for individuals、Requests in GitHub Copilot legacy
5.Cursor Pricing:cursor.com/pricing
6.罗福莉相关发言:X 截图见正文图 6
7.工具界面截图来源:Cursor 官网、VS Code + Copilot 真实界面截图、Claude Code 官网
8.Coding Plan 截图与国内模型套餐价格:阿里云百炼、Kimi 开放平台、火山方舟、智谱文档、MiniMax 官方定价、腾讯云混元、小米 MiMo 官方文档
价格数据截点:
价格数据截至 2026.06.08。不同平台会有促销、缓存命中、上下文长度、批处理和地域加价等差异,本文表格只用于横向判断价格层级。
利益关系说明:
文中提及的 MiMo Token Plan Max 为小米赠送的一个月试用,无任何付费推广关系。
