 夜雨聆风
夜雨聆风你拍下一张照片,AI也许能帮你调亮、美颜、换个滤镜,却很难真正把它变成你心中想要的样子。一张照片不好看,往往是因为一开始就没拍对:构图偏了、视角歪了、姿态僵了。现有的图像美化工具能做的是调亮度、加美颜、套滤镜,但面对拍摄时留下的结构性缺陷:站错了位置、取错了角度、摆错了姿势。这些工具却是无能为力。
北京大学彭宇新教授团队在美学理解领域的最新研究,给出了一个不同的答案。他们定义了一个新任务:美学照片重构,通过从互联网拍照教学视频中自动挖掘美学语料,构建出了首个美学照片重构数据集与评测基准AesRecon,还提出了两阶段模型AesFormer,让AI不仅能做表层修饰,还能调整构图、视角与人物姿态,从画面结构层面提升照片美感。相关论文已被ICML 2026接收并开源。

论文链接:https://arxiv.org/abs/2605.22126开源代码:
https://github.com/PKU-ICST-MIPL/AesFormer_ICML2026
从表层修饰到画面重构
拍照是记录日常场景与情感的重要方式,但动人的瞬间稍纵即逝。专业摄影师经过系统训练,能在按下快门的瞬间快速判断构图、视角和姿态,而普通用户拍出的照片经常存在构图偏移、视角失衡、姿态僵硬等问题。现有的图像美化工具大致分为两类:调色工具调整曝光、亮度、对比度,美容工具负责磨皮、美白、瘦脸。它们可以改善色彩、光影和人物外观,但无法修正拍摄阶段留下的结构性缺陷。简单来说就是,如果人站的位置不对、镜头角度歪了、身体姿态僵了,单纯调色或美容就帮不上忙了。
研究团队将这个问题定义为美学照片重构:在保持人物身份和场景内容基本一致的前提下,对构图、视角、姿态进行合理调整,从画面结构层面提升照片美感。但要实现这个目标并不容易。一方面,高质量美学语料稀缺,现有数据缺乏同一人物、同一场景、由差到优的成对人像照片样本。另一方面,现有图像编辑模型缺乏系统的摄影美学知识与审美判断能力,难以准确识别照片问题并完成合理的画面重构。
从拍照教学视频里偷师
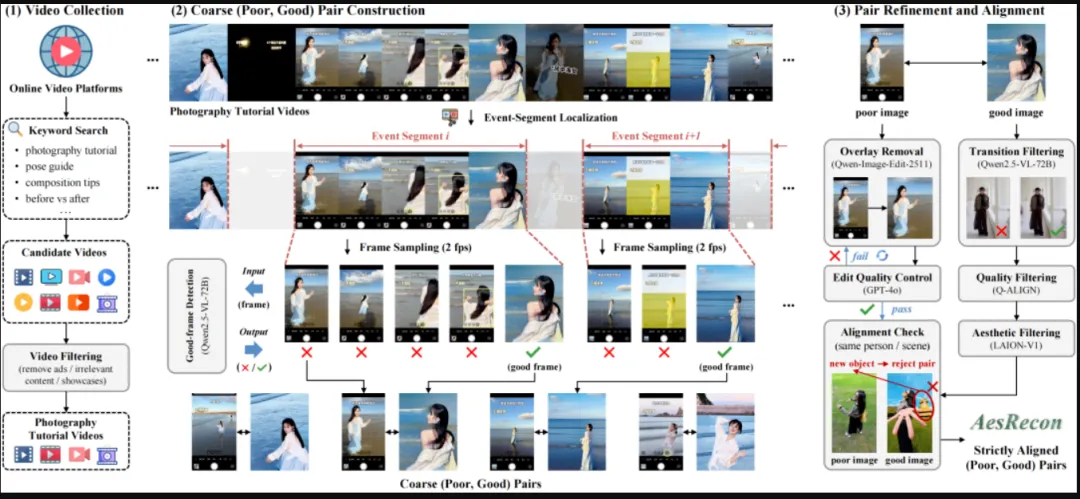
现有图像资源中,能呈现同一人物、同一场景、由差到优的成对人像照片样本十分稀缺。团队找到了一个巧妙的切入点:互联网上的拍照教学视频。这类视频通常会完整记录同一人物、同一场景下的拍摄优化过程:摄影师与模特不断调整机位、构图与人物姿态,让画面从效果普通的原片,逐步优化为更具美学表现力的成片。这正是天然的“差→优”配对数据。
基于这一观察,团队提出了基于拍照教学视频的美学语料挖掘方法VCMP,通过四个阶段完成语料挖掘:先在视频中定位高质量出彩成片,再匹配语义一致但效果欠佳的普通原片,接着去除字幕、图标等遮挡元素,最后检查每对照片是否来自同一拍摄事件。最终构建的AesRecon数据集包含9071对严格对齐的“普通原片-出彩成片”人像照片样本。
两阶段模型AesFormer:先规划,再编辑
有了数据,还需要一个能用好这些数据的模型。团队提出的AesFormer采用“美学规划+美学编辑”两阶段路线。
第一阶段,美学规划。针对每组照片对,团队先提炼摄影师在拍摄过程中的调整思路,形成美学优化方案。随后对多模态大模型进行冷启动监督微调,将优化方案建模为符合摄影逻辑的有序决策序列,引导模型沿七个递进的摄影维度分析照片问题。为了防止模型“死记硬背”,毕竟同一张照片没有唯一的正确改法,团队进一步提出美学引导的组相对策略优化,鼓励模型探索更多样、更合理的优化路径。
第二阶段,美学编辑。通过以美学优化方案为条件的流匹配训练,图像编辑模型将抽象的美学方案转化为精确的像素级修改。推理时,两阶段串联:先由规划模型生成优化方案,再由编辑模型结合输入照片和方案,生成最终的重构照片。

实验结果:优于现有开源模型,与闭源商业模型相当
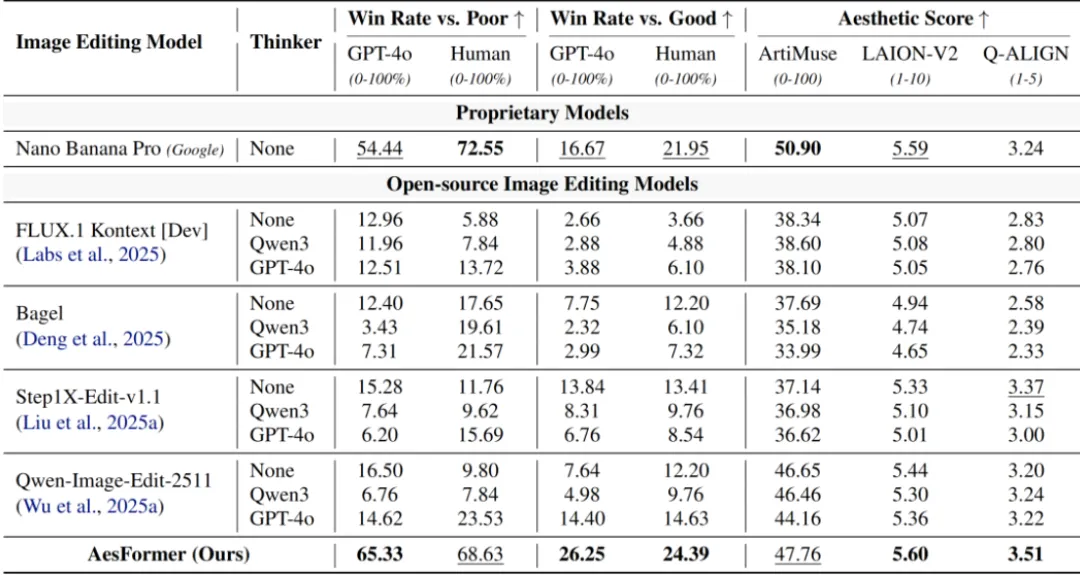
在AesRecon评测基准上,AesFormer在各项指标上均优于开源模型,并与Google闭源商业模型Nano Banana Pro表现相当,在多数指标上取得更优结果。团队还探究了一个关键问题:能否通过简单组合现有的“思考模型”和“编辑模型”来实现美学照片重构?实验结果显示,这类组合并未带来稳定提升,部分情况下甚至导致性能下降。原因很明确:通用模型缺乏美学理解能力,难以准确规划构图、视角、姿态等结构性调整;通用编辑模型也缺乏美学执行能力,难以稳定完成摄影语义下的复杂编辑。这也反向印证了美学照片重构作为一个独立任务的研究价值。
AI视频赛道又一大厂杀入,开源JoyAI-Echo,5分钟长视频角色不崩、声音不乱
一张图秒变视频,xAI 发布 Grok Imagine Video 1.5
