 夜雨聆风
夜雨聆风
过去一段时间,我们聊 AI Agent,主要看三件事:会不会调用工具、能不能自动写代码、能不能在浏览器或终端里完成任务。但真正把这些 Agent 放进复杂环境里,你会发现很多 demo 之外的问题还没解决:它们会卡在中间步骤,会重复调用工具,会在错误路径上越走越远,也很难从失败里真正学到东西。
这就是我最近重新看 Agentic RL 的原因。普通 Agent 更像是“用 prompt 指挥模型干活”,而 Agentic RL 想解决的是“怎么让模型在环境里试错、拿反馈、再变强”。今天这个项目 Open-AgentRL,就属于这个方向里比较值得拆的一类。
Open-AgentRL 是 Gen-Verse 开源的 Agentic RL 项目,仓库当前约 543 stars、54 forks,协议是 Apache-2.0。它把两项工作放在一个仓库里:RLAnything 和 DemyAgent。前者关注环境、策略模型、奖励模型的闭环优化,后者关注真实工具轨迹、探索友好的训练方法,以及更节制的工具调用。
官方 README 里最值得看的更新是这一句:
RLAnything is accepted by ICML 2026.
简介
Open-AgentRL 不是一个“下载就能聊天”的 AI 工具,而是一个面向 Agent 训练和评测的开源研究框架。它覆盖的场景比较实在:GUI 操作、LLM Agent、Coding LLM、终端、SWE、工具调用。换句话说,它关心的不是 Agent 能不能在单个 demo 里完成任务,而是 Agent 能不能在真实交互环境里被系统性训练。
这点很关键。传统大模型训练更像是给模型看题和答案,而 Agent 做事不是一次性答题。它要观察环境、决定下一步、调用工具、读取结果、修正动作,再继续推进。只看最终成功或失败,很多中间决策学不到;把过程反馈也纳入训练,Agent 才有机会从“会回答”变成“会干活”。
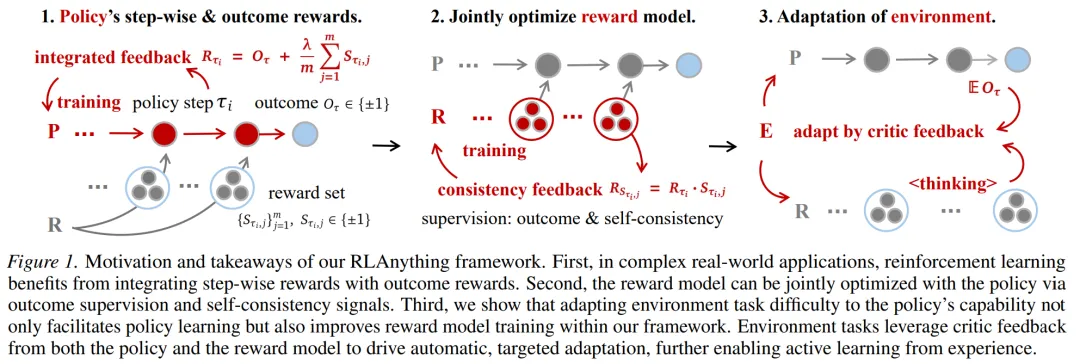
RLAnything 的核心思路,是把环境、策略模型、奖励模型放进一个动态闭环里。策略模型不只吃最终结果,也吃 step-wise 的过程信号;奖励模型也不是固定裁判,而是通过 consistency feedback 一起被优化;环境本身还会根据 critic feedback 自动适配,让训练过程更像“在任务里积累经验”。
如果用更直白的话讲,RLAnything 想做的是:不要只在最后告诉 Agent“你做对了”或“你做错了”,而是在它每一步操作里尽量给出可学习的反馈。这对 GUI Agent、Coding Agent、工具调用 Agent 都很重要,因为这些任务的失败往往不是最后一步错了,而是前面某个决策已经把路径带偏了。
安装
Open-AgentRL 的安装分成两条线:DemyAgent 和 RLAnything。它不是轻量级命令行工具,环境配置会比普通 Python 包重很多,更适合研究复现、算法实验或 Agent 基础设施团队先看。
DemyAgent 的环境推荐 Python 3.11,官方 README 给出的安装方式是:
git clone https://github.com/Gen-Verse/Open-AgentRL.git
conda create -n OpenAgentRL python=3.11
conda activate OpenAgentRL
cd Open-AgentRL
bash scripts/install_vllm_sglang_mcore.sh
pip install -e .[vllm]
RLAnything 则是另一套环境,推荐 Python 3.10:
conda create --name rlanything python=3.10
source activate rlanything
pip install -r requirements_rlanything.txt
这里要提前说清楚:如果你只是想找一个今天就能拿来写代码的 Agent,这个项目不适合当作第一选择。它更像一个训练框架和研究基线,涉及数据、模型、执行环境、评测脚本,甚至 GPU 资源。比如 DemyAgent 的 RL 训练,官方说明里提到使用了 8 x Tesla A100 节点,batch size 是 64。
使用
Open-AgentRL 的使用方式,不是打开一个聊天窗口输入问题,而是围绕“训练”和“评测”展开。它提供了数据、recipe、模型 checkpoint、评测入口和不同任务环境的训练脚本。对读者来说,最容易看懂的路径可以分成三类:DemyAgent 的 SFT、DemyAgent 的 Agentic RL,以及 RLAnything 的多环境训练。
跑 DemyAgent 的 SFT
DemyAgent 先从 cold-start SFT 开始。你需要下载官方提供的 3K Agentic SFT 数据,再准备对应 base model,比如 Qwen2.5-7B-Instruct 或 Qwen3-4B-Instruct-2507。配置好训练数据、评估数据、模型路径和保存路径后,可以跑官方 recipe:
bash recipe/demystify/qwen3_4b_sft.sh
训练完成以后,还要把 checkpoint 合并成 Hugging Face 格式:
python3 -m verl.model_merger merge \
--backend fsdp \
--local_dir xxx/global_step_465 \
--target_dir xxx/global_step_465/huggingface
这一步的目的不是让模型“更会聊天”,而是先让它具备 Agentic Reasoning 的基础动作。也就是面对工具、任务和推理链路时,模型知道自己应该怎样组织过程。后面再做强化学习,它才不是从完全混乱的状态开始探索。
跑 DemyAgent 的 Agentic RL
强化学习阶段用的是官方称为 GRPO-TCR 的 recipe。你需要下载 30K Agentic RL 数据和评测数据,再配置 SandboxFusion 作为代码执行环境。这个设计很重要,因为 coding agent 的评测不能只看文本输出,还要真的执行代码,看结果对不对。
bash recipe/demystify/grpo_tcr_qwen3_4b.sh
官方也提到,可以通过 Weights & Biases 观察训练动态和评测结果。也就是说,这不是一个简单 fine-tune 脚本,而是一整套实验管线:数据、执行沙箱、奖励计算、评测 benchmark、训练日志都要配起来。
跑 RLAnything 的 GUI / 文本游戏 / Coding 场景
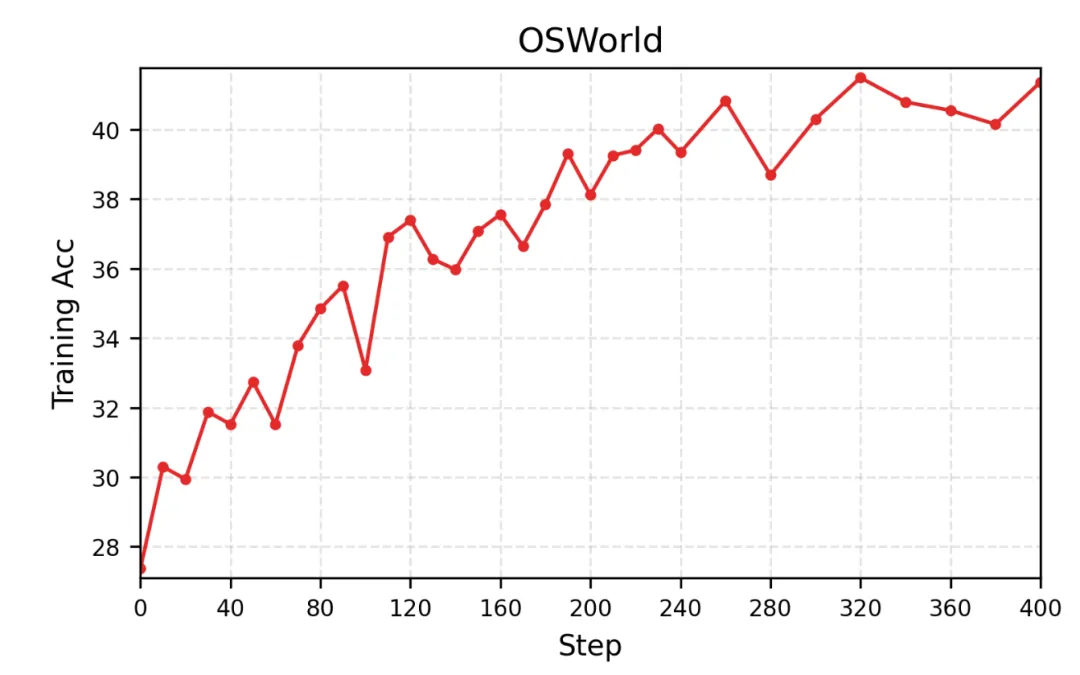
RLAnything 更像通用 Agentic RL 框架。它把任务拆到几个典型环境里:Computer Control 对应 OSWorld,Text-based Game 对应 AlfWorld,Coding 对应代码任务训练和评估。每个环境都有自己的配置文件和入口脚本。
Computer Control 的入口是:
python osworld_rl.py config=configs/osworld_rl.yaml
Text-based Game 的入口是:
python alfworld_rl.py config=configs/alfworld_rl.yaml
Coding 场景的入口是:
python coding_rl.py config=configs/coding_rl.yaml
这也是 Open-AgentRL 最像“基础设施”的地方。很多 Agent 项目只展示单点能力,比如浏览器点几下、终端跑一条命令、代码改一个函数。Open-AgentRL 关心的是更底层的问题:怎样让 Agent 在不同环境里获得可泛化的学习信号,而不是每个场景都重新堆规则。
测评数据
Open-AgentRL 的结果主要分两块看。第一块是 DemyAgent 的 Agentic Reasoning 结果,覆盖 AIME2024、AIME2025、GPQA-Diamond、LiveCodeBench-v6;第二块是 RLAnything 在 OSWorld、AlfWorld、LiveBench 等任务上的提升。两类结果指向同一个问题:Agent 的能力不能只靠 prompt,训练范式也很关键。
先看 DemyAgent。README 表格显示,DemyAgent-4B 在 Agentic Reasoning 设定下,AIME2024 是 72.6,AIME2025 是 70.0,GPQA-Diamond 是 58.5,LiveCodeBench-v6 是 26.8。官方对比里,它用 4B 规模,在部分 benchmark 上追上甚至超过了更大的 14B/32B Agentic 方法。
这里不要简单理解成“4B 全面吊打 32B”。更准确的说法是:在这些特定 agentic reasoning 设置下,真实轨迹、高质量数据、探索友好算法和工具调用策略,可以让小模型获得很强的任务表现。对做 Agent 的团队来说,这个结论比“继续堆参数”更有启发。
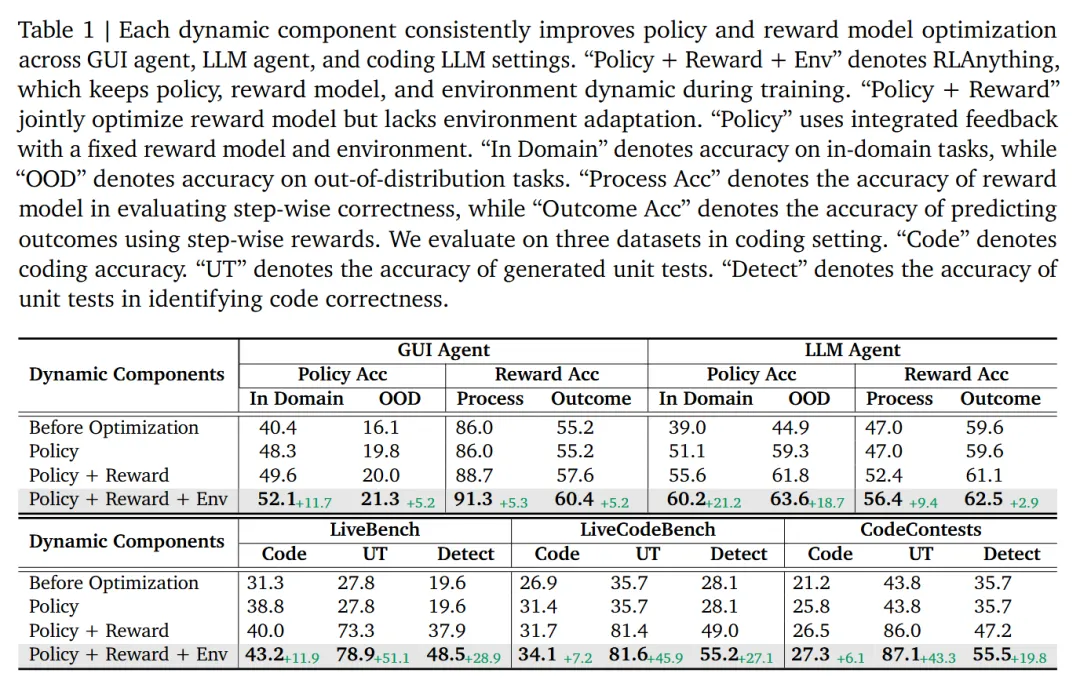
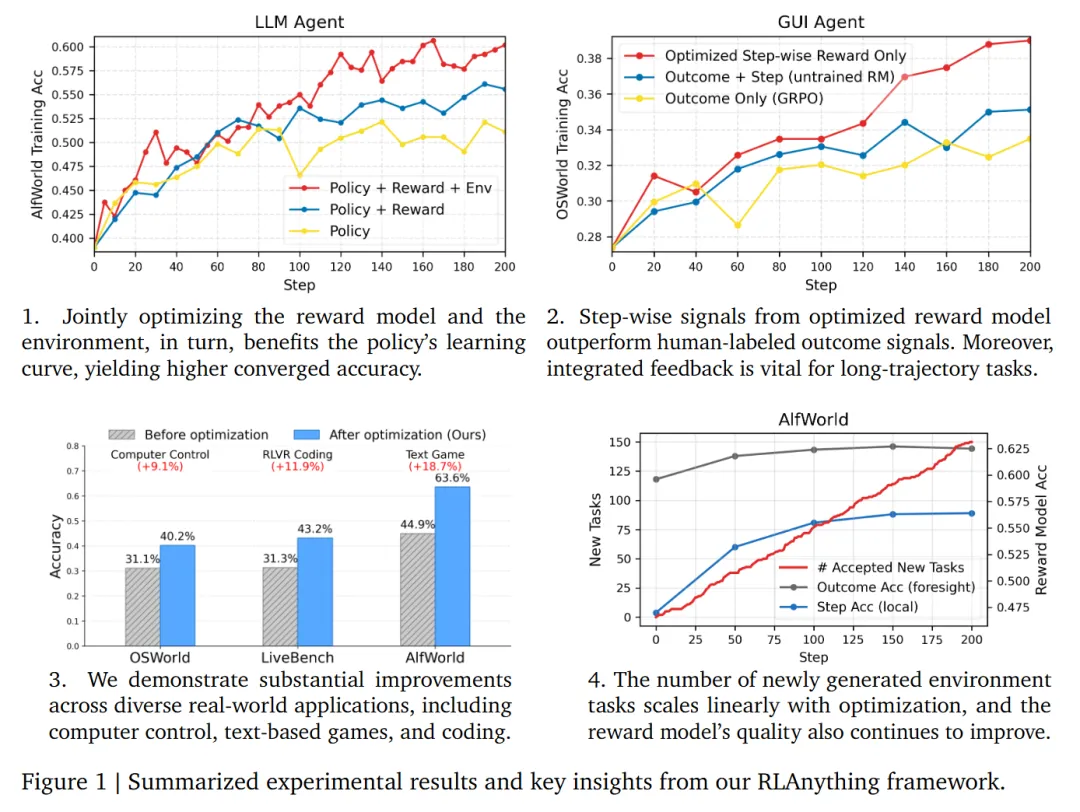
再看 RLAnything。arXiv 摘要里写到,RLAnything 在多个 LLM 和 Agentic 任务上带来提升,比如让 Qwen3-VL-8B-Thinking 在 OSWorld 上提升 9.1%,让 Qwen2.5-7B-Instruct 在 AlfWorld 和 LiveBench 上分别提升 18.7% 和 11.9%。这些数字说明,它不是只在单一 benchmark 上调参,而是试图把“环境-策略-奖励”闭环做成更通用的训练范式。
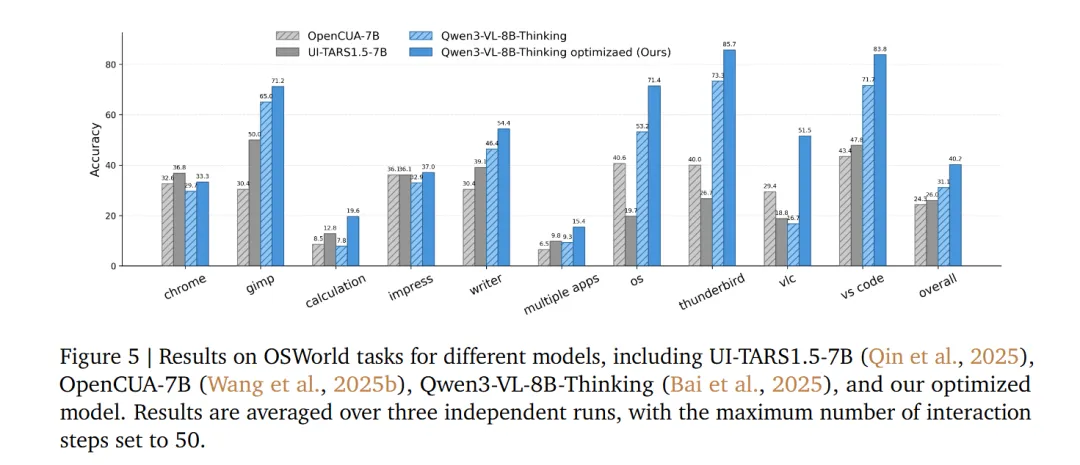
真正值得关注的不是某个数字单点有多高,而是这个方向背后的判断:复杂 Agent 的失败往往发生在过程里,而不是最后一行答案里。模型如果没有过程反馈,就很难知道自己是哪里走偏了。RLAnything 这类框架想补的,正是这块训练信号。
部署选型建议
Open-AgentRL 不是面向普通用户的一键工具,所以“怎么用”要按角色来看。如果你是普通开发者,最合适的方式不是马上训练,而是先看论文、README、图示和评测表,理解 Agentic RL 为什么会成为下一阶段重点。如果你是 Agent 产品团队,则可以重点关注真实轨迹、工具调用频率、执行沙箱、奖励设计这些模块。
如果你是算法或研究团队,这个项目的价值会更直接。它给了训练代码、模型 checkpoint、数据和评测脚本,而且覆盖 GUI、文本环境、Coding、工具调用多个场景。相比只看论文,这种开源程度更适合做复现实验和后续改进。
510.11701)
