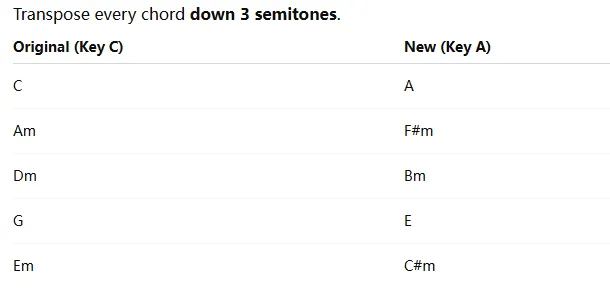
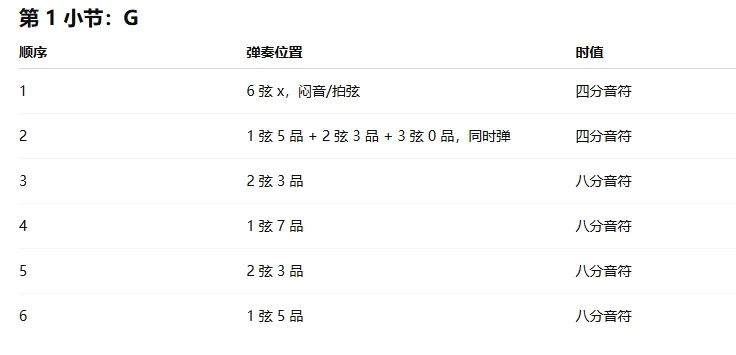
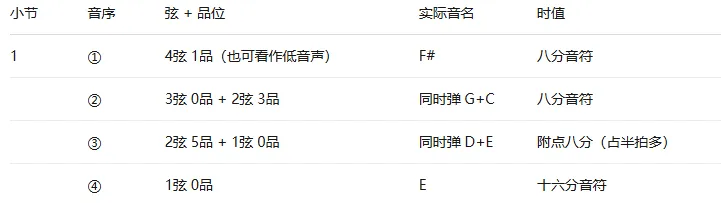
最近断断续续在做一个事:用ai识别吉他谱图片,并渲染还原。最初的想法是,告诉ai一个歌名和歌手名,再告诉它一个调式,得到一个该调式的曲谱。用gemini试了一下。好家伙,不光谱子是瞎编的,连歌词都是瞎编的。那如果直接给音源让ai生成曲谱呢?倒是有现成的乐器剥离的模型。不过现在都在云平台上听歌,云平台也不会给开放的api接口,即使已经付费。如果一边用云平台放歌,一边在后台录,同步交给模型去跑,倒是可行,就是太不方便。那再换种思路,我找好一张吉他谱的图片扔给ai,让它按我的要求进行调式、风格、弹奏难度等方面的改编。感觉应该不是个难事吧。用gpt试了一下,把一首歌的C调吉他谱图片转为A调。和弦能提取出来,转换也没问题。但是再还原到图上就漏洞百出了。但我总觉得这事不难,不就是图像识别吗,都多少年前的东西了。用ocr+opencv,再加一堆规则告诉它识别出来的线、数字、箭头、符号都是什么意思。另外写一个格式化的json文件对音乐语义进行表述,再将这个文件转换成musicxml,最后用musescore渲染出来。思路很清晰。但是实现起来遇到各种问题。最大的问题还是识别不准。错误花样百出。添加海量规则后还是稳定性很差,特别是对于带水印的谱图(网上找到的绝大多数谱图都是带水印的),效果更是糟糕。我意识到这是opencv的识别能力所限,得另换工具。目前倒是有识别五线谱的比较成熟的omr,识别吉他谱的omr只有零星几个,试用后效果都不好。那干脆自己训练个小模型算了,手头显卡应该也够用。开始是想机器跑一些随机的结构化谱图数据出来,再渲染成图片作为训练数据。但是网上找到的吉他谱图片风格各种各样,并且很多是由guitar pro这样的软件编排的,对应的曲谱文件又不是结构化的。而自己只能生产风格比较单一的图片,不好做泛化。唯一的路径是搜集大量吉他谱图片,然后手动做标注。我在花了大半天时间终于标注了2个谱子之后还是选择了放弃。过了些天我突然反应过来,我如果不让gpt直接生成图片,而是只让它提取信息呢?于是又找回了chatgpt。哈哈,确实可以。我用codex写了从识别到渲染的整套流程,然后跑出来结果后又傻眼了,依然错误百出。原来openai并没有给codex配上最好的视觉模型,它定位本来也不是干这个的。所以只能买openai的api key,在后台调用。但是用来干这么个小事感觉又不值当。那换国内的多模态模型吧,毕竟便宜些。我先找了minimax,与交给gpt的是同一张图片。这都是啥?我又找了千问。这又是啥?我再找Gemini试试吧。呵呵。果然gpt贵是有贵的道理的。那省钱的方案就只能用chatgpt来做识别,再把结果放到本地跑。好在codex有浏览器插件,做成自动化工具也不是不行。但是后来又发现,gpt识别出的结果虽然大体上是对的,细看还是有错误,依然需要进一步调试。并且chatgpt也不是天然用来任务执行的,上下文窗口有限,添加工作流式的输入输出也会遇到一些天生的问题。所以这个看起来很简单的事到现在也没干成,虽然接下来的困难应该不是很大了。回想起来,问题的本质不在于技术选型,而在于一种根本的错位:图片格式的曲谱是给人眼设计的,而 AI 天然亲近的是结构化的、可度量的数据。我做了很多尝试去弥合这道鸿沟——规则引擎、传统视觉算法、小模型训练、多模态大模型,每一种方案都在某个环节暴露出新的缺口。如何把便于人理解的信息形式,转述为便于 AI 理解的信息形式?这其实是当下许多领域正在面对的共性挑战。从文档解析到代码生成,从医疗影像到工业质检——人类积累了海量以「人」为中心的信息载体,而 AI 时代的真正瓶颈,或许不在于模型本身的能力上限,而在于我们能否找到那座连接人与机器的桥梁。这也正是世界变化的一个重要方向——不是 AI 变得像人,而是人与 AI 之间的信息,开始被重新编码。
基本文件流程错误SQL调试
请求信息 : 2026-06-12 07:37:31 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/734575.html
 夜雨聆风
夜雨聆风