 夜雨聆风
夜雨聆风每次研究这些东西都激动不已,为AIP叫绝。Palantir的一整套产品体系,每个零部件都设计的如此精妙,如此结实。反观市面上的AI软件和AI产品,垃圾充斥,弄虚作假胡乱吹嘘的比比皆是。有多少公司能像Palantir这样踏踏实实把一个软件作20多年呢,遇到LLM来临,活了。
在企业数字化转型的浪潮中,数据通常被比作新时代的石油,但是大多数企业在开采这口油井时,只获取了表层的20%,即那些乖乖躺在数据库行和列中的结构化数据。剩余的80%则深埋在数据冰山之下的是PDF合同、电子邮件、维修日志、调查报告、卫星图像注释等非结构化文档。
而且实现中,绝大多数企业的数据是分散的(ERP、CRM、Excel、传感器数据、图片、文档等),直接把LLM接进去,AI根本看不懂这些杂乱的乱七八糟的数据,容易产生幻觉,当今市面上大部分的所谓RAG系统、知识库问答系统、智能问数系统都是垃圾。说起来热闹,用起来拉胯。因为其底层逻辑是有天然问题的。只有Palantir很好的解决了这个问题。
Palantir通过本体(Ontology)为企业构建一个数字孪生(或者我们起个新奇的名字叫数据孪生也可以)模型。AIP 建立在 Palantir 现有的平台(Foundry 或 Gotham)之上,它利用本体(Ontology)将企业的物理资产(如工厂、卡车、订单、客户等)映射为数字孪生。在Foundry时代,本体主要由结构化对象组成。但随着Palantir AIP的推出以及大语言模型LLM的引入,文档数据已成为Ontology中非常核心的环节。
因为文档是物理世界的真实记录。Palantir AIP创造性的通过文档数据的结构化、语义化、向量化、对象化,才真正实现了AI在企业落地,才真正敢吹牛:API是一个企业操作系统(EnterpriseOS)。
我们分析一下文档数据如何在Palantir本体中存在、转化、关联并最终驱动决策。涉及的AIP产品模块包括:Pipeline、Ontology、AIP Logic、Workshop。文档数据贯穿始终。
在传统的数据湖或云存储中,文档仅仅是一个二进制文件(Blob),系统只知道它的文件名、大小和创建时间,却完全不懂它的内容。在Palantir Foundry的Ontology中,文档被赋予了新的生命。
在本体中,一个合同文档不仅仅是一个PDF查看器,它是一个拥有双重属性的实体。元数据层(Metadata)包含结构化属性,如上传者、上传时间、文件类型、版本号等。内容层(Content)是文档的核心。Foundry通过Pipeline管道将文档内容的文本提取出来,并将其转化为机器可读的形式。这意味着,文档的内容不再是黑盒,而是可以被结构化、被向量化、被对象化、被语义化、被搜索、被引用、被分析的字段。
技术上,原始文件存储在Foundry的媒体集mediasets中,这是一种专门用于处理非事务性、大体积文件的存储机制。Ontology中的文档对象并不直接存储文件,而是存储一个指向媒体集中特定文件的引用(Reference)。这种架构设计保证了Ontology的高性能查询,同时能够无缝调取原始文件进行预览。
Pipeline builder提供了文档数据的处理流水线。将一份扫描的PDF发票变成Ontology中一个智能对象,需要经历一套复杂的炼金过程,其实也比较简单没那么难。Palantir为此提供了一套完整的数据编排工具链。
第一步:摄取与OCR
这里面有三种选择,不是所有的多需要OCR,看情况。
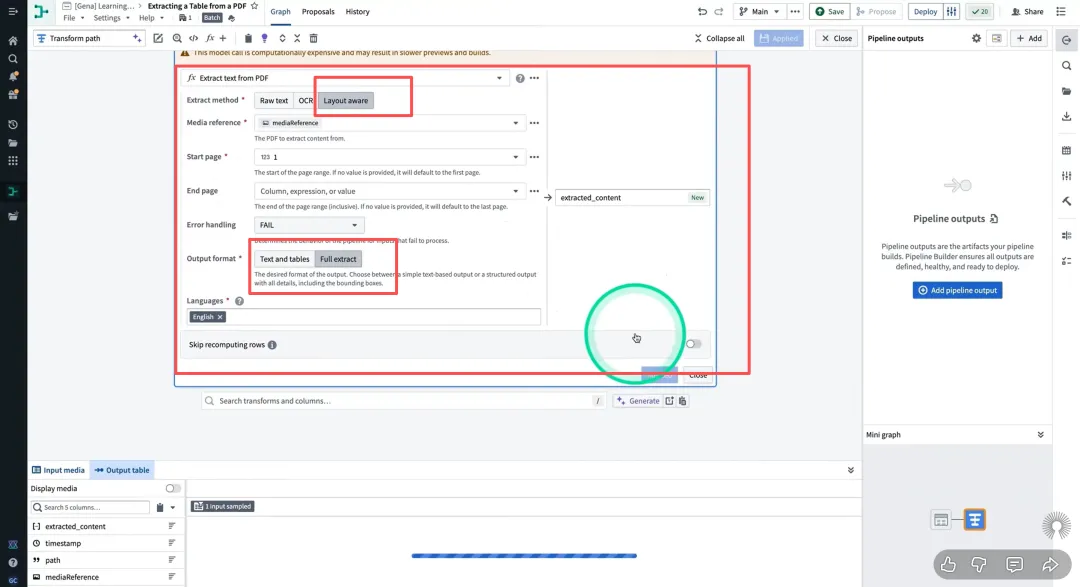
数据首先通过Data Connection接入Foundry。对于纯文本文件(如TXT, CSV, HTML),系统直接读取。对于扫描件或图片格式的文档(PDF, JPG, TIFF),Foundry集成了强大的OCR引擎(既包含开源的Tesseract变体,也有Palantir自研及第三方商用接口)。OCR不仅仅是将图片转为文字,它还能保留空间坐标信息。这对于后续分析非常关键,例如识别表格中的数据需要知道文字的相对位置。
第二步:文本清洗与分块(Chunking)
pipeline提供了很多算子,反正就是一顿变换,什么样的文档和数据都能变成结构化的、向量化的、语义化的、对象化的玩意。
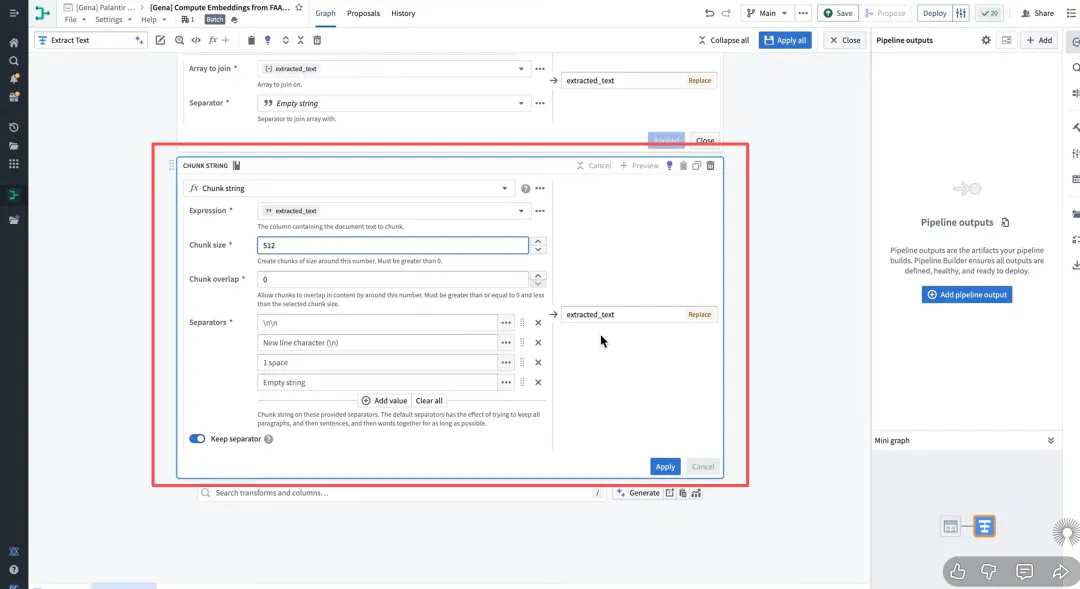
提取出的原始文本往往充满噪点。在这一步,Pipeline会对文本进行清洗(去除乱码、页眉页脚)。更重要的是分块。对于长达几百页的技术手册,直接作为整体处理效率极低。系统会将其切分为语义完整的段落或块(Chunks)。在Ontology中,有时一个文档对象会链接到多个段落对象,以便实现更精细的颗粒度管理。
第三步:向量化(Embedding)
向量化的字段用作召回,结构化的字段用作上下文,两者在ontology上得到统一。
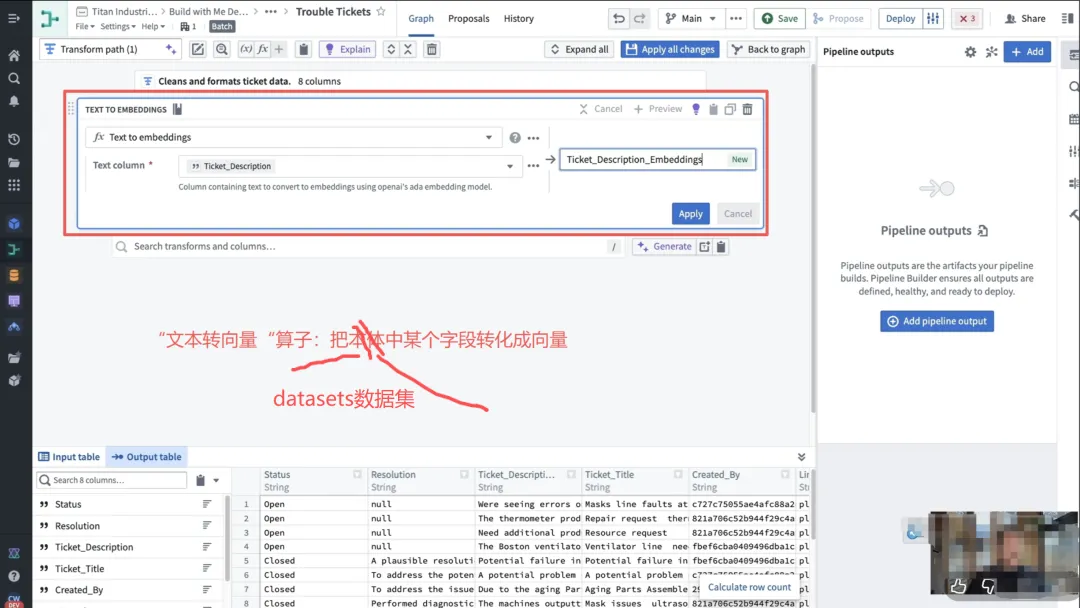
这是文档进入AI时代的门票。Foundry利用嵌入模型(Embedding Models)将文本块转化为高维向量。这些向量捕捉了文字背后的语义信息。例如,发动机过热和冷却系统故障在字面上没有重叠,但在向量空间中距离很近。这些向量被存储在Ontology的向量索引中,为后续的语义搜索奠定基础。
一个的核心质变是LLM与AIP带来的结构化提取。在AIP引入之前,文档在Ontology中更多是被当作附件查看。而现在,通过LLM,文档变成了数据的生成源。
我们可以实现实体提取与属性填充。这是Palantir文档处理中最具价值的环节。通过AIP Logic或Pipeline中的LLM节点,系统可以自动阅读文档,并从中提取关键信息填入Ontology的属性中。
场景: 上传一份法律合同。
处理: LLM读取全文。
输出: 自动提取出甲方、乙方、合同金额、终止条款、生效日期。
结果: 这些提取出的信息不再是文本,而是变成了Ontology对象上的结构化属性(Date, String, Integer)。这意味着可以直接筛选所有金额大于100万且下个月到期的合同,而无需打开任何一个PDF。
同时能够建立动态链接。文档数据不再是一座孤岛。Ontology的核心在于关系。 当LLM从维修报告中提取出设备ID:XC-900时,系统会自动建立该维修报告对象与现有的设备对象(XC-900)之间的链接。 这种能力构建了一个自动编织的知识网络:
点击一个设备,能看到所有关联的维修PDF。
点击一个供应商,能看到所有涉及该供应商的历史合同和邮件通信。
我们有三种方式来使用本体中的文档数据。当文档数据成功进入Ontology并结构化后,它为前端用户(分析师、操作员、决策者)带来了全新的交互模式。
第一种:语义搜索(Semantic Search)
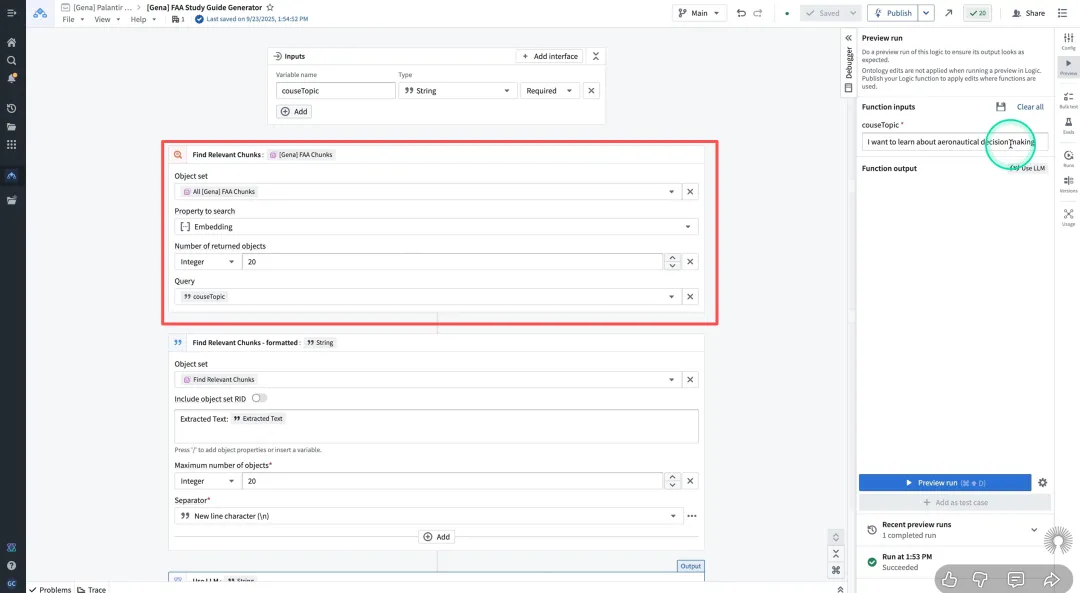
传统的文档管理系统依赖关键词匹配。如果搜网络攻击,找不到仅包含DDoS或钓鱼邮件字样的文档。在Ontology中,基于向量索引的语义搜索允许用户用自然语言提问。
用户提问: 查找所有涉及供应链中断风险的报告。
系统反馈: 即使报告中未出现中断二字,但提到了港口罢工、原材料短缺等语义相关的文档都会被检索出来,并按相关度排序。
第二种:对话式分析
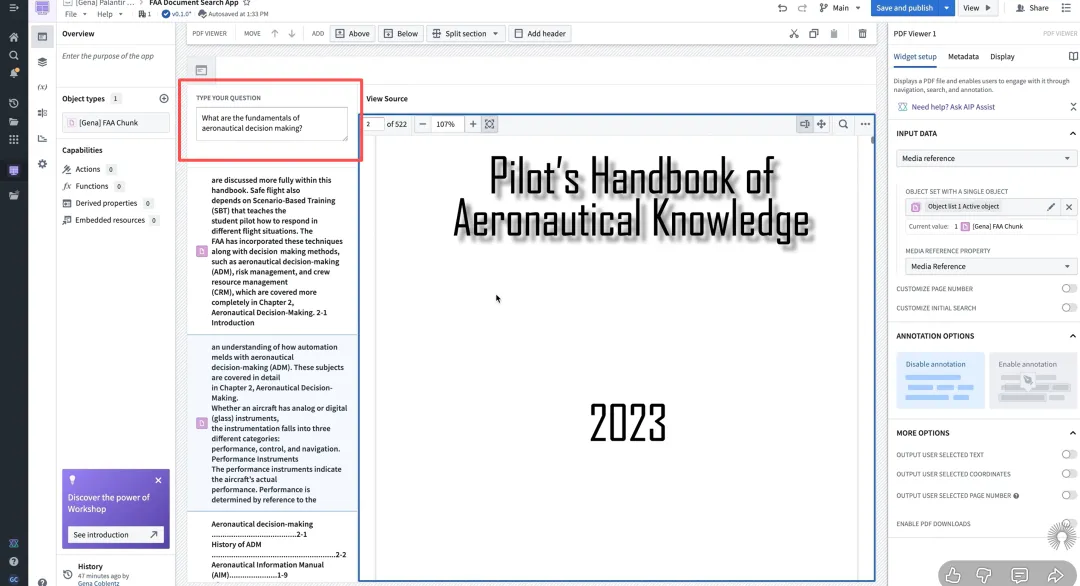
在Foundry的前端应用Workshop中,用户可以直接与文档集合对话。
场景: 航空公司的维护工程师面对数千份故障日志。
操作: 工程师在聊天框输入:总结过去一年波音737起落架的主要故障模式。
后台运行: AIP首先通过语义搜索锁定相关的数百份文档对象,然后将这些内容作为上下文投喂给LLM,最后生成一份包含引用来源的总结报告。这实现了从搜索文档到获取答案的跨越。
第三种:混合查询
Palantir的强大之处在于它能同时处理结构化和非结构化数据。用户可以构建复杂的查询逻辑:
找出所有(结构化条件:)过去7天内生产的、(非结构化条件:)质检报告中包含这种描述‘表面划痕严重’的、(关联条件:)由供应商A提供的 零部件。 这种查询能力在传统的单一数据库或单纯的文档库中几乎是无法实现的。
我们举一个具体的实际应用场景案例来看一下。
(1)金融服务:反洗钱(AML)与KYC
银行每天接收大量的客户背景调查文件。通过Ontology,系统自动阅读扫描的身份证件、公司章程和新闻报道。LLM提取出受益人信息,并自动将其与黑名单数据库中的实体进行比对。如果新闻报道中(非结构化)隐晦地提到了该客户涉嫌欺诈,语义搜索能立即触发警报,将该文档关联到客户的风险档案中。
(2)制造业:质量根本原因分析
在汽车制造中,当某个批次出现故障时,工程师需要回顾大量的测试报告和班组交接日志。Ontology将这些手写的、随意的日志数字化。当工程师调查异响问题时,系统能自动关联出某条生产线在特定日期的维修记录,发现当时机器曾进行过非标调整,从而迅速定位根本原因。
(3)医疗健康:临床试验加速
在药物研发中,历史临床试验数据大量存在于PDF报告中。科研人员利用Ontology对数百万页的过往文献进行语义检索,寻找某种副作用与特定基因标记之间的潜在联系,从而避免重复实验,加速新药上市流程。
在Palantir Ontology的世界里,文档数据不再是沉睡的档案,而是活跃的神经网络突触。通过将非结构化数据对象化、向量化并与结构化骨架深度融合,Palantir不仅仅是在做文档管理,而是在构建一个具有认知能力的企业操作系统。对于企业而言,掌握了Ontology中的文档数据处理能力,就意味着打通了物理世界(真实文件)与数字世界(决策模型)之间的最后一道屏障,真正实现了全域数据的资产化与智能化。(作者:汪小东)
