夜雨聆风
夜雨聆风链接:https://pan.baidu.com/s/15r0rLWkJlcecUvBPKZo_MQ?pwd=mnsj提取码:mnsj
https://www.mizhushare.com/docs/
在研究和数据分析中,我们关注的“结果”往往不止一个。例如:
评价学生的学习水平,会同时看语文、数学、英语;
评估身体形态,会同时看身高、体重、体脂率。
此时可能会想到,对每个指标分别做单样本t检验,但这种做法存在两个隐患:
第一,如果指标之间存在相关性,单独检验会损失“协同变异”的关键信息,无法反映多个指标的整体关联特征;
第二,多次检验会累积第一类错误,导致结论的严谨性下降。
本文将先从最基础的情形入手,即单组资料的多元均值比较:当我们只有一组样本,需同时检验多个连续指标的整体水平,与既定常模、标准或目标值是否存在差异。
示例说明:
某教育部门想检验某班级(单组,20名学生)的语文、数学、英语三门成绩(3个连续因变量),整体是否与该地区学生的常模成绩(语文75分、数学80分、英语78分)存在显著差异。

一、数据准备与转换:
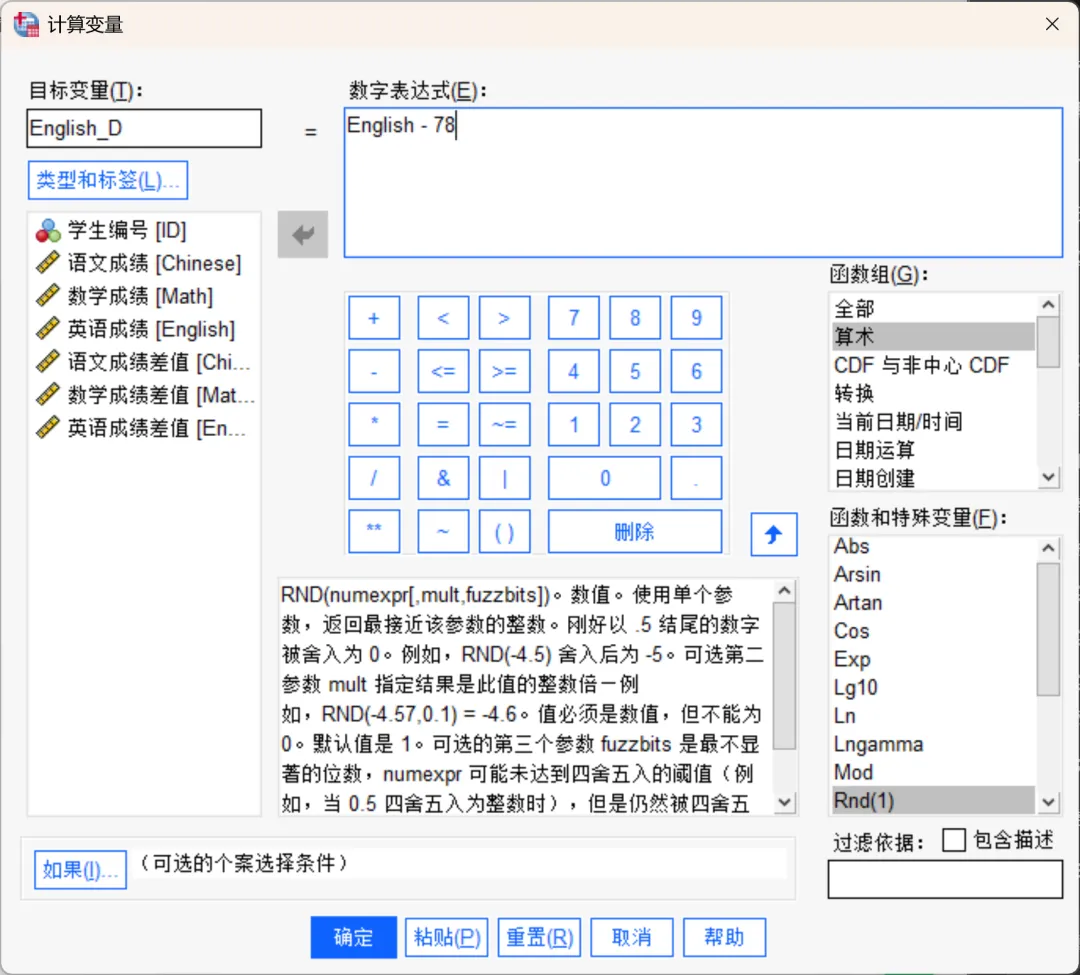
本次实验目的是检验此次成绩与该地区的常模成绩是否存在显著差异,因此需要先将每个学生的3门成绩分别减去常模成绩,得到3个新的差值变量。然后通过多元方差分析来检验这3个差值变量的总体均值是否为0,若为0,说明与常模成绩无差异;若不为0,则有差异。
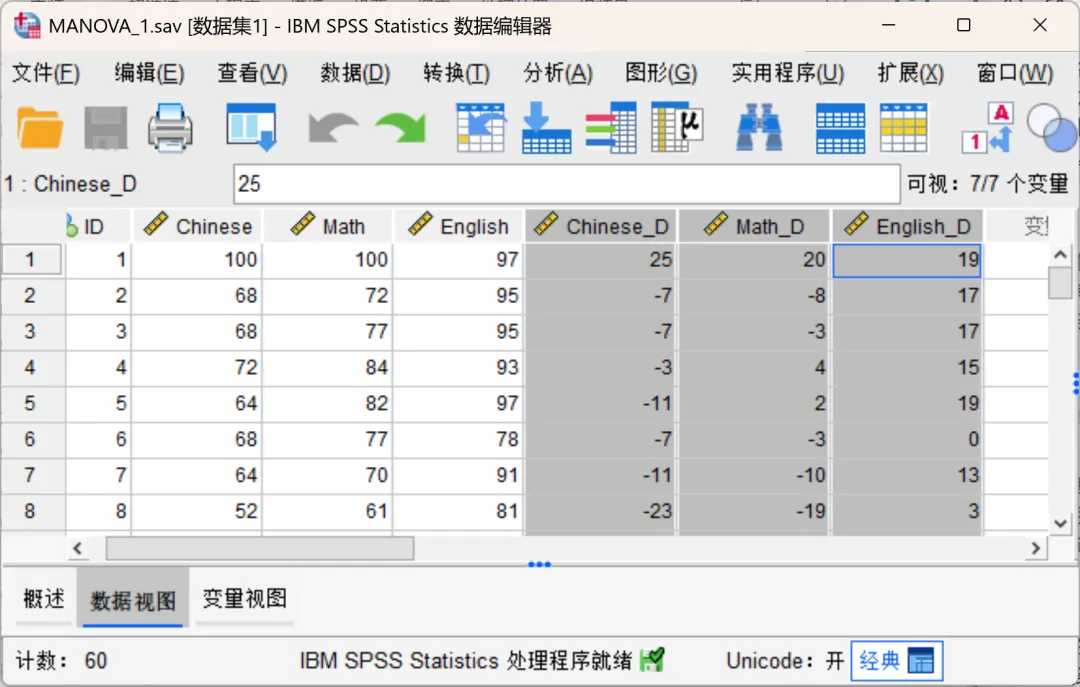
点击顶部菜单栏的【转换→计算变量】,在打开的对话框中进行相应设置,依次生成3个差值变量:
目标变量「Chinese_D」,数字表达式「Chinese - 75」。
目标变量「Math_D」,数字表达式「Math - 80」。 目标变量「English_D」,数字表达式「English - 78」。
二、方差分析:
点击顶部菜单栏的【分析→一般线性模型→多变量】,在打开的对话框中进行相应设置。
因变量:需要分析的结果变量。
固定因子:样本中所有可能水平都出现的分类变量,用于将总体划分为不同的组。
协变量:用于控制额外的连续型混杂因素。
WLS权重:用于指定一个权重变量,以进行加权最小二乘法分析。如果权重变量的值为零、负数或缺失,则该个案将从分析中排除。模型中已使用的变量不能用作权重变量。
本次将3个差值变量设置为因变量。本次示例数据为单组资料,因此没有固定因子。
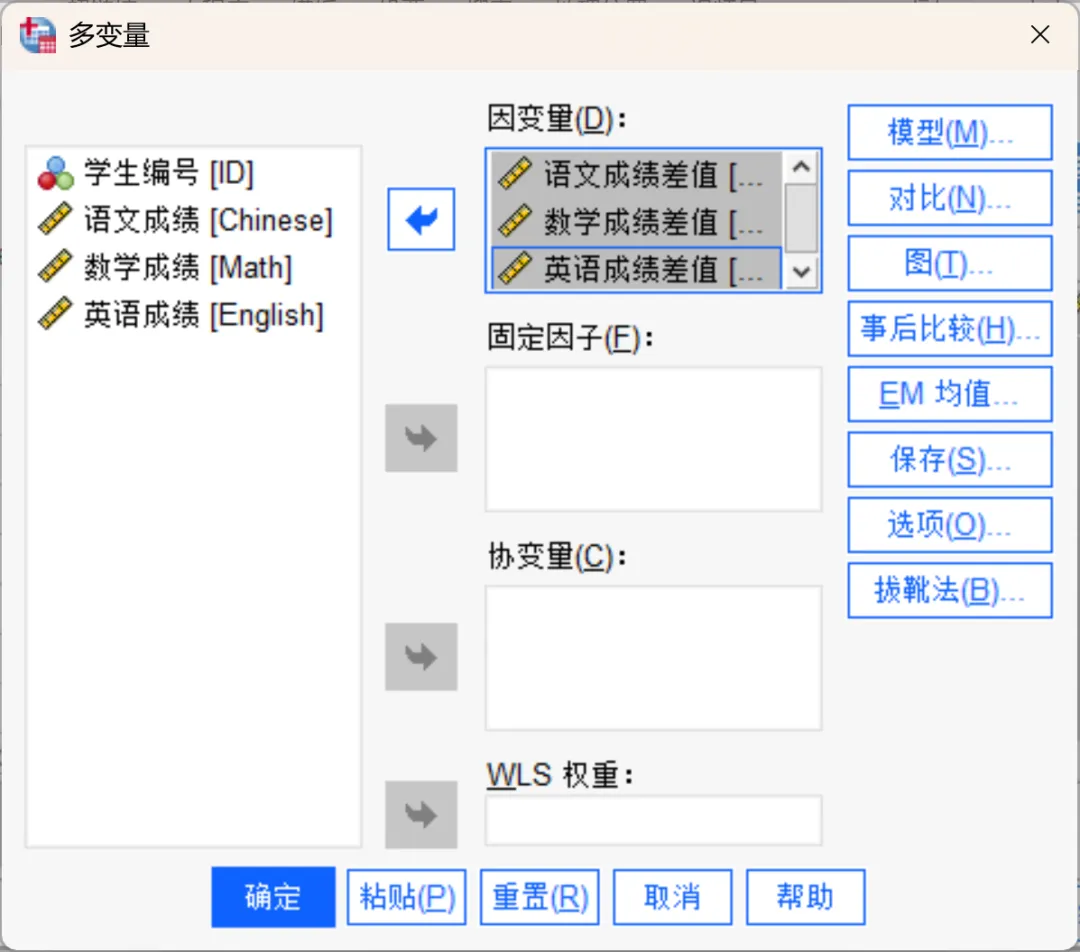
设置完成,点击确定。

系统将会输出一系列结果。
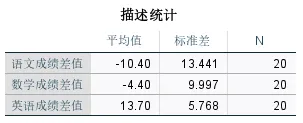
输出结果一:描述统计
这张表列出了各组原始的均值、标准差和样本量,有助于直观了解数据分布情况。
本次示例中,样本学生语文、数学平均分比常模成绩低,英语平均分比常模成绩高。另外,英语差值的标准差最小(5.768),说明英语成绩与常模的差值在学生之间的波动最小,语文的波动最大。但这种偏离是否具有统计学意义,需要看后续检验结果。
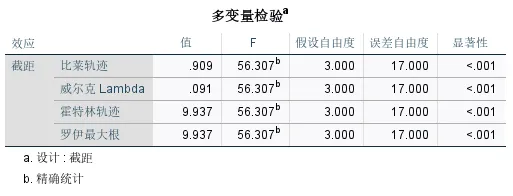
输出结果二:多变量检验
该表是多元方差分析的核心检验结果,用于判断整体差异是否存在。因为本次示例数据为单组资料,因此只输出截距检验,用于检验“所有因变量的均值是否同时为0”。表中提供了四种检验统计量,最常用使用威尔克Lambda (Wilks' Lambda)统计量。
本次示例中,显著性P值<0.001,拒绝“均值向量为0”的原假设,说明整体上,样本学生的3门科目成绩与地区常模存在显著差异。
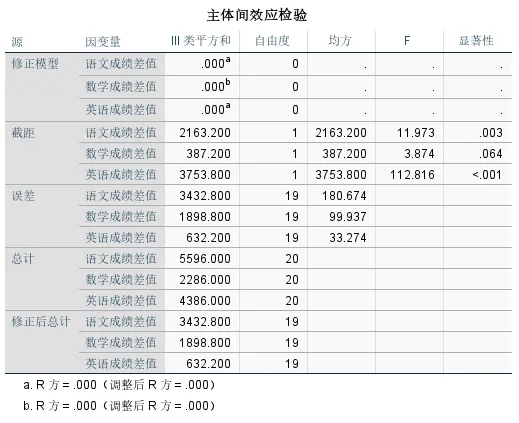
输出结果三:主体间效应检验
整体差异显著后,我们需要看哪一门科目与常模成绩有显著差异,主体间效应检验表的作用就相当于“单科目单样本t检验”。
本次示例中:
样本学生的语文成绩与常模成绩存在显著差异,结合描述统计的均值(-10.40),说明样本学生语文成绩显著低于地区常模。
样本学生的数学成绩与常模成绩不存在显著差异(虽然均值为- 4.40,但差异未达到统计学显著水平)。
样本学生的英语成绩与常模成绩存在显著差异,结合描述统计的均值(13.70),说明样本学生英语成绩显著高于地区常模。