 夜雨聆风
夜雨聆风我把一套读不动的国产软件文档,喂给 AI 变成了一座随问随答的知识库
一、8 本手册、22 万行、22 个分身
8 本手册,约 22.3 万行文字,约 2900 张图。这套文档大到什么程度?我连 AI 都喂不进去。最后我把它拆成 22 个 AI 分身,并行去读,才算把它读完,攒成了一座能随问随答的知识库。
我做的是个很专业的工程仿真项目。说白了,就是给一栋非常复杂的真实建筑算抗震,计算量大到吓人。用的软件叫 GFE,是广州颖力科技的国产有限元软件。具体是哪个领域不重要,重要的是:一个做到这种专业程度的人,照样能被一堆文档活活绊住。
你要是用过任何一款专业软件,多半懂这种憋屈:手册八九本,每本几千上万行,图几百上千张。你想查的那个参数、那个函数,明明就躺在里面,可你翻不到,也根本读不完。
这套文档更难缠,因为它是两种完全不一样的东西硬拼起来的。
一种是 PDF 手册。8 本,按主题各成一册。光手册这一摊就大到读不动,转成 Markdown 后总共约 22.3 万行、约 2900 张图。其中"实际案例操作"那一本就 13 万多行,是个巨无霸,单一章都上万行。
另一种是反编译出来的命令流接口。GFE 的"命令流"不是普通脚本,而是软件内嵌的一套 Python 程序接口。这套东西官方文档里查不到,是靠反编译加实测一点点抠出来的,里面甚至藏着手册上根本找不到的隐藏命令。
两套知识,一套讲"某功能怎么用、某参数怎么取",一套讲"某命令流函数怎么写",偏偏不在一处。我查这边再查那边,来回割裂。
更要命的是,这个体量不光人翻不动,AI 也读不进去。22.3 万行 Markdown 粗算下来是几百万 token 量级,远远超过一次能稳稳塞进去的上下文。就算硬塞,读这么长一段,读到后面也开始丢前面,精度直接塌。所以单个 AI 压根读不完,最后我只能拆成 22 个分身一起上。
那怎么办?办法就在开头那句:把这堆零散文档,编译成一座 AI 能检索、还互相挂钩的知识库,等于给我自己、也给 AI,配了一个随问随答的"GFE 大脑"。下面是它怎么一步步建起来的。文末我留了 7 条能直接搬到你自己专业里去的经验。
二、这座库是个啥:让 AI 当图书管理员
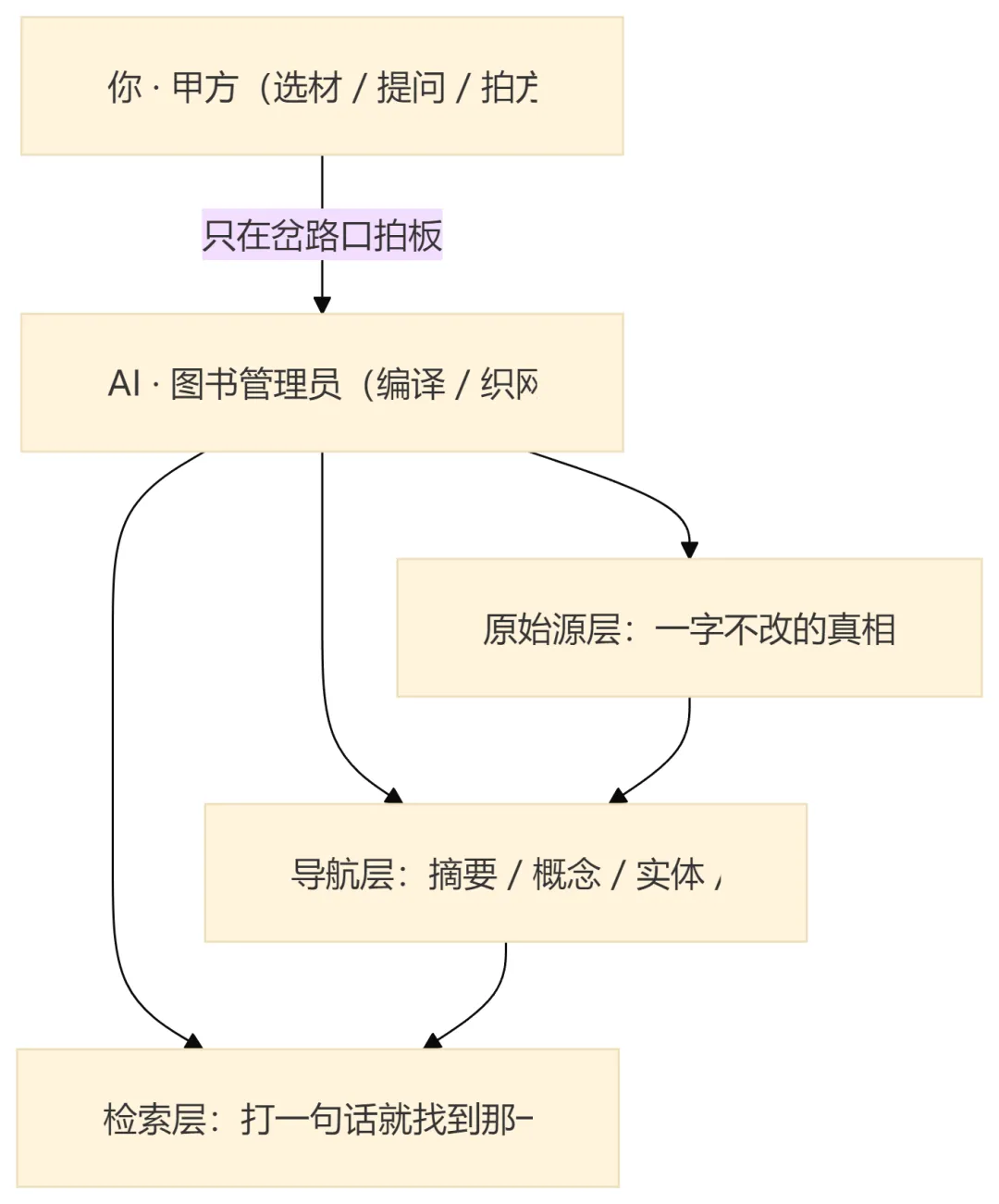
它不是一个普通笔记本。它遵循 Andrej Karpathy 提的 LLM Wiki 范式。
这个范式说白了就是:AI 负责把原始资料编译成结构化、互相挂钩、持续维护的知识库;人负责选材、提问、判方向。人几乎不动手写内容。
打个比方(这是我的类比,不是原始定义):人是甲方,只管提需求、拍方向;AI 是图书管理员,所有把书拆开、归类、编目、互相挂钩的体力活,全归它干。

2.1 三层结构
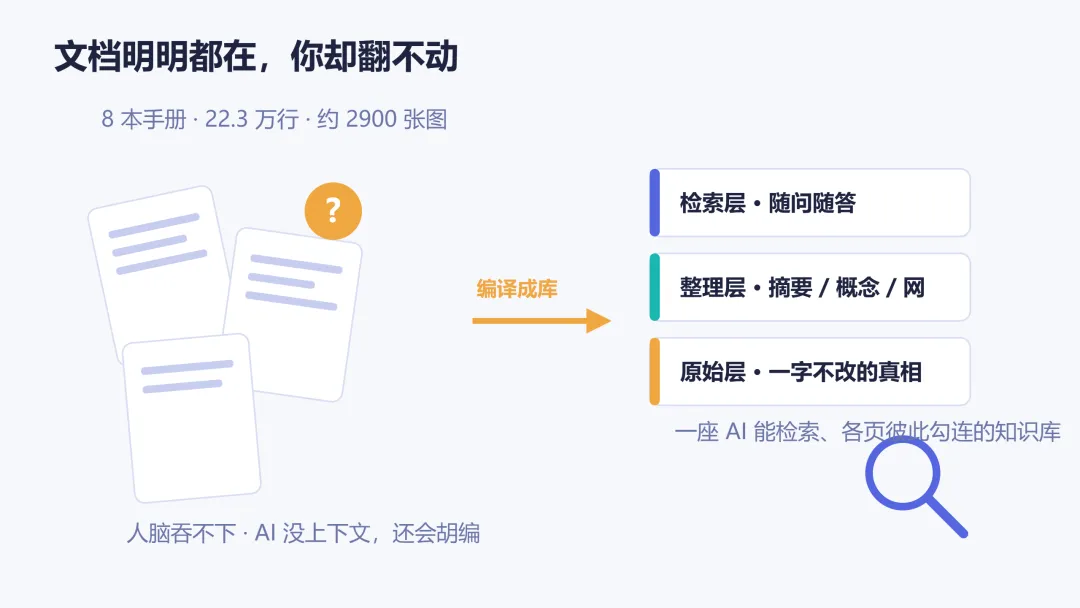
这座库分三层,各管一头:
原始源层(不可改):这是"真相来源"。原料怎么进来就怎么存着,绝不动它一个字。 导航层(AI 加工出来的产物):这是 AI 编出来的索引层,又分四类,摘要、概念、实体、跨文献综合。 检索层:让上面两层"能被查到"的机制。
为什么要分这么清楚?因为这三层的脾性完全不同:原料是动不得的底盘,导航层是随时能推倒重编的产物,检索又是另一套机制。要是混在一起,迟早乱成一锅粥。
(另外还配了三个管账的文件:一份内容目录,一份只能往后加、不能改的流水账,还有一份规定"每类页面该长什么样"的规范。)
2.2 连接比内容值钱
这座库和普通笔记本最根本的区别,是它特别看重"连接"。原文的说法是:连接比内容值钱。页和页之间靠双方括号链接 [[...]] 织成一张网。
这里有个特别反直觉、也特别关键的设计:就算你指向一个还不存在的页,也照样写下去。这不是错,这叫"生长边",它在标记"下一步该建的节点"。库就是靠这些悬空的链,知道自己往哪儿长。
2.3 检索层:怎么就"搜得动"了
光有一张网还不够,得能查得动。我先大白话讲一遍,再上术语。
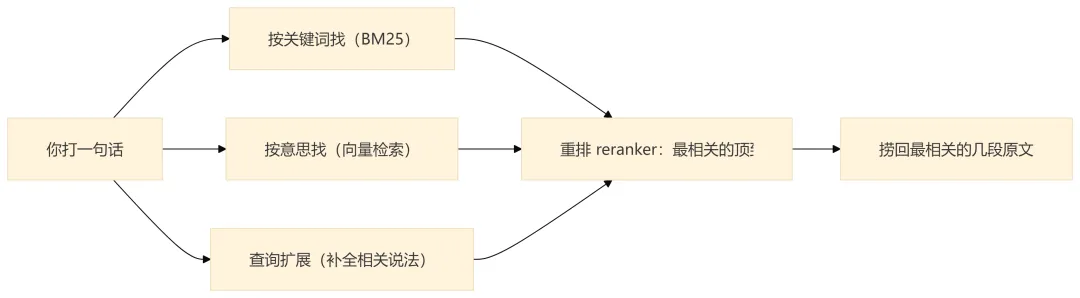
检索,就是你打一句话进去,库帮你把最相关的几段原文捞出来。可"相关"两个字怎么算?这座库不只用一种办法,而是好几种办法叠着用,叫混合检索:
按关键词找(术语叫 BM25):像 Ctrl+F,但更聪明,它会照顾词频和稀有度,专找你字面上提到的词。 按意思找(术语叫向量检索):哪怕你用的词跟原文不一样,只要意思相近也能找到。它怎么做到的?靠下面要讲的"向量化"。 查询扩展:你问得太短的时候,系统帮你把问题"补全"几个相关说法再去搜,免得漏。 重排(术语叫 reranker):把上面几路初选出来的结果,再排一遍队,把最相关的顶到最前头。
这里得说清楚:这篇文章只做了少量真实查询的"冒烟测试",就是看看这玩意儿点不点得着火。我没有单独验过"重排""查询扩展"这两步各自起了多大作用,它们是配上了,但没做消融评测。所以下面看到的命中分数,你就当成"这套组合到底管不管用"的整体信号,别当成某一路的功劳。
"按意思找"的核心是向量化。向量化,就是把每段文字翻译成一串数字坐标;意思相近的文字,坐标也挨得近。于是"找相似"就变成了"找坐标最近的点"。这一步由一个叫"嵌入模型"的东西来干(这篇用的是一块够强的 GPU 跑一个开源嵌入模型,具体型号叫 Qwen3-Embedding-8B,对外行就是噪声,跳过无妨)。
还有一个词全文反复出现,叫 chunk:就是把长文切成的一小段一小段。库不是整篇整篇地塞进检索,而是切成小段,每段单独向量化。这样你问一个细节,它能精准捞到那一小段,而不是甩给你一整章。
开工前,这座库里已经躺着 8 篇专业研究论文,这是已有的底子。后面新进来的手册和命令流,都得往这张老网上挂。
简单收一下这套世界观:原始源是真相,导航层是索引,检索层负责把它们查出来;连接比内容值钱,生长边是特性不是 bug。后面整个过程,都在这套设定里跑。
三、第一仗:8 本手册、13 万行案例,怎么一口吞下
3.1 先摸家底:原料已经是 Markdown 了
第一件事是摸清家底。好消息是,8 本手册早就用本地工具转成了 Markdown,每本一个文档加一个图片目录,不用重转。
家底里有两个巨无霸值得点名:"实际案例操作"那一本,13 万多行、700 多张图;"显式求解器"那一本,图也接近一千张。8 本加起来约 22.3 万行、约 2900 张图。
3.2 两个岔路口,交给我拍板
AI 干体力活归干体力活,可一碰到方向性的选择,还得人来定,保持人在环,是这座库自己定下的规矩。这一仗就有两个岔路口扔给我拍板。
岔路一·案例手册怎么拆:那本 13 万行的案例手册,只做成一页摘要太粗了,等于没读。我拍板:按工程案例拆成 15 个子页,再加一页总览。 岔路二·图片要不要:约 2900 张图,留还是不留?我拍板:全部复制进库。理由很实在,向量检索只吃文字,图根本进不了检索;复制图纯粹是为了人翻的时候能看见它。(这也是这套方法眼下的一个硬边界:对一套图特别密的软件文档来说,把图全挡在检索之外、只留人眼看,是实打实的信息损失,后面还会再提。)
3.3 头一个坑:现成脚本的"地址格式"对不上
真动起手来,第一个坑就来了。现成的入库脚本只认一种图片写法:图片链接里不带斜杠、图就放在文件夹根目录。
可这批转出来的产物是另一种写法:图片链接带子目录前缀、图放在 images/ 子目录里。格式对不上,脚本跑不通。
破法是改写一个适配脚本,让它认出带子目录的写法,把图片链接重写成库内的相对路径,再从原目录把图拷过来。一把跑通,8 本原料全部落地,图链全改,约 2900 张图复制到位。
3.4 第二个坑:派 22 个 AI 分身一起起草
入库门槛扫清了,下面是这一仗的关键一步。
问题是:体量太大,单个 AI 读不完。案例手册一章就上万行,让一个 AI 从头读到尾不现实,既超上下文,又会读到后面忘了前面。
方案是:同时拉起 22 个互相隔离的 AI 分身。怎么分的?7 本手册各派一个,那本巨无霸案例手册按章拆成 15 个,合起来正好 22 个。每个分身负责的行范围都预先精确算好,互不重叠。
每个分身就干三件事:
只读自己那一段(碰上超大章节就抽样关键节,不通读、不读图); 自己写自己那一页摘要(每个分身独占一个文件,文件名互不重复,绝不打架); 结构化返回它建议建立的概念、实体、交叉链提案。
这里有条关键的分工判据,后面会反复用到:独占文件的,可以放手并行;共享的网,绝不能并行写。摘要页各写各的没问题;可概念页、实体页是大家共享的,要是放任 22 个分身同时往里写,必然打架,所以它们只"返回提案",由主控的那个 AI 一个人集中策展、建网。

战果:22 个分身全部成功,约 7 分钟跑完,烧掉 183 万 token。
主控 AI 也没闲着。趁分身在跑,它先把几个"名字绝对不会变"的枢纽页写了,比如全库入口实体、软件厂商实体。名字定死了的,先落定,省得后面返工。
四、最硬的坑:AI 自己起的名字对不上
整个过程里最该讲的就是这个坑。
4.1 问题:同一个东西,三种写法
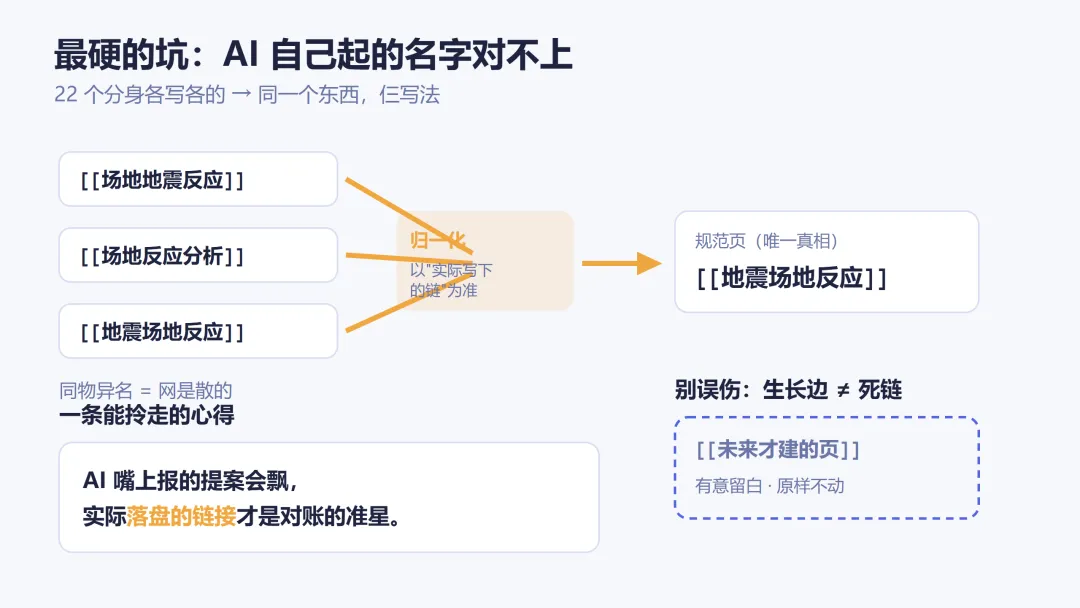
22 个分身各写各的,谁也不知道别人怎么命名。结果就是,它们写下的 [[链接]] 名字冒出了一大堆变体,而且横跨手册、案例、概念三类,每类都有:
同一本手册:有的写全称、有的写简称,对不上同一个规范名; 同一个案例:两个不同的链名,指的其实是同一个案例; 同一个概念: [[场地地震反应]]、[[场地反应分析]]、[[地震场地反应]],三种写法、三个不同的页,可它们说的是一回事。
链名一乱,网就织歪了:本该连到一处的,散成了三处。
4.2 破法:不信 AI 自己报,只认实际落盘的链
最容易想到的办法,是去翻每个分身返回的提案,它们不是都"建议"了概念和链接吗?
可这条路是错的。AI 自己报的提案会飘:它说它建了什么链,跟它实际写进文件的链,未必对得上。
正确的破法分四步:
不信分身返回的提案清单; 用 grep 把所有页里"实际写下"的 [[链接]]全抓出来,把这个当唯一真相(grep 就是在一堆文件里搜文字的命令行工具);对这些真实链接统计频次,据此建一张归一化映射表(哪个变体归到哪个规范名); 用自写脚本跨 20 个文件批量改写。
改写有两种方式:一种是直接替换;另一种是别名替换,保留原来的显示文本,比如把 [[B31单元]] 改成 [[梁单元|B31单元]],链接归一到"梁单元",但读者看到的还是"B31单元"(B31 是有限元里梁单元的常见代号,这是我的补注,不是原文解释)。
4.3 关键判断:只修"同物异名",留住"生长边"
这一步最见功夫的地方,是不把所有"对不上的链"一刀切当成 bug。
第二章说的"生长边",有些链指向的页确实还不存在,但那是故意的,它标记着未来该建的节点,是库自己定下的规矩,不是错误。
所以归一化的时候要分清两种:
故意留的生长边(指向未来该建的页):保留不动; 同物异名的真错链(同一个东西被起了好几个名):才修。
4.4 一条带得走的方法论
这一仗逼出了一条方法论:AI 自己报的不可信,落盘的才算数。对账的基准永远是实际写进文件的内容,而不是 AI 嘴上说它做了什么。
五、把零散的页连成一张能查的网
分身们交回了一堆"提案",可网还没织好。这一步,是主控 AI 一个人坐下来集中策展。
5.1 为什么共享页非得一个人来策展
那条判据这次落到了实处:摘要页每个分身独占一个文件,零冲突,可以放手并行;但共享的概念页、实体页,绝不能让分身并行写,会打架。让它们只返回提案,由主控 AI 一个人集中建网。
5.2 生成概念与实体,挂上老网
主控 AI 用一个数据驱动的生成器,批量产出了 30 个概念页 + 5 个实体页。概念覆盖求解、场地、接触、单元、本构、隔震、施工这几族;实体是软件本身、厂商、还有几款相关软件。每一页都带定义、"在本库中的位置"、以及互链。
关键是,这些新页挂接进了开工前就有的那 8 篇论文的老网,比如某个场地反应概念连到对应的边界条件概念和那篇引证论文,某个本构概念连到对应的土体本构页,多个案例连到对应的结构耦合概念。
新手册和老论文,就这样织进了同一张网。随后主控 AI 写了案例总览(15 个案例按主题分组),更新了目录和流水账,还在库的规范里新增了"手册""案例"两种页类型。
最后做一次全库链路审计(用脚本跑,不靠编辑器开着):所有源链都能解析,剩下的悬空链全是故意留的生长边。也就是说,没有一个是写错的,悬着的都是刻意留白。
5.3 向量化:让网"能查"
网织好了,接下来让它"能查",也就是第二章讲的"把每段文字切成小段、翻译成坐标"。
这里有个必须记住的工程细节:在 Windows + CUDA 环境下,向量化的并行度必须设成 1,否则会崩。(为什么会崩,我没深究;这是在这套嵌入模型 + 这版检索引擎下踩出来的经验值,换模型或换平台未必复现,是个体经验、不是普适机理结论——遇到崩先往这儿排查就好。)
这一批的产出是 3434 个 chunk(也就是 3434 个小段),耗时约 10 分钟。跑完之后,全库从开工前的 34 个文档,涨到了 100 个文档。
5.4 冒烟测试:到底查不查得动
库建好了,最后得验一下到底查不查得动。这只是开机冒烟,确认这套东西能着火,不是严格评测。下面那些百分比是 qmd 返回的综合相关度分(几路检索融合后归一的分),只能横着看个大概,别当精确成绩。我抛了两个真实问题:
Q1「显式动力下某个阻尼参数为什么要置 0、质量缩放怎么回事」,命中用户手册原料,相关度 85%; Q2「地铁站抗震分析步骤」,同时命中对应手册原料 86% 和某个案例页面 80%(这两个分数是同一个问题的两个命中页)。
命中是对路的。这一仗的最终产物:23 篇摘要(7 手册 + 15 案例 + 1 总览)+ 30 个概念 + 5 个实体,全部向量可检索。
六、第二仗:把命令流也喂进去(顺手撞上一场并发)
第一仗刚收尾,我直接甩出下一个任务:把命令流知识库也消化进同一座库,核心是命令流的语法、规则和用法。
6.1 这回的原料不一样
跟手册不同,命令流知识库不是 PDF,而是反编译加实测攒出来的。它分四个子目录:接口规格与文法(核心,含手册查不到的隐藏命令)、案例反推、工具脚本、还有一批机器导出的模型状态 dump。
6.2 这回的决策:敢砍噪声
这一仗的决策方式跟第一仗不一样。因为用户已经把话说明白了,"核心是语法规则 + 用法",所以主控 AI 直接定、不打扰用户,但把理由讲清楚、并且随时可以回退。
纳入:接口规格全部 + 案例反推的 Markdown + 工具脚本 + 索引 + 一个真实工程的小型管理脚本(当成可照抄的范例); 跳过:那批机器导出的巨型坐标 dump(纯噪声,会污染向量),还有两个跟已入库内容重复的全文文件。
判断的原则是:向量库的信噪比,比"全都要"更重要。
6.3 第三个坑:检索引擎只吃 Markdown,原料却是别的格式
新坑:检索引擎的原料集合只索引 Markdown 文件。可命令流的金子,是接口规格(纯文本)和工具脚本(代码文件),格式对不上。
变通办法是给它们"穿上 Markdown 外衣":写一个装配脚本,把这些源料包成 Markdown,代码包进代码围栏,纯文本加上来源头注。这样既进了库,又能被检索。
6.4 第四个坑:和官方手册"互补不重复"
这里有个定位问题:库里已经有官方命令流手册的页了。这套反编译 KB 要是另起炉灶,就重复了。
定调:手册讲"文档化命令",本 KB 补"反编译全签名 + 隐藏命令 + 真实工程反推",两者互链,不重复。
也正因为这 6 个新页内容高度耦合、要精准互链,这回主控 AI 亲自写、不派分身,直接成稿比并行更连贯(只有第一仗那种大批量、各自独立的摘要才适合并行)。这 6 页是 4 个手册页 + 2 个概念页(一个讲核心建模范式,一个讲各对象怎么相互引用)。
6.5 第五个坑:撞上一场真实的并发
接下来出了一段意外。
就在我建库的同时,另一个会话正并行往同一座库里灌 31 篇核心文献。两个会话同时写一座库,冲突立马就来了:目录文件和流水账被外部改动,我这边的写入因为"文件已变"而失败。
破法是:改成先重读、再追加。好在流水账是只追加、不修改的,天生就能共存。
意外收获是:我早先标的一些"生长边",被那批文献会话悄悄补成了真页,网反而更全了。这是一次真真切切的多 AI 并发协作,库在我脚底下自己长大了。
6.6 收尾:向量化与冒烟
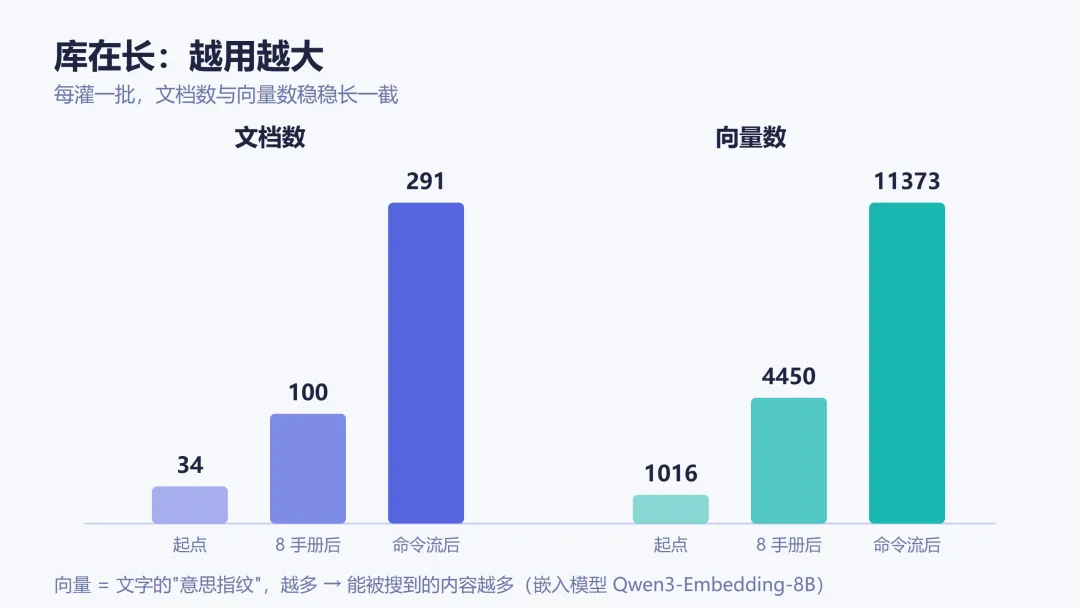
更新目录、6 个新页链路审计 0 断链,然后重新向量化(这次连那个并发会话灌进来的文献也一起跑了)。全库累计达到 291 个文档,从开工前 34、到第一仗后 100、再到这里 291,一条清清楚楚的成长曲线。
(向量化的时候,单次嵌入的批量数会随当时库里待处理的内容浮动,跟上面"34→100→291"这条累计曲线不是一回事。前者是"这一锅煮了多少",后者是"锅里一共有多少",看的时候别混。)
最后做三组冒烟,验证两套知识真的织到了一起(同样是综合相关度分,只看个大概):
Q1「命令流建绑定约束引用哪个集合」,对象引用原料 80% + 对象引用概念页 + 绑定约束概念页,同时浮现; Q2「某个地震荷载输入参数」,命令流手册原料 80% + 对应手册 + 案例; Q3「实时桥怎么驱动软件界面」,桥与工具页 79% + 工具原料 + 概念页。
新 KB 和老网同时命中,网织成了。
6.7 一个有分量的闭环:那个真实工程,正是我自己的项目
这一段能堵住"你这套是不是纸上谈兵"的质疑:第二仗里反编译解析的那个真实工程,正是我开头说的那个项目本身,39 层上部结构、十几层分层土、桩基础、人工边界、三向地震、分步求解,全都对得上。
它成了"各个案例范式怎么收口到一个真实工程"的活样板,库里讲的所有抽象命令,最后都能在这个真项目上对上号。抽象的命令流,最终落到了一个真真切切跑过的工程上。
七、给自己建一座 AI 知识库的 7 条经验
这两仗打下来,方法能拧成 7 条。每条我都先给一句脱离我这个项目的"通用判据",再用我的实例当例证,这样你给法律文书库、医学文献库、API 文档库搭知识库时,能直接对号入座。
经验①:原料 / 导航 / 检索三层分离
通用判据:把"不可改的原始真相""可以推倒重编的索引""负责查找的机制"分成三层,各管一头,别混在一层。
我的例证:约 2900 张图全部复制进库,但向量检索只吃文字,图纯粹是给人翻的,各取所需。(也正因为这样,图里的信息暂时进不了检索,这是这套方法眼下的硬边界,得认。)
经验②:人定方向,AI 编译
通用判据:人只在岔路口拍板,切多细、留哪些料、圈多大范围;岔路口之外的体力活全交给 AI,而且人随时能掉头。
我的例证:13 万行案例拆 15 页、图片全复制、命令流只要语法用法,这三个方向是我定的;其余 AI 干。
经验③:独立产物放手并行,共享网集中策展
通用判据:判断一份素材是"独占"还是"共享",就看它会不会被好几个写手同时改。每人产出各自独立的文件,可以放手并行;大家共用的那张总网(索引、概念、实体),必须一个人集中维护,不然一起写就打架。
我的例证:22 个分身能并行,是因为摘要页各占一个文件;概念页要主控 AI 一个人写,正因为它是共享的。第二仗那场并发就是反面教材,两个会话同写一座库的共享目录,立马冲突,只能"先重读再追加"。
经验④:以"实际写下的链"为对账真相
通用判据:验收 AI 的活,别信它自己汇报做了什么,要去抓它真正落盘的产物来对账。
我的例证:grep 出真实写下的链、统计频次、建归一化映射、批量改写,根子就是"只信落盘、不信自报"。
经验⑤:生长边是特性不是 bug
通用判据:允许内容指向"暂时还不存在的条目",把它当成"待办的占位",不是错误;清理的时候只合并"同一个东西的不同叫法",故意留的占位别动它。
我的例证:那些指向未建页的链是故意留白;第二仗里它们被并发会话补成了真页,正是价值兑现的时候。
经验⑥:同题新源做互补,别另起炉灶
通用判据:新料如果跟已有条目讲的是同一个东西,就把它定位成"补充另一个维度"并互链,别再开一个平行的新条目。
我的例证:官方手册讲"文档化命令",反编译 KB 补"全签名 + 隐藏命令 + 真实工程反推",两者互链,冒烟检索里新旧知识同时命中。
经验⑦:噪声要敢砍,信噪比优先
通用判据:不是所有原料都值得进库;机器导出的、重复的、对检索没意义的,当机立断砍掉,检索库的信噪比,比"全都要"重要。
我的例证:那批机器 dump 直接跳过,纯噪声只会污染向量;但接口规格、工具脚本、真实工程范例一个不落。"敢砍噪声"和"敢留金子"是一体两面。
八、这座库往后怎么活
这座库不是建完就定型的死库,它会随用随长。
它怎么长的,第二仗已经演过了:另一个会话灌进 31 篇文献的时候,我早先留的那些生长边被悄悄补成了真页,网自己变得更全。检索这一头也能一直滚下去,每次新增内容,更新、嵌入一跑,规模就往上走。从开工前的 34 个文档,到第一仗后的 100 个,再到第二仗后的 291 个,一条清清楚楚的成长曲线。
(一句方法论引申:按这座库的设计,将来好的查询答案也可以回填进跨文献综合页,让库越用越聪明。这是它结构上支持的下一步,不是已经发生的事。)
它还有另一个脾气,是人随时能掉头。第一仗收尾后,本该进入一轮针对真实建模决策的逼问,刚抛出第一个问题,我一句"不用拷问我了"就掉了头,转去建下一座库。人在环的价值正在于此:AI 干所有体力活,可方向盘始终攥在人手里。
最后说回开头那个憋屈。专业软件文档又多又散、人翻不动、AI 也读不进去,这不是某一家软件的毛病,几乎每个专业领域都有自己那一堆"读不动的文档"。比如你手上攥着一堆 API 文档加源码注释,照样能这么干:原始源存真相、grep 落盘对账、按意思检索、留住生长边,领域换了,骨架不变。
这套方法的内核很简单:让 AI 当图书管理员,把你那一堆零散原料编译成一座互相挂钩、能被检索、还会自己生长的知识库;你只管选材、提问、拍方向。原料存真相、导航织网、检索管查找;独立的放手并行、共享的集中策展;只信落盘、敢砍噪声、留住生长边。
你要是也有一个读不动的专业领域,这座会生长的"领域大脑",你也能给自己建一座。
