 夜雨聆风
夜雨聆风
编者按
每年 11 月,郑州供暖季来临之前,郑州市民卡 APP 都会迎来一场“硬仗”——暖气费优惠券抢领活动。优惠额度大约 200 元,对于普通家庭来说,这是一笔实打实的节省。
但每当活动上线,大量新老用户同时涌入,系统便开始告急:个人信息加载失败、页面白屏、投诉量激增……对亚信科技高级工程师董明放来说,这是一年一度的“噩梦时刻”。而这一切的根源,都指向了同一个问题——MySQL 主从架构已经不堪重负。

亚信科技高级工程师董明放分享数据库优化实践
/一个市民生活 APP 的数据库困境/
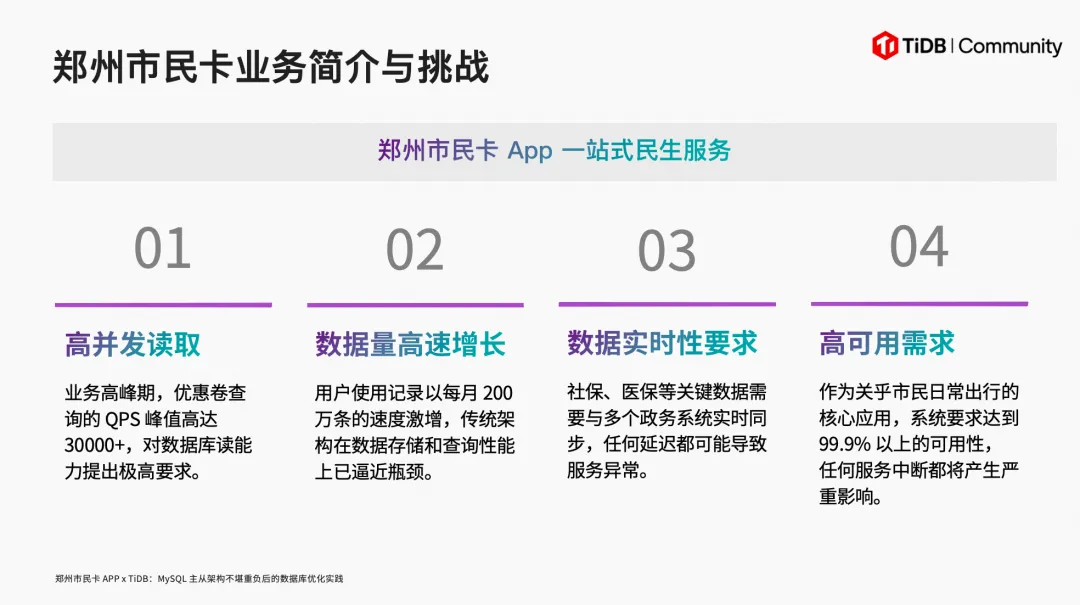
郑州市民卡 APP 是响应国家提振内需政策开发的惠民应用,用户只需持有郑州社保卡即可使用。经过多年发展,APP 的功能已覆盖公积金查询、养老查询、社保卡激活、交通出行、电动汽车充电、跑腿服务、旅行等多个生活场景。
董明放从 2019 年开始接触 TiDB,至今已有七年以上的深度使用经验。他坦言,最初系统上线时用户量不大,一个 MySQL 数据库完全可以扛住。但随着用户增长到 200 万级别,问题逐渐暴露:
第一,高并发场景下数据库性能不足。抢券活动带来瞬时高并发,MySQL 无法承受,导致用户体验急剧下降。
第二,主从延迟导致数据不一致。APP 对用户实行分级管理——手机号注册为一级用户,实名认证为二级,绑定社保卡为三级。但在 MySQL 主从架构下,高峰期复制延迟严重,用户状态已变更却无法同步到从库,导致用户等级显示错误,直接影响抢券资格。
第三,扩展困难,业务侵入大。MySQL 主从架构只能扩展从库,如果要分库分表,对业务的侵入性非常大,且扩容操作并不方便。
第四,高可用性不足。MySQL 主节点一旦故障,需要人工介入将从节点提升为主节点,切换期间前端 APP 完全不可用——这对面向市民的公共服务来说是不可接受的。
/为什么选择 TiDB/
经过技术选型和压测评估,团队最终选择 TiDB 作为替代方案。董明放从架构层面总结了 TiDB 的核心优势:
计算存储分离,弹性扩容。TiDB 采用 PD(管理节点)、TiDB Server(计算节点)、TiKV(存储节点)三层架构,计算和存储完全解耦。TiDB Server 可通过 SLB 负载均衡随时扩容,TiKV 也支持在线扩容,但需关注 Region 均衡策略。
分布式架构,消除主从延迟。TiDB 天然分布式,不存在传统主从复制延迟问题,用户状态变更后立即可查,抢券体验大幅提升。底层存储方面,TiKV 以 96MB 的 Region 为基本存储单元,数据自动分片分布,无需像 MySQL 那样将所有数据存放在单个文件中。 高可用,自动容灾。 TiDB 采用多数派协议,三副本模式下挂掉一个节点不影响服务,五副本模式下挂掉两个节点仍然正常。TiDB Server 本身无状态,只要还有一个节点存活就能对外服务。
完善的工具链。TiDB 提供 TiUP(集群部署管理工具)、Dashboard(监控诊断)、Prometheus + Grafana(可视化看板)、DM(数据迁移工具)、TiCDC(变更数据捕获)等全套工具,通过 TiUP 一键部署,大幅降低运维复杂度。
/迁移实施:从 MySQL 到 TiDB 的完整路径/

数据迁移:DM 工具全量 + 增量同步
团队使用 DM(Data Migration)工具完成数据迁移。DM 采用“全量同步 + 实时增量同步”模式,MySQL 和 TiDB 两边保持实时同步,切换时仅需短暂停机。
同时,TiCDC 工具支持将变更数据同步回 MySQL、Kafka 等多种目标端,相当于为迁移上了一道"双保险"——万一切换后出现问题,可以快速回切。
迁移完成后,团队还使用 sync-diff-inspector 工具进行了全量数据库校验,确保数据一致。
迁移前:充分的预演
团队在预发环境反复进行压力测试和迁移演练,验证各环节的可靠性后再执行正式迁移。董明放强调:“切换数据库时,先在预发环境上反复进行压力测试和迁移预演,保证迁移时不出问题。”
/生产环境的深度优化/
混合部署与内存调优
受限于硬件资源,团队采用了 PD、TiDB Server、TiKV 混合部署的策略。混部最关键的问题是内存分配——TiKV 默认会占用所在主机 45% 的内存用于 Block Cache,在混部场景下必须手动调整。
董明放的实践方案是:先将内存一分为二,分别留给 TiDB Server 和 TiKV,再按分配给 TiKV 部分的 45% 设置 Block Cache,防止 TiKV 内存占用过高导致 TiDB Server 被 OOM Kill。同时建议使用 Numa 绑定,防止组件间资源争用。
热点问题:从自增 ID 到 Auto Random
TiDB 底层采用 KV 存储结构,如果沿用 MySQL 的自增主键,数据写入会集中在一个 Region 上,产生严重的热点问题。解决方案是使用 AUTO_RANDOM 或自定义分片策略,将热点数据分散到不同 Region,写入性能显著提升。
慢查询与统计信息调优
TiDB 自带 Dashboard 提供慢查询分析功能,可以直接定位问题 SQL。对于超大表,建议单独指定统计信息收集时间和采样比例——普通表按 10% 采集,超大型表可降至 1% 甚至 0.1%,避免统计信息收集消耗过多 IO 资源影响在线业务。
冷热数据分离
TiDB 支持冷热数据分层存储,热数据放在 SSD 高性能存储上,历史冷数据放在 HDD 上,有效降低存储成本。董明放特别提到:“TiDB 有一个很好用的功能就是冷热备份,你可以不用全部使用 SSD,把热数据放到高性能存储上,冷数据放到 HDD,降低成本。”
/迁移成果/
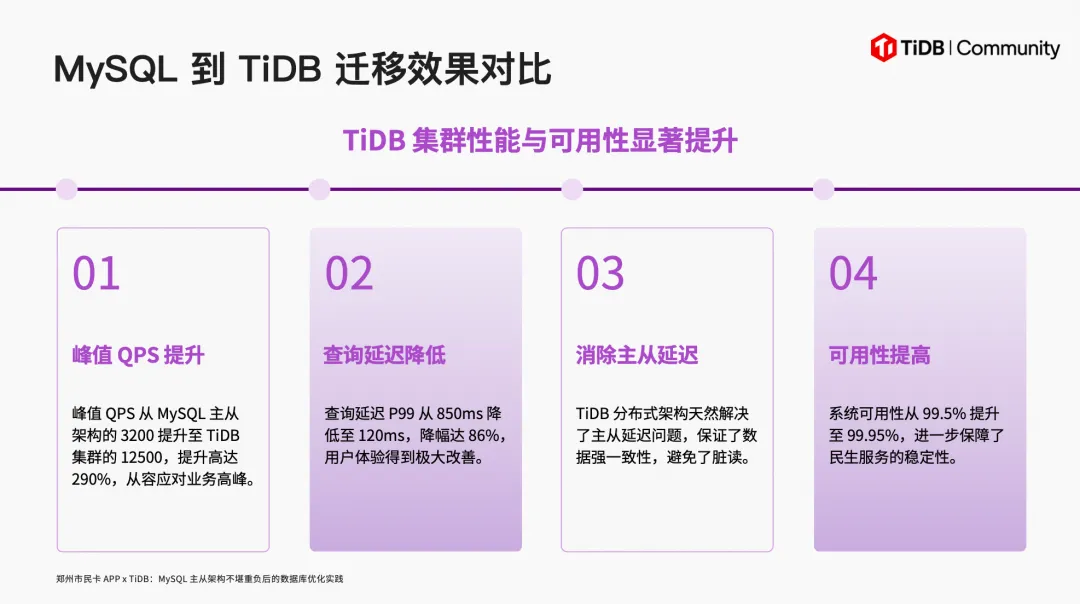
从 MySQL 切换到 TiDB 后,效果立竿见影:
抢券活动数据库零故障——切换后再未出现因数据库导致的系统问题,偶尔的故障均来自 CDN 或 SLB 层面。 运维成本大幅下降——节点故障自动恢复,扩容无需人工介入,TiDB Server 可通过 SLB 随时水平扩展。 集群从 3 节点扩容到 5 节点——随用户增长平滑扩容,TiKV 扩容时建议在低峰期进行并控制 Region 均衡速度,避免影响在线业务。
/经验总结与未来展望/
回顾整个迁移和优化过程,董明放分享了三条实用建议:
磁盘选型不要省钱。数据库务必使用 SSD 磁盘,HDD 无法充分发挥 TiDB 性能。团队通过与云厂商协商,单独申请了搭载高性能 SSD 的物理机。 迁移前充分演练。在预发环境反复压测和预演是保证迁移成功的最关键环节。 善用 TiDB 生态工具。从 DM 迁移到 TiCDC 数据同步,再到 Dashboard 诊断和 Prometheus 监控,TiDB 的工具链能够覆盖数据库全生命周期管理。
展望未来,团队正在关注几个方向:一是引入 TiFlash 列式存储组件,满足日益增长的 OLAP 统计分析需求;二是关注 TiDB 的 Serverless 云服务,实现更灵活的弹性伸缩;三是结合 AI 能力搭建自动化运维平台,实现一键部署、智能诊断和自动扩缩容。
董明放最后表示:“作为 TiDB 的深度使用者,我们后续会持续跟进这些新能力,让郑州市民卡 APP 的数据库架构更加完善。”







