 夜雨聆风
夜雨聆风Anthropic 最近在 GitHub 上开源了 Knowledge Work Plugins,11 个插件,覆盖了销售、客服、法务、财务、产品管理。每个插件都是一个"岗位培训包"——把某个岗位的最佳实践写成 Markdown 技能文件,让 Claude 像新员工一样学习后上岗。
我花了一整天翻完这个仓库,核心发现只有一个:Anthropic 不是在卖工具,是在做"AI 同事的岗位培训体系"。而大多数企业,连新员工培训都没做好,就想让 AI 直接顶岗。
这篇文章,我想记录一下:怎么把一个反复写的 Prompt,变成一个可复用的"乐高插件"。
第一步:生成——定义边界,不是堆砌功能
我把一个 Prompt 变成插件,第一步不是写代码,是写边界。
Anthropic 的 customer-support 插件给我很大启发。这个插件定义了 5 个技能:ticket-triage(工单分类)、draft-response(起草回复)、escalate(升级管理)、kb-article(知识库建设)、customer-research(客户研究)。每个技能对应一个明确的问题:谁触发?什么时候触发?不解决什么?
举个例子,ticket-triage 的边界是这样的:
- • 谁触发:新工单进来时自动触发
- • 什么时候触发:工单创建后,没有人类客服看过之前
- • 不解决什么:不直接回复客户,只分类和标记;不处理没有工单号的消息;不覆盖 P0(全系统瘫痪)的工单,那个直接跳人工
这个边界定义清楚之后,Claude 就不会"越权"。我见过太多 Prompt 写着写着变成了"请你帮我分析、总结、回复、归档、顺便写个周报"——AI 什么都做,什么都做不好。
我自己写插件的时候,第一步永远是三句话:
- 1. 这个技能解决什么问题?
- 2. 用户输入什么?输出什么?
- 3. 明确说"不处理什么"。
比如我写一个"月底关账"插件,边界是:
- • 输入:月份、需要生成的分录类型(AP accrual、prepaid amortization、depreciation)
- • 输出:标准格式的日记账分录,含借贷明细和支持文档索引
- • 不处理:不生成最终会计凭证(需要会计复核);不处理超过 1000 行的明细;不做税务调整
边界越清楚,AI 越靠谱。不是让 AI 变聪明,是给 AI 画个圈,让它在圈里发挥。

第二步:迭代——从"能跑"到"好跑"
插件的 v0.1 版本,能跑通一个场景就够了。但大部分团队的问题不是没做 v0.1,而是没做 v0.2。
Anthropic 的 small-business 插件有一个设计特别妙:审批节点(checkpoint)。AI 在关键动作前会暂停,等用户确认后再执行。比如 cash-flow-snapshot 技能,Claude 拉取数据、计算预测、生成 XLSX,但在最后一步会停下来问:"这是基于截至今天的应收应付计算的,请确认数据是否完整?"
这个设计看起来是"降低效率",实际上是"增加信任"。没有审批节点的 AI,就像没有刹车的车——速度快,但没人敢坐。
我自己的迭代路径一般只走两步:从"能跑"到"敢用"。
v0.1:能跑通一个场景。 一个输入,一个输出,不需要边界。能跑就是胜利。
v0.2:敢给同事用。 加错误处理、加审批节点、加安全加固。我团队里的插件,如果没有 checkpoint,同事宁可不用。有了 checkpoint,哪怕慢一点,大家也敢试。
迭代不是加功能,是减风险。不是让 AI 变快,是让团队敢用。
第三步:优化——不是写得多,是写得准
我踩过这个坑。一开始写 Prompt,总觉得写越长,AI 越懂。结果是,写得不准,200 行和 20 行一样烂。
Anthropic 的插件优化给了我两个直接的经验。
第一个是 Description 要具体到工具名。
差的描述:"处理 Excel 文件。"
好的描述:"使用 OfficeCLI 命令行工具操作 Excel 电子表格。当用户提到 Excel、xlsx、表格时触发。不处理 VBA 宏、超过 100MB 的文件、加密的文档。"
具体到什么工具、什么触发词、什么不处理,Claude 的触发精度会高很多。我在 enterprise-search 插件里看到类似的写法:"跨 Slack、Notion、Guru、Jira 搜索。当用户问'谁最懂 XX'、'我们什么时候决定用 XX'、'Project Aurora 的 API 在哪'时触发。不处理需要实时数据的问题(如'今天股价多少')。"
第二个是 Few-Shot 示例要覆盖三种情况。
每个技能至少配三个示例:
- • 正常情况:标准输入,标准输出
- • 边界情况:输入缺字段,输出怎么处理
- • 错误情况:输入完全不对,输出怎么拒绝
customer-support 插件的 ticket-triage 技能,示例里就有一个边界 case:工单描述是空的,只有标题。Claude 的输出是:"标记为'信息不完整',路由到 Tier 1,附上回复模板:'您好,为了更快帮您解决问题,请补充以下信息...'"
还有一个我没想到,但 Anthropic 做了:渐进式披露(Progressive Disclosure)。每个 SKILL.md 主体控制在 3000 字以内,只放核心指令。详细内容放在 references/ 目录,比如 gotchas.md(常见坑)、worked-example.md(完整案例)。需要时 Claude 才会读取。
这解决了两个痛点:一是不超过上下文窗口;二是业务专家可以只读主文件,不用在 2 万字里找逻辑。我试过把一个 8000 字的技能文件拆成主文件 + references,触发准确率从 60% 提升到 85%。
第四步:评测——数据说好,不是感觉好
插件写好了,怎么知道好不好?靠感觉?不行。靠"我用了觉得不错"?更不行。
Anthropic 的评测方法很直接,分两层。
先测触发。20 个正例(应该触发这个技能),20 个反例(不应该触发)。看 Claude 的路由准确率。
比如 enterprise-search 插件的 search 技能。正例:"谁最懂 Kubernetes 架构?"、"我们什么时候决定用 Postgres 的?"、"Project Aurora 的 API 重新设计决定在哪?"反例:"帮我写一封辞职信"、"今天比特币价格多少?"、"总结一下 2024 年 NBA 总决赛"。
再测效果。5 个测试用例,看输出质量。
enterprise-search 有一个很直观的效果对比:之前工程师找"Project Aurora 的 API 重新设计决定在哪",需要在 Slack、邮件、Google Drive 里翻 15 分钟。用了插件之后,Claude 30 秒内给出综合答案:"团队在 3 月 3 日决定用 REST 替代 GraphQL,Sarah 3 月 4 日邮件确认了时间线,设计文档 3 月 5 日更新。"
15 分钟到 30 秒。这是数据,不是感觉。
我自己做评测的时候,会记录三个指标:
- 1. 触发准确率:100 个查询里,有多少路由到了对的技能?
- 2. 输出完整度:该包含的信息,有没有漏?
- 3. 人工修正率:Claude 的输出,人类需要改多少?
有一个插件我迭代了三个版本,触发准确率从 45% 到 72% 到 89%。不是因为我 Prompt 写得更好,是因为我在 v0.2 的时候加了 10 个反例,让 Claude 知道"什么情况下不该触发这个技能"。
评测不是面子工程,是下一轮迭代的输入。没有评测数据,迭代就是瞎改。
第五步:治理——插件不是写完就完,是养一个习惯
插件上线只是开始。团队里有人用,有人不用,有人改,有人乱改——没有治理,你三个月前写的 Prompt,三个月后没人敢用。
你可能觉得"治理"是工程师的事。但换个说法:没有治理,你三个月前写的 Prompt,三个月后没人敢用。因为没人知道它现在还是不是好的,改了什么,能不能放心给新人。
Anthropic 的治理思路藏得很深,但很有价值。
版本控制是第一条。语义化版本 + CHANGELOG。每个插件的 plugin.json 里有版本号,README 里有变更记录。这不是工程师的洁癖,是团队的信任基础。销售主管看到"v1.2.0:调整了 call-prep 的优先级权重",就知道为什么 AI 最近的表现变了。
质量门禁是第二条。改动前的检查清单。插件是 Markdown 文件,意味着任何人都能改。但改之前要过检查:边界定义是否清晰?Few-Shot 示例是否覆盖了三种情况?references/ 目录是否更新?MCP 配置是否匹配?
第三条我最看重:工具抽象层。
Anthropic 的每个插件都通过 .mcp.json 连接外部工具,但插件不绑定具体工具,而是绑定工具类别。用 ~~project tracker 而不是 ~~Jira,用 ~~chat 而不是 ~~Slack。企业可以替换 .mcp.json 里的具体 URL,不用改任何技能文件。
这相当于给 AI 工作流做了一个"工具抽象层"。今天用 Jira 的公司,明天换成 Linear,只需要改配置,不需要重写技能。这个设计解决了企业最大的顾虑:我不想被任何一家 AI 公司或工具商绑定。
我在自己团队里推插件的时候,治理规则就三条:
- 1. 谁用,谁反馈。每个插件配一个反馈渠道,用的人每周说一次"哪里好,哪里坑"。
- 2. 谁改,谁 review。业务专家可以改技能文件,但改完必须有人 review,通过才能合并。
- 3. 版本锁定。生产环境用固定版本,升级必须测试通过。不能随便"先上线再说"。
插件治理不是技术问题,是组织习惯问题。技术团队习惯了版本控制,但业务团队不习惯。需要一个懂技术又懂业务的人做桥梁——这个人通常就是 Tech Lead 或者架构师。
一个立即可做的行动
如果你现在有一个反复写的 Prompt——比如"帮我分析客户"、"帮我分类工单"、"帮我写周报"——试着把它转成插件。
不用一次写完美。先写 v0.1:一个 SKILL.md,三句话边界,三个示例。能跑通一个场景,就是胜利。
然后给你的同事用。收集反馈。迭代到 v0.2。再评测。再迭代。
Anthropic 的 Knowledge Work Plugins 证明了:AI 的价值不在"更聪明的模型",而在"把最佳实践变成可复用的乐高积木"。模型会越来越便宜,但岗位知识会越来越贵。谁先把自己的知识编码成插件,谁就能让 AI 变成真正的智能同事,而不是高级搜索框。
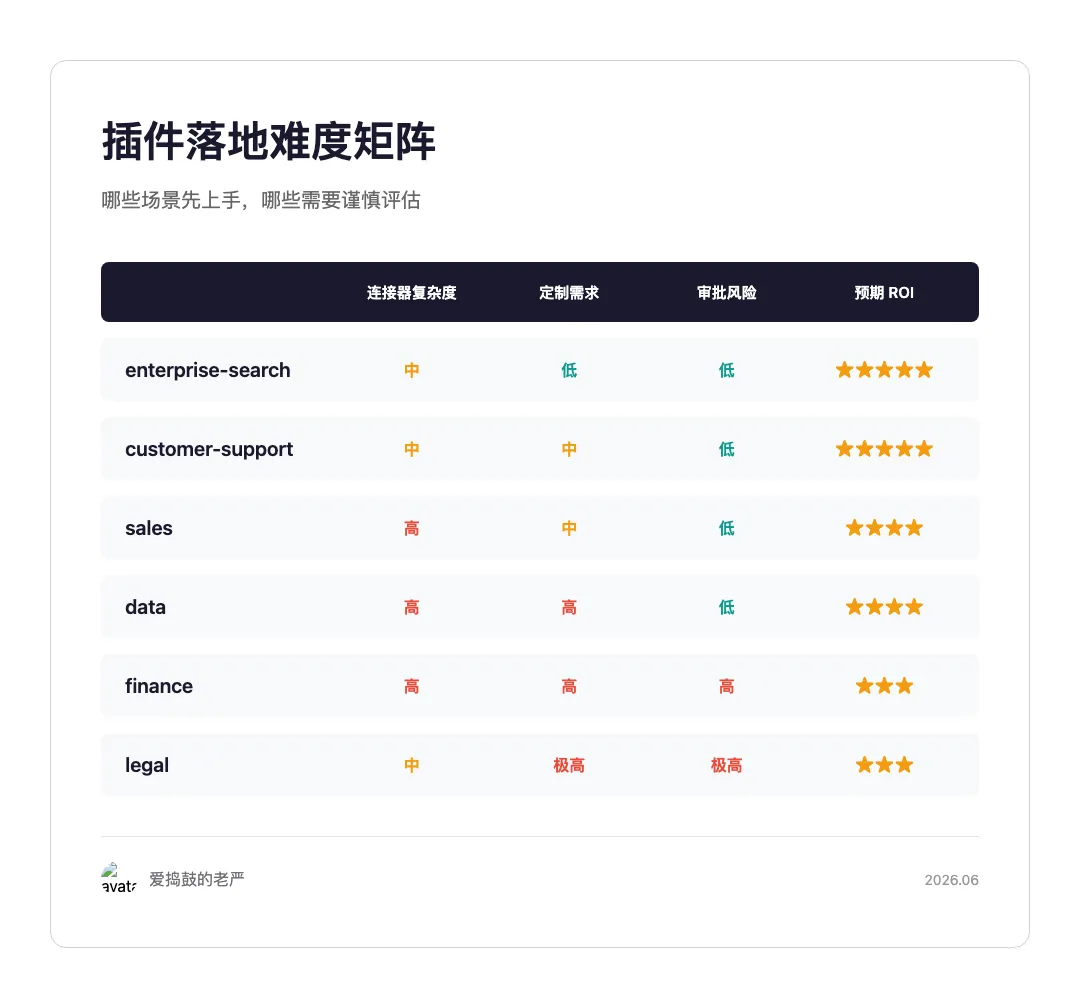
Anthropic 的 Knowledge Work Plugins 覆盖了 11+ 插件,覆盖知识工作方方面面。下面三个场景,是我在调研中觉得最容易落地、但最被忽略的。
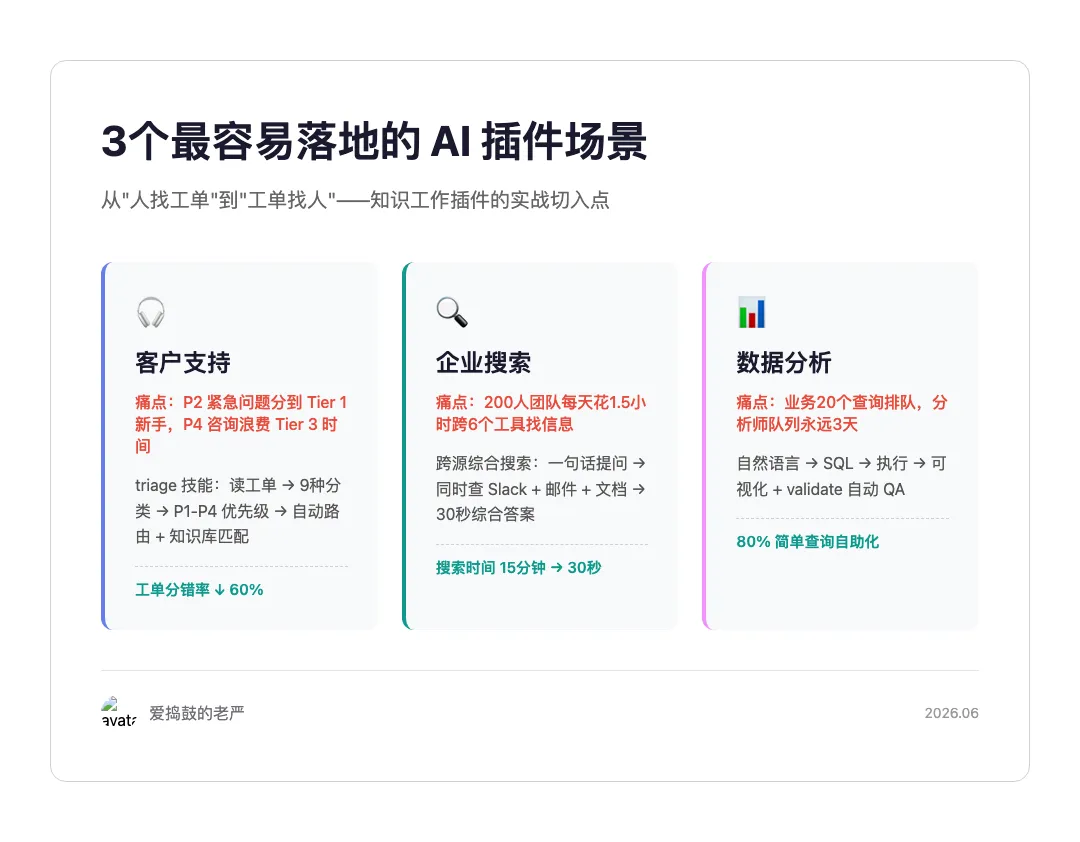
场景一:客户支持(从"人找工单"到"工单找人")
客服团队最大的痛点不是回复不够快,是工单分错人。P2 的紧急问题被分到 Tier 1 的新手手里,P4 的咨询被 Tier 3 的资深工程师浪费 20 分钟。
customer-support 插件的 triage 技能设计了一个简单但有效的框架:
- • 读工单描述 → 匹配问题分类法(9 种类型)→ 评估优先级(P1-P4)→ 路由到对应团队
- • 同时检查知识库:有没有已解决的类似案例?有的话附上 workaround
- • 最终输出:分类标签 + 路由建议 + 知识库引用 + 首条回复草稿
实现路径:先定义你企业的工单分类法(9 种可以照搬,也可以改成 5 种),然后给每个类别配一个"首条回复模板"。不需要连 CRM 系统——先让 Claude 读工单文本,人工确认路由结果,跑两周数据再决定是否自动化。
场景二:企业搜索(从"考古式翻找"到"30秒回答")
200 人的团队,员工平均每天花 1.5 小时在不同工具里找信息。休假 3 天回来,500 条未读消息,不知道从哪里开始补。
enterprise-search 插件的核心思路是:一句话提问,跨源综合。比如工程师问"Project Aurora 的 API 重新设计决定在哪?"Claude 同时搜索 Slack 周二的讨论、邮件里的确认、Google Drive 里的更新文档,30 秒内给出综合答案。
实现路径:先连接 2-3 个最常用的工具(通常是 Slack + 文档系统)。定义 3 类高频问题:"决策在哪?"(跨时间线追踪)、"谁最懂?"(跨作者识别)、"最新状态?"(跨版本对比)。每类问题配 5 个正例 + 5 个反例做路由测试。效果:信息搜索时间从 15 分钟降到 30 秒。
场景三:数据分析(从"分析师排队"到"业务自助")
业务团队每天有 20 个"帮我查一下"的需求,分析师队列永远排 3 天。data 插件的解法不是替代分析师,是让 80% 的简单查询自助化。
data 插件的 analyze 技能:自然语言提问 → 生成 SQL → 执行 → 可视化。业务团队问"上季度各渠道收入占比",Claude 从 Snowflake 拉数据,跑 query,输出带图表的 HTML 仪表板。关键设计:validate 技能在共享前自动 QA——检查方法论、数据范围、计算逻辑。
实现路径:先锁定 5 个最高频的分析问题(通常是收入、留存、转化率、渠道、产品)。用 CSV 而不是数据仓库起步——让 Claude 读 CSV,生成分析,业务团队确认逻辑。验证准确率超过 90% 后,再连数据仓库。注意:validate 技能必须保留,错误的数据分析比没有分析更可怕。
一个 AI 瞎捣鼓的架构师,把团队转型过程中踩过的坑分享给你,欢迎大家评论区讨论
