 夜雨聆风
夜雨聆风AI 编程助手要告别蛮力搜索了
一句话总结:下一代 AI Coding Agent 的关键,不是多会 grep,而是能不能接上 IDE 级别的语义理解。
很多人以为命令行里的编程助手已经足够聪明:能读文件、能搜索、能改代码、能跑测试。
但真实工程里,它经常卡在一个很朴素的问题上:它不知道一个符号到底来自哪里、一个函数真实签名是什么、一个类型在泛型和重载之后最终长什么样。
于是我们看到大量“像程序员、但不够工程化”的行为:扫目录、翻依赖、读 node_modules、拆 JAR、用文本匹配猜测 API。
这不是智能,是蛮力。
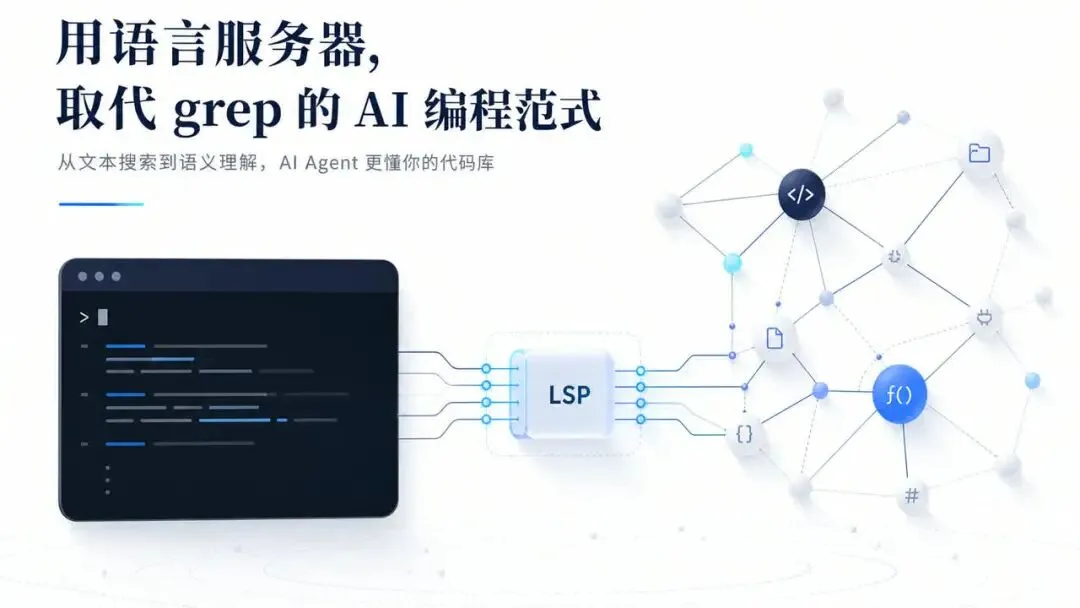
真正的变化,是把 Agent 接到代码语义层
GitHub 这次强调的方向很具体:让 Copilot CLI 通过 Language Server Protocol,也就是 LSP,获得和编辑器类似的代码智能。
LSP 本来就是 VS Code、JetBrains 插件、各种编辑器实现“跳转定义、查找引用、类型解析、函数签名”的基础设施。
它的意义不在于新增一个工具按钮,而在于把 Agent 从“读文本”推进到“读工程”。
一个没有 LSP 的 Agent,面对 Java、TypeScript、Python 这样的大项目,通常只能猜:
在仓库里搜索关键字; 到依赖目录里翻源码或声明文件; 从报错和文件名反推上下文; 试着改一版,再靠测试纠错。
接上 LSP 后,它可以直接问语言服务器:这个 symbol 的定义在哪里?这个方法有哪些 overload?这个变量最终是什么类型?调用链引用有哪些?
这就是“代码助手”和“工程助手”的分界线。
为什么这件事对 AI Coding Agent 很重要
过去一年,AI 编程工具的竞争常常集中在模型能力、上下文长度、编辑体验和自动运行测试上。
但工程实践里,另一个瓶颈越来越明显:Agent 的工具层太粗糙。
模型越强,越容易暴露工具短板。因为它能推理出“我需要知道这个类型”,但如果工具只能给它一堆文本片段,它还是会在噪音里猜。
LSP 的价值,是把很多本来要靠上下文窗口硬塞进去的信息,变成可查询、可定位、可复用的结构化信号。
这会带来三个直接影响:
更少幻觉:函数签名和定义位置来自语言服务器,而不是模型猜测。 更低 token 浪费:不用把整段依赖源码塞进上下文。 更可控的自动修改:Agent 知道影响范围,才敢做跨文件重构。
开发者应该看见的不是某个产品功能,而是一个范式
这篇文章表面上是在讲 Copilot CLI 的 LSP 配置,实质上提醒我们:AI 编程工具的下一轮竞争,会从“谁的聊天框更好用”,转向“谁能接入更多确定性的工程信号”。
这些信号包括:
LSP 的语义索引; 测试和覆盖率; 构建系统; 运行时日志; 依赖图; API 文档和内部规范。
模型负责推理,工具负责确定性。两者边界越清楚,Agent 越可靠。
对团队的一个实用建议
如果你正在评估 AI Coding Agent,不要只问“它用的是什么模型”。
更应该问:它能不能理解你的代码库?它用什么方式理解?是靠文本搜索,还是能接入语言服务器、构建系统和测试系统?
真正能在生产环境里节省时间的,不是一次漂亮 demo,而是每天少一次错误跳转、少一次误改依赖、少一次因为猜错类型而反复试错。
参考资料
GitHub Blog:Give GitHub Copilot CLI real code intelligence with language servers Author:Bruno Borges Link:https://github.blog/ai-and-ml/github-copilot/give-github-copilot-cli-real-code-intelligence-with-language-servers/[1]
引用链接
[1]https://github.blog/ai-and-ml/github-copilot/give-github-copilot-cli-real-code-intelligence-with-language-servers/
