 夜雨聆风
夜雨聆风Firecrawl 很容易被简单理解成“开源网页爬虫”。这个说法没错,但太浅。
源码里更值得看的,是它怎么把一次不稳定的网页访问,包装成一个有 API 版本、有 schema、有队列、有并发控制、有 robots / blocklist / 计费 / zero data retention、有多引擎 fallback、有结构化输出的文档流水线。

本文源码基准
为了避免版本变化导致读者校对不上,先把本文使用的源码快照放在这里:
- • 本地源码目录:
sources/firecrawl - • 分支:
main - • commit:
2f81f9cce0df56859dc6e246f136021b3a577362 - • commit 时间:
2026-05-29 14:12:59 -0700 - • commit 信息:
fix: CVE-2026-41676 security vulnerability (#3664)
后面提到的路径和源码行为,都以这个快照为准。Firecrawl 仍在高速迭代,如果你在更新版本里核对,局部实现和文件位置可能已经变化。
说明:本系列为 AI 辅助源码阅读,已尽量按本地源码和 pinned commit 核对,但仍可能存在遗漏、理解偏差或版本差异。关键细节请以对应 commit 的源码、测试和官方文档为准。
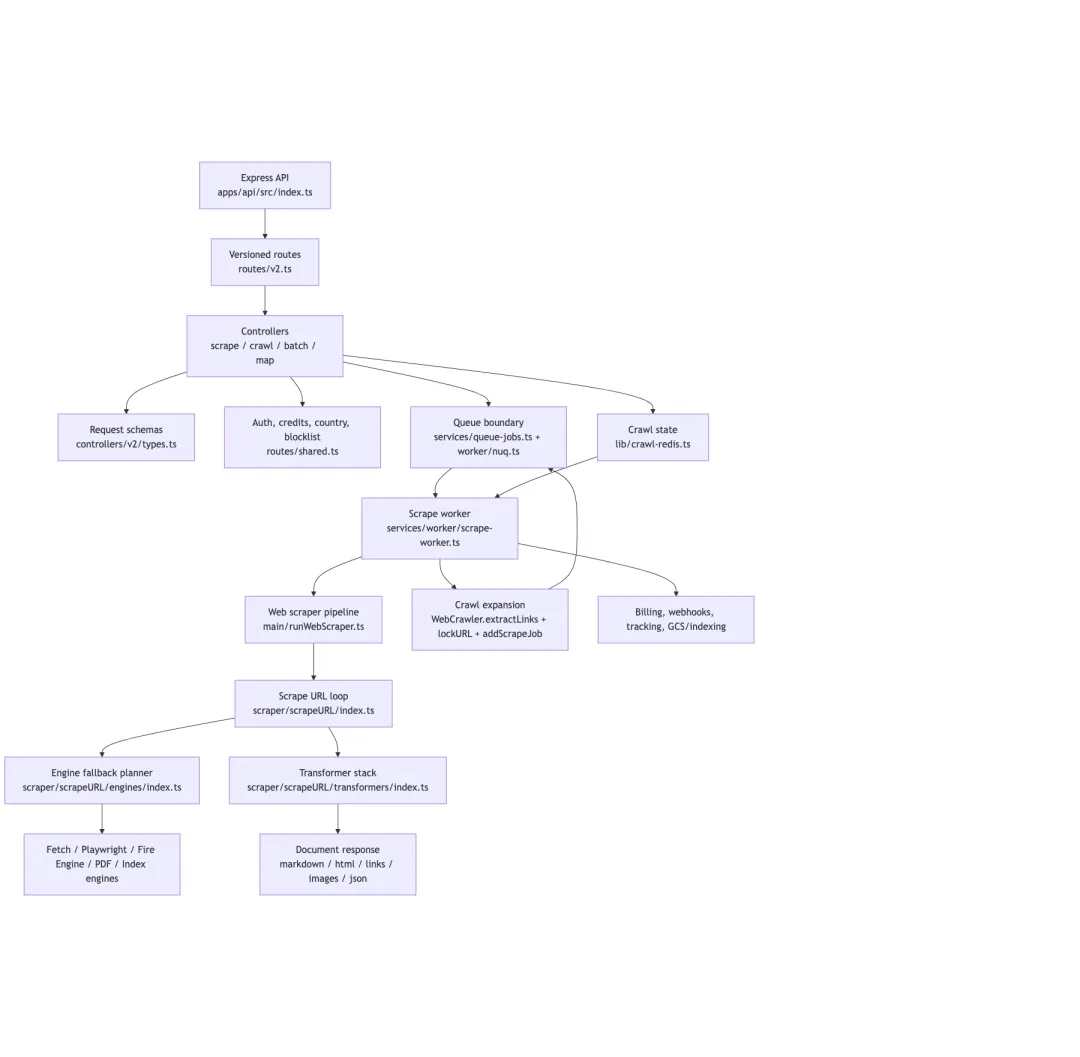
先看主链路
读 Firecrawl,不建议从“怎么抓一个网页”开始。那会把视野锁在 fetch、Playwright 或反爬细节上。
更好的主线是:
v2 API -> request schema -> controller -> NuQ job / in-memory job -> scrape worker -> scrapeURL engine waterfall -> transformer stack -> status / billing / webhook
这条线能解释几个关键问题:
- • 为什么
/scrape是同步接口,却复用了 worker。 - • 为什么
/crawl不是递归函数,而是先保存 crawl state,再不断投递 job。 - • 为什么同一个 URL 有时走 index,有时走 fetch,有时必须走浏览器。
- • 为什么最终返回的不只是 HTML,而是 markdown、links、images、summary、json 等多种格式。
API 面不是一条链
服务入口在 apps/api/src/index.ts。它创建 Express 和 WebSocket,挂载 /v1、/v2、admin router,并初始化 blocklist 和 engine forcing。
真正的产品入口在 apps/api/src/routes/v2.ts。这里能看到 Firecrawl 的 v2 API 被拆成几类:
- •
POST /v2/scrape:同步抓取单个 URL。 - •
POST /v2/crawl:异步 crawl,返回 job id 和 status URL。 - •
POST /v2/batch/scrape:批量 URL,本质复用 crawl 的状态模型。 - •
POST /v2/map:只做 URL discovery,不直接抓正文。 - •
POST /v2/parse:上传文件,进入类似 scrape 的解析链。 - •
GET /v2/crawl/:jobId和 WebSocket:查询或订阅 crawl 状态。
这说明 Firecrawl 的核心不是某个 crawler 函数,而是多个 endpoint 共享同一套抓取、状态、队列和 transformer 基础设施。
schema 是第一层产品决策
apps/api/src/controllers/v2/types.ts 很值得细读。它不是普通类型文件,而是请求进入系统后的第一层产品决策。
URL 会自动补 http://,只允许 http/https,并对 TLD 和本地测试环境做例外校验。actions 支持 wait、click、screenshot、write、press、scroll、executeJavascript、pdf 等动作,同时限制总等待时间和 action 数量。
baseScrapeOptions 定义 formats、headers、include/excludeTags、waitFor、mobile、proxy、cache 等参数。后面还会根据 json、changeTracking、stealth、enhanced、auto proxy、lockdown 等选项调整 timeout、waitFor 和 maxAge。
这层设计的价值是:用户传进来的参数,在 controller 之前就被整理成可执行模型。后面的 worker 不需要反复猜“用户到底想要什么”。
/scrape:同步接口,worker 执行
scrapeController 在 apps/api/src/controllers/v2/scrape.ts。
它不是直接调用 scrapeURL(url)。控制器先生成 job id,解析 schema,做权限检查,计算 zero data retention,再处理 agent interop 和 team concurrency semaphore。
真正关键的一步,是它会构造一个 NuQJob<ScrapeJobData>,设置 mode: "single_urls" 和 skipNuq: true,然后直接调用 processJobInternal(job)。
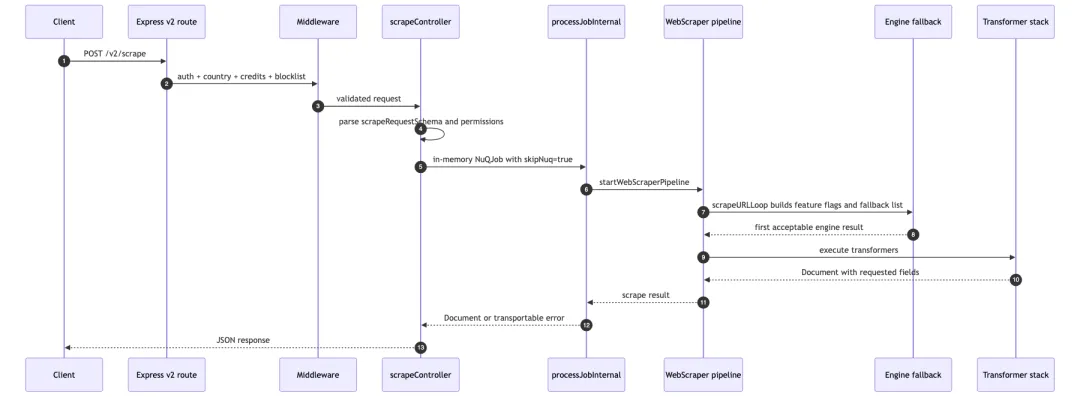
这就是 Firecrawl 一个很实用的抽象:同步 scrape 没有单独写一套执行逻辑,而是把自己伪装成 worker job。这样同步和异步可以共享后面的抓取、transformer、计费、错误序列化和日志路径。
返回前还有一个小细节:如果用户没有请求 rawHtml,controller 会把 doc.rawHtml 删除。也就是说,raw HTML 可能在内部被需要,但不会默认暴露给调用方。
/crawl:先保存状态,再铺开任务
crawlController 在 apps/api/src/controllers/v2/crawl.ts。
它的重点不是立刻抓网页,而是先构造一个 StoredCrawl:里面保存 originUrl、crawlerOptions、scrapeOptions、internalOptions、team_id、maxConcurrency 和 zero data retention 等信息。
然后它会尝试预取 robots.txt,把 crawl group、Redis crawl 和 active crawl 状态保存起来,最后投递一个 mode: "kickoff" 的 job。
后续 worker 发现新 URL 时,不是靠临时变量继续往下递归,而是回到 Redis 里的 crawl state,重建 crawler,再按同一套规则过滤、lock、入队。
这解释了为什么 Firecrawl 的 crawl 更像一个状态机,而不是一个深度优先或广度优先递归函数。
batchScrapeController 也利用了这个模型。它会构造 StoredCrawl,但 crawlerOptions: null,然后把每个 URL 作为 single_urls job 投进去。batch 和 crawl 的差异,不在 status、cancel、webhook 这些外层能力,而在于 batch 不继续扩展链接。
kickoff 不是第一抓,而是铺候选
processKickoffJob 在 apps/api/src/services/worker/scrape-worker.ts。它做的第一件事,是 lock 初始 URL,再投递一个真正的 single_urls job。
接着它会根据 robots 和当前路径生成 sitemap 任务:robots 里的 sitemap、当前路径 sitemap、根路径 sitemap、root domain sitemap,都可能变成 kickoff_sitemap job。
然后它还会调用 index 取候选链接,过滤、lock,再批量入队。
所以 Firecrawl 的 crawl 并不是“抓首页、抽链接、继续抓”的纯 BFS。它一开始就把 seed URL、sitemap、index links 混在一起,用统一的 crawler 规则清洗候选,再交给队列调度。
processKickoffSitemapJob 还会继续处理 sitemap 中嵌套的 sitemap,不过源码里也做了上限控制,避免一个站点把 sitemap 扩展拖成无底洞。这个细节体现了 Firecrawl 的基本态度:尽量多发现 URL,但每一步都要有边界。
NuQ 处理的是并发,不只是排队
Firecrawl 仍然使用 BullMQ 做 deep research、llms.txt、billing、precrawl 等队列,但 scrape 主队列走 apps/api/src/services/worker/nuq.ts。
NuQ 的 job 状态包括 queued、active、completed、failed、backlog,并带 ownerId 和 groupId。这两个字段分别对应 team 和 crawl group,是并发限制和状态聚合的关键。
入队前的主要逻辑在 apps/api/src/services/queue-jobs.ts。单 job 会根据 team concurrency 和 crawl concurrency 决定直接入队还是进入 backlog;批量 job 会先按 team 和 crawl 分桶,再决定哪些能跑、哪些要等。
所以这里的队列不是“先来后到”的容器,而是把团队级并发、crawl 级并发、delay、timeout 和 backlog 显式编码进调度过程。
worker 成功后,还可能继续扩展 crawl
processJobInternal 在 apps/api/src/services/worker/scrape-worker.ts,它会按 mode 分发到 processKickoffJob、processKickoffSitemapJob 或 processJob。
processJob 才是真正执行单页 scrape 的地方。它会计算剩余 timeout,调用 startWebScraperPipeline,成功后计费、记录日志、发送 webhook;失败时记录 robots blocked、清理 URL lock,并走失败计费和 tracking。
如果这个 job 属于 crawl,它还会从 Redis crawl state 重建 crawler,从页面的 rawHtml 里提取链接,过滤、lock,再投递新的 scrape jobs。
这里有一个容易忽略的点:main/runWebScraper.ts 会在 job.data.crawl_id 存在时强制追加 { type: "rawHtml" }。原因很直接:crawl 扩展新链接必须读 HTML,即使用户最终没有请求 rawHtml。
URL 过滤比“提取链接”更重要
crawl 的链接扩展逻辑在 apps/api/src/scraper/WebScraper/crawler.ts。
filterLinks() 会优先尝试 Rust 版本的 @mendable/firecrawl-rs,失败时再回退到 JS 实现。真正要看的不是它怎么用 Cheerio 抽链接,而是哪些链接会被拒绝。
JS fallback 里能看到一整套边界:max discovery depth、maxDepth、excludePaths、includePaths、backward crawling、robots.txt、文件类型过滤。robots 和 sitemap 的读取也在同一个类里完成。
对应的状态在 apps/api/src/lib/crawl-redis.ts。这里保存 crawl,记录 crawl jobs 和 done jobs,判断 kickoff / sitemap 是否完成,finish crawl,并用 URL normalization、URL permutations、lockURL / lockURLs 做去重和 limit 控制。
这也是 Firecrawl 可解释的地方。一个 URL 为什么没被抓,理论上不应该只是“没轮到”或者“失败了”,而应该能落到某个 denial reason、lock 状态、limit 或 robots 规则上。
/map 是 discovery,不是轻量 scrape
mapController 在 apps/api/src/controllers/v2/map.ts。它最终调用 getMapResults(),目标是返回候选 URL,而不是抓正文。
真正的逻辑在 apps/api/src/lib/map-utils.ts。它会处理 redirect normalize,构造临时 StoredCrawl,按需要读取 sitemap,组合 search query、内部 index 和 Fire Engine map 结果,再做 domain、subdomain、path prefix、去重和 limit 过滤。
这层和 crawl 的关系很有意思:buildPromptWithWebsiteStructure() 会先 map 出站点结构,再把 URL 列表放进 prompt,让模型生成 crawler options。随后 crawlController 只把模型结果填进用户没显式提供的字段。
也就是说,AI 在这里不是接管 crawl 决策,而是给 crawler options 提建议;用户显式参数仍然优先。这个边界非常重要,否则自然语言 prompt 很容易覆盖掉 include/exclude、limit 或 sitemap 这类硬约束。
engine waterfall 才是抓取核心
main/runWebScraper.ts 只是薄封装:crawl 最多重试 3 次,普通 scrape 只试 1 次,然后调用 scraper/scrapeURL/index.ts 里的 scrapeURL()。
真正复杂的是 engine waterfall。
buildFeatureFlags() 会从 actions、screenshot、branding、audio/video、waitFor、location、mobile、TLS、proxy、PDF/document 等参数推导 feature flags。
scraper/scrapeURL/engines/index.ts 里定义了 Fire Engine CDP、TLS client、Playwright、fetch、pdf、document、index、Wikipedia、X/Twitter 等 engine,并为不同 feature 设置优先级。
shouldUseIndex() 会明确排除不能走 index 的情况,比如 parse、custom screenshot、changeTracking、branding、PDF maxPages、headers、actions、profile、maxAge=0 等。
buildFallbackList() 再根据 feature support 和 quality 排序。某个 engine 太慢时,下一个候选 engine 会按 waterfall delay 被拉起并行竞速;一旦有 engine 成功,其他候选会被 abort,避免浪费资源。
这不是“先 fetch,失败再 browser”的简单 fallback,而是一套基于能力、质量、延迟和成本的执行计划。
Transformer stack:抓到之后才变成文档
网页抓下来只是开始。apps/api/src/scraper/scrapeURL/transformers/index.ts 负责把 raw page content 变成用户要的输出。
transformer stack 会依次处理 rawHtml 到清洗 HTML、HTML 到 markdown、links、images、branding、metadata、screenshot 上传、index、search index、LLM extract、summary、query、attributes、agent、diff、audio、video,最后把字段收敛到请求的 formats。
HTML 到 Markdown 也不是单一路径。lib/html-to-markdown.ts 会优先使用配置的 HTTP 服务,其次可走 Go shared library,失败或未启用时回退到 Turndown + GFM plugin,并统一做后处理。
这就是 Firecrawl 和普通爬虫的分界:普通爬虫的终点是“拿到页面内容”,Firecrawl 的终点是“把页面内容变成可被 API 稳定消费的结构化文档”。
这里还有一个工程判断:格式之间是有依赖关系的。比如用户要 summary、query 或 json extract,系统往往要先得到 markdown 或 cleaned content,再把它送进后续 LLM transformer。用户看到的是一个 formats 参数,源码里实际是一张隐式依赖图。
这也是为什么 transformer stack 必须串行记录每一步耗时。抓取慢不一定慢在浏览器,也可能慢在 HTML 清洗、markdown 派生、截图上传、LLM extract 或搜索索引写入。把这些步骤拆开,排障时才知道成本到底花在哪里。
安全边界写在链路里
Firecrawl 这种项目最容易被误读成“反爬技巧集合”。但源码里真正稳定的价值,是把安全和商业边界放进主链路。
routes/shared.ts 里有认证、credits、idempotency、blocklist、国家能力限制和 job id 校验。crawler 默认会处理 robots,除非 team flags 和请求条件允许忽略。zero data retention 会影响日志、缓存和 GCS 结果取回后的删除。
另外,仓库是 AGPL-3.0。做源码阅读和知识整理当然没问题;如果要把服务端逻辑搬进闭源 SaaS,就要先处理许可证边界。这个提醒不是法律建议,而是工程上必须先看到的约束。
最值得学的判断
Firecrawl 的工程价值,不在于教你绕过网站反爬。那条路很容易把源码阅读带偏。
它更值得学习的是:如何把网页采集里的不确定性显式编码。
请求参数先变成 schema 和 feature flags;同步请求也进入 worker 抽象;crawl 先保存状态再投递任务;URL 扩展要经过 robots、include/exclude、depth、dedupe 和 lock;engine 选择由能力表和 fallback list 决定;输出格式由 transformer stack 串起来;计费、ZDR、webhook、status 则围绕同一套 job 模型运转。
读完这条链路,再看 Firecrawl 的某个具体 engine 或某个具体格式,才不会陷入碎片。这个项目真正把“抓网页”做成了一套可排队、可解释、可计费、可回放的文档生产系统。
