还在到处找模板?SenseNova-Skills信息图生成能力测评每次做汇报、复盘或者做行业分析,你是不是还在各大设计网站上疯狂搜模板?甚至还要自费充会员?好不容易找到个差不多的,改文字、对齐字体、微调图标……折腾两小时,出来的效果还是透着一股“拼凑感”。
真的别再浪费生命了!
今天我们来实测一款“作图神器”——SenseNova-Skills。听说它只要一句话或者一份原始数据,就能自动帮你排版、配图,一键输出高逼格的信息图。不用懂设计,更不用四处找模板。这到底是用完直呼真香的“神仙工具”,还是只懂纸上谈兵的“噱头”?
Skill安装及配置
这次的测试Agent为opencode。一般来说,可以在Agent工具中用一句话让AI来帮你安装技能。
"Please install SenseNova-Skills from https://github.com/OpenSenseNova/SenseNova-Skills into your skills directory."
也可以选择手动安装。选择手动安装有以下好处:一、SenseNova-Skills全套有20几项技能,全部都安装了会导致上下文空间占用较多,AI在工具调用时也容易出现“选择困难症”;二、可以安装在非c盘的项目目录中,避免占用c盘空间。把项目代码 https://cdn.gh-proxy.org/https://github.com/OpenSenseNova/SenseNova-Skills/archive/refs/heads/main.zip 整个zip包下载下来。zip包解压缩后,把skills目录放到项目目录的 .claude 子目录下。跟信息图相关的skill就只有 sn-image-base、sn-infographic 两个,再加上一个 sn-image-doctor 用于检测环境是否就绪。其他不相关的技能可以删掉。
启动opencode,用 /skills 命令,检查是否已经识别到技能先检查一下环境,在opencode里面输入提示词:执行sn-image-doctor技能检查环境主要就三个检测点:一、是否安装好 sn-image-base 技能;二、是否已经安装好技能底下python代码的依赖项;三、是否配置了大模型的API Key。如果Python依赖没弄好,可以告诉AI让它来帮你安装。至于大模型API Key,与技能最配套的当然是商汤的API Key,一个Key就搞定了文本大模型、视觉大模型以及文生图大模型。在项目目录下建一个 .env 的文件,填入以下内容SN_BASE_URL="https://token.sensenova.cn/v1"SN_API_KEY="your-api-key"
在项目目录下再次启动opencode,opencode就会自动读取 .env 配置的环境变量。再次执行sn-image-doctor技能,确认环境已就绪。信息图生成测试
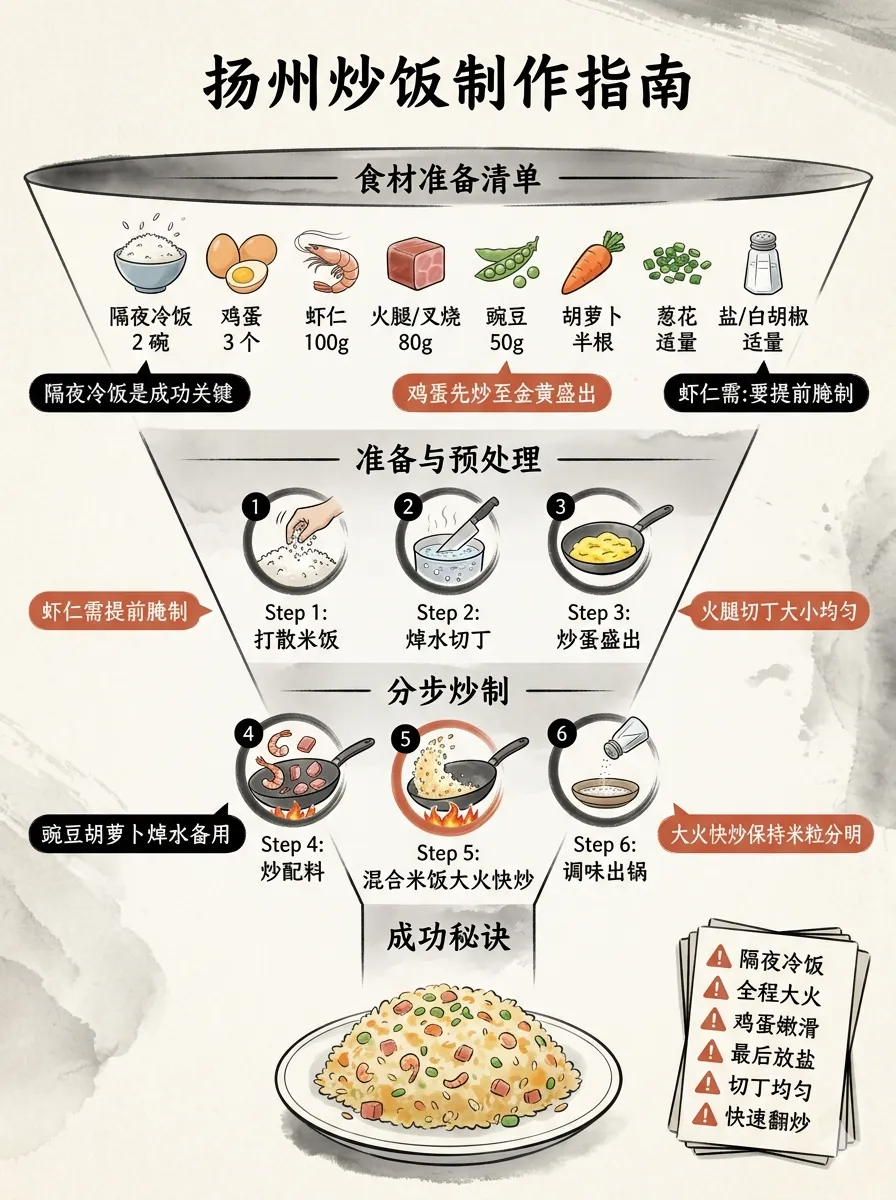
输入提示词:生成信息图介绍“如何制作扬州炒饭”
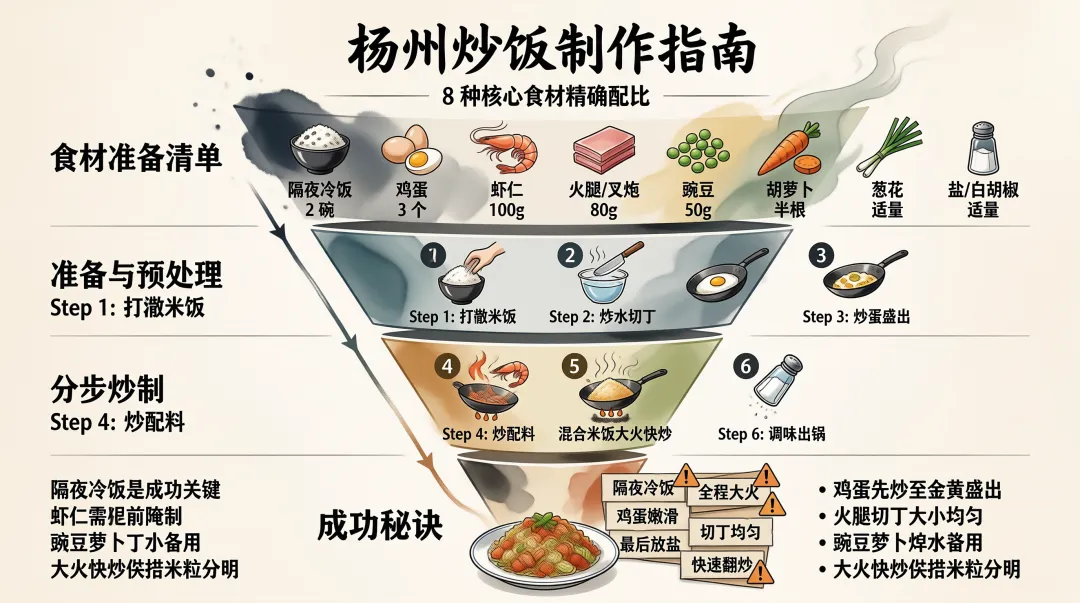
然后Agent就会自动加载 sn-infographic 技能,按照技能要求作图。整个作图过程花费了大约10分钟
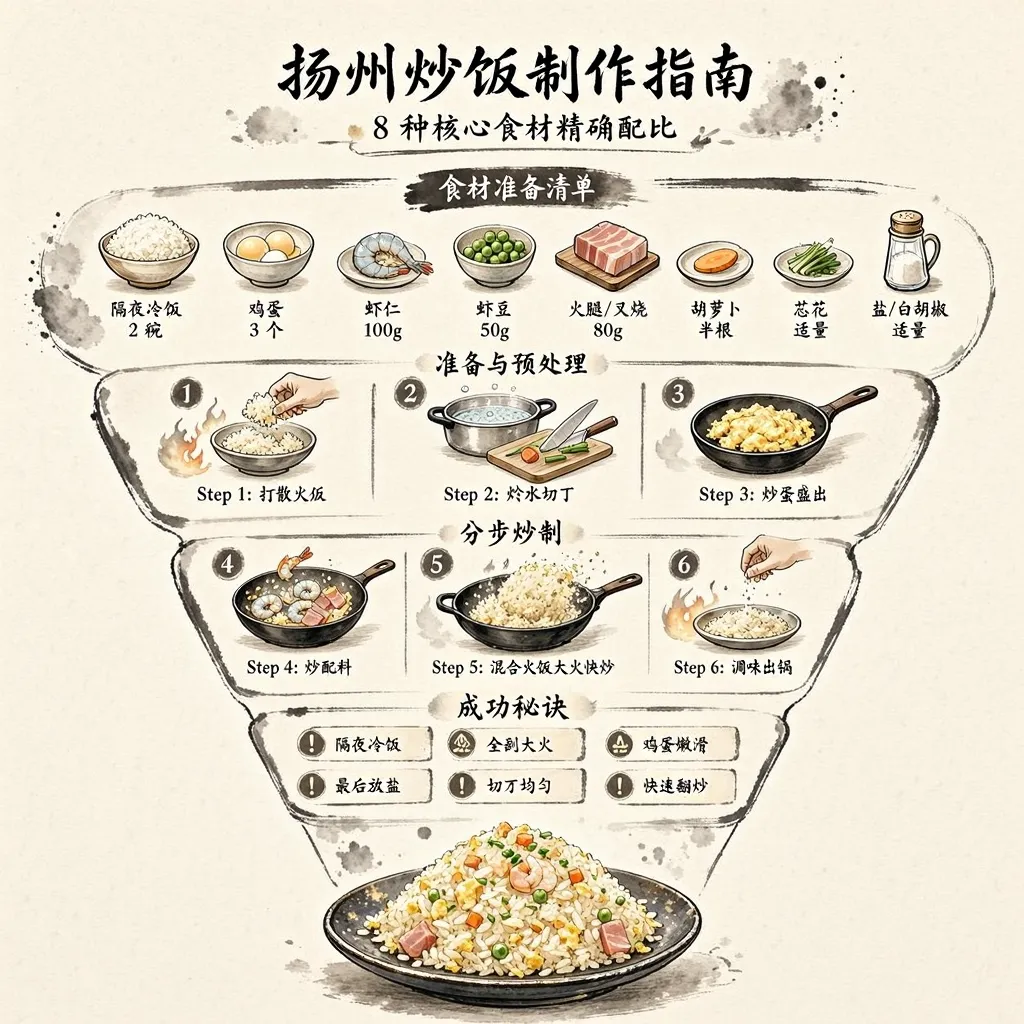
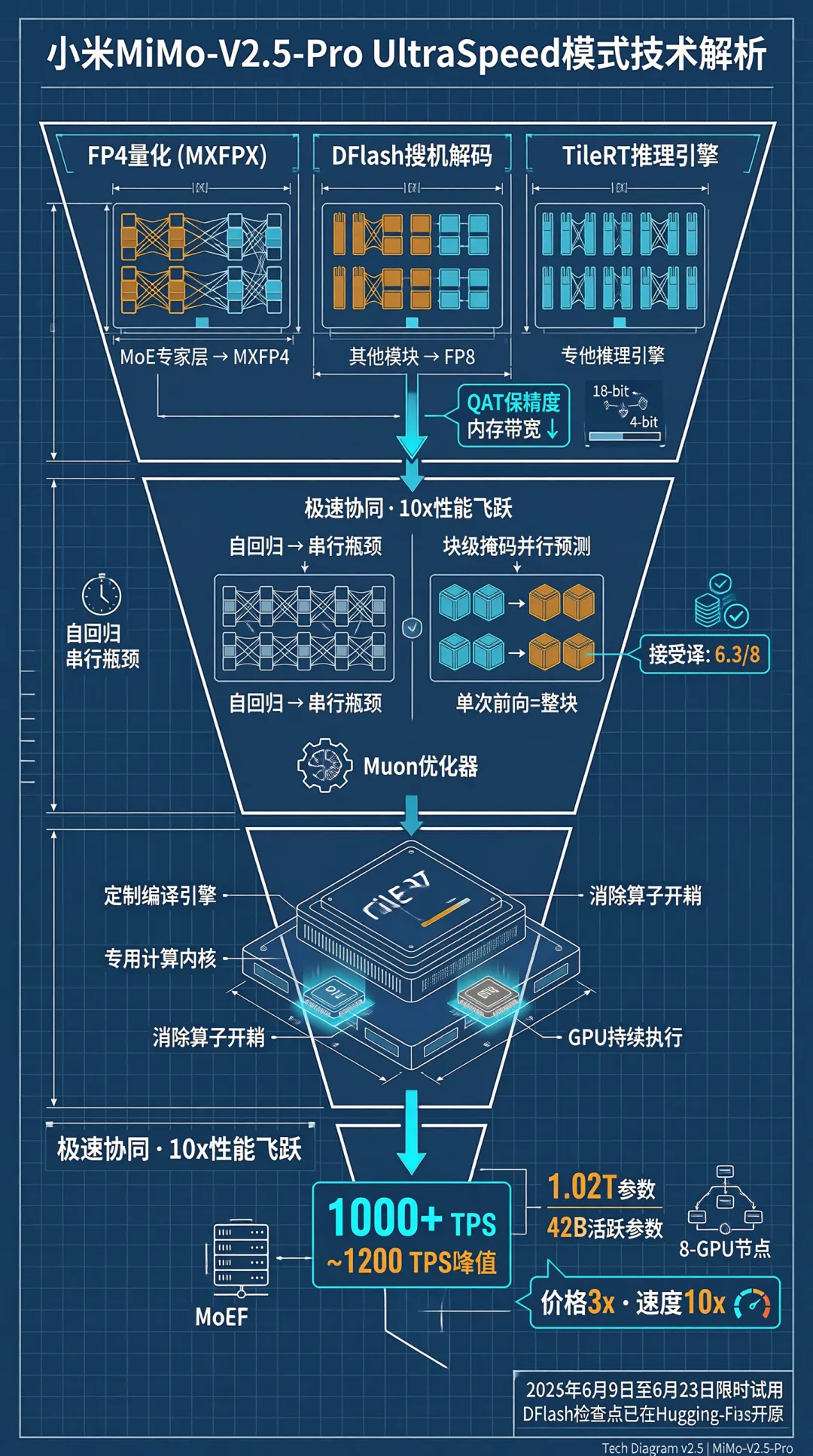
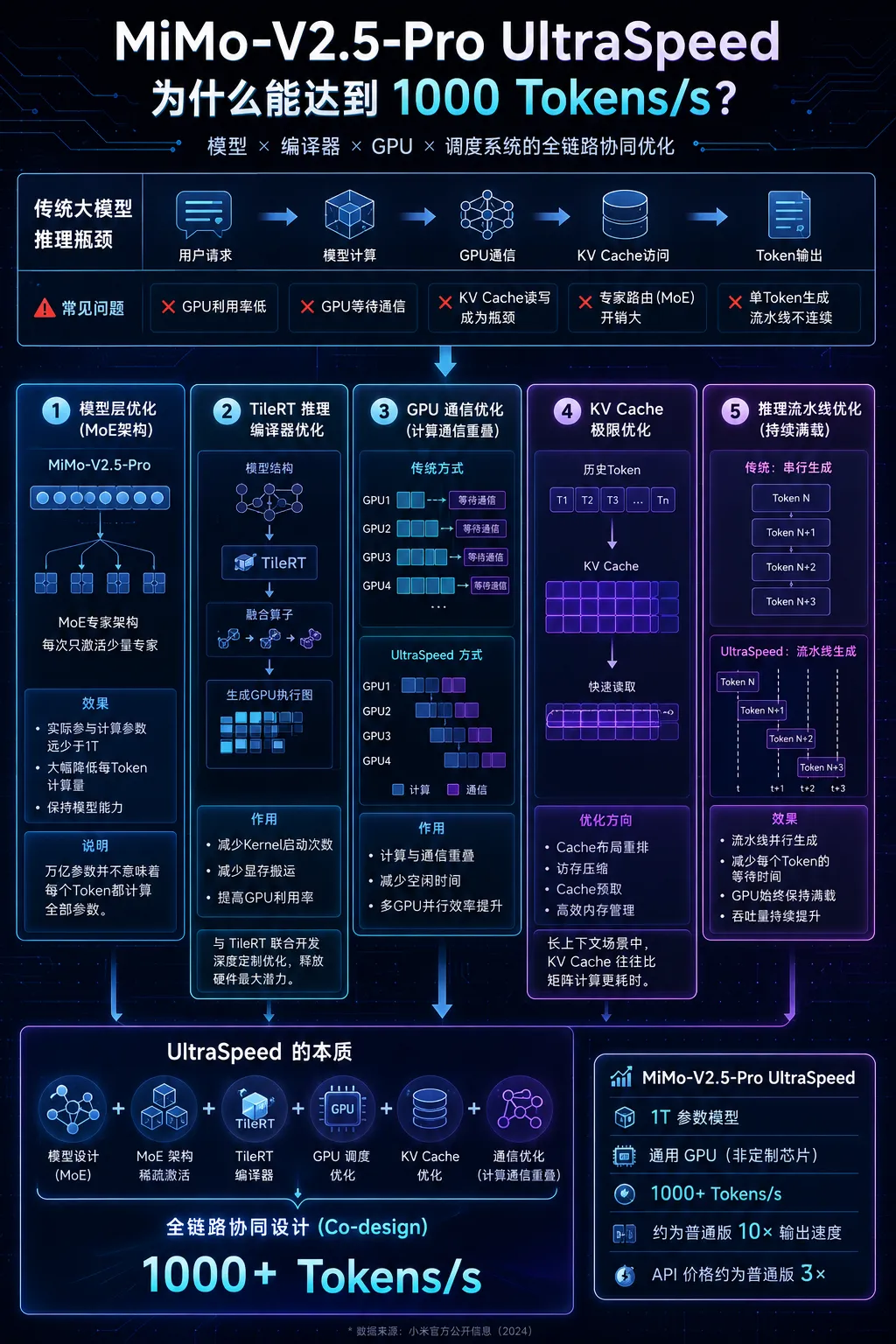
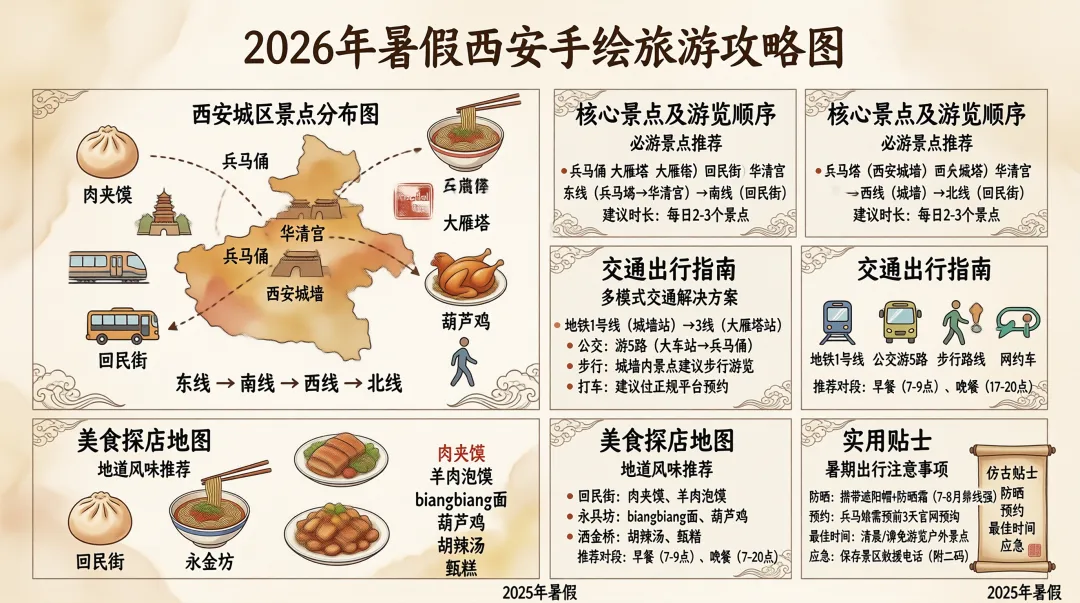
整个构图还是不错的,该有的要点也都写上去了。不过仔细地去看,还是可以发现有些汉字渲染得不对,例如step 2: 焯水切丁。文字渲染应该是 sensenova-u1-fast 模型的问题了。在存放图片的目录下,还可以看到不少的中间生成文件。其中的 expanded-prompt.txt 就是最后文生图的提示词了。既然有生成图片的提示词,交给更强大的文生图模型,看看画出来的效果怎样。sn-image-base 技能除了支持商汤自家的模型,也支持nano banana以及gpt-image,不过要花钱买api了。不花钱可以到网页去生成。对比之下,gpt-image2 图片的精美度是遥遥领先的。怎么做扬州炒饭,这是大模型内在的知识就知道的。再试个例子,大模型不知道的新知识。提示词:用一张信息图,解释小米MiMo-V2.5-Pro的UltraSpeed模式是怎么实现这么快的生成速度的。opencode执行时,也知道先用Web Search功能了解相关技术背景,看懂了之后再开始作图这次对比一下,在chatgpt里面同样用“用一张信息图,解释小米MiMo-V2.5-Pro的UltraSpeed模式是怎么实现这么快的生成速度的”,画出来的图片。chatgpt收到指令后第一轮并没有作图,而是先通过文本回答了快的原因,并询问需要的作图风格。在确定了作图风格后,第二轮才把图片画出来。毫无疑问,gpt-image 2的图片更加美观,解析也更详尽。但是gpt-image 2回答的点似乎有点偏了,FP4量化和DFlash两个关键的技术都没有提到。而商汤的图,还是文字渲染有点小瑕疵。再一个测试例子:设计一款2026年暑假西安手绘旅游攻略图,要有攻略、有景点、有交通信息、有美食推荐,横版,适合大屏阅读,风格及视觉元素匹配西安的历史感。宽高比21:9。不过这次执行,中间出了岔子。因为中文编码的问题,中间文件变成了乱码,最后画出来的图也出问题了。又让AI重新搞了一次才正确生成。不过sensenova-u1只支持16:9的画面,最终画出来的是16:9的还是文字渲染问题,核心景点和旅游顺序写了两遍,而且两遍的内容互相矛盾。这套skill,设计能力是可以的,就是生图模型拖了后腿,得配合更强大的闭源商业模型才能发挥出实力。 夜雨聆风
夜雨聆风