 夜雨聆风
夜雨聆风write_file 看着比较简单——一次 os.WriteFile 就完事了。但放到 Agent 手里,它是把双刃剑,一刀下去能把刚改好的文件覆写成模型脑补的样子。
零、背景
前二十篇文章把 Agent 的整体骨架——Loop、工具、上下文记忆、上下文压缩、MCP、Skill、TUI、任务规划、子代理、命令、跨会话记忆、Agent.md、系统提示词、任务持久化、会话持久化、goal 命令、后台任务、定时任务、Teammate、自定义子代理 都讲了一遍。
第二十一篇文章开始精读 Claude Code 源码,之前已经介绍了 读文件 工具。
这一篇接着上一篇,精读 read 的另一个搭子——write_file。
写文件这件事看起来比读还简单——一行 os.WriteFile 就完事了。
但放到 Agent 手里,它是把双刃剑——一刀下去能把刚改好的文件覆写成模型脑补的样子,几千行代码瞬间消失。
Claude Code 仓库里这个工具叫 FileWriteTool,TypeScript 源码加上 prompt 几百行。

一、写文件这件事,比想象中危险
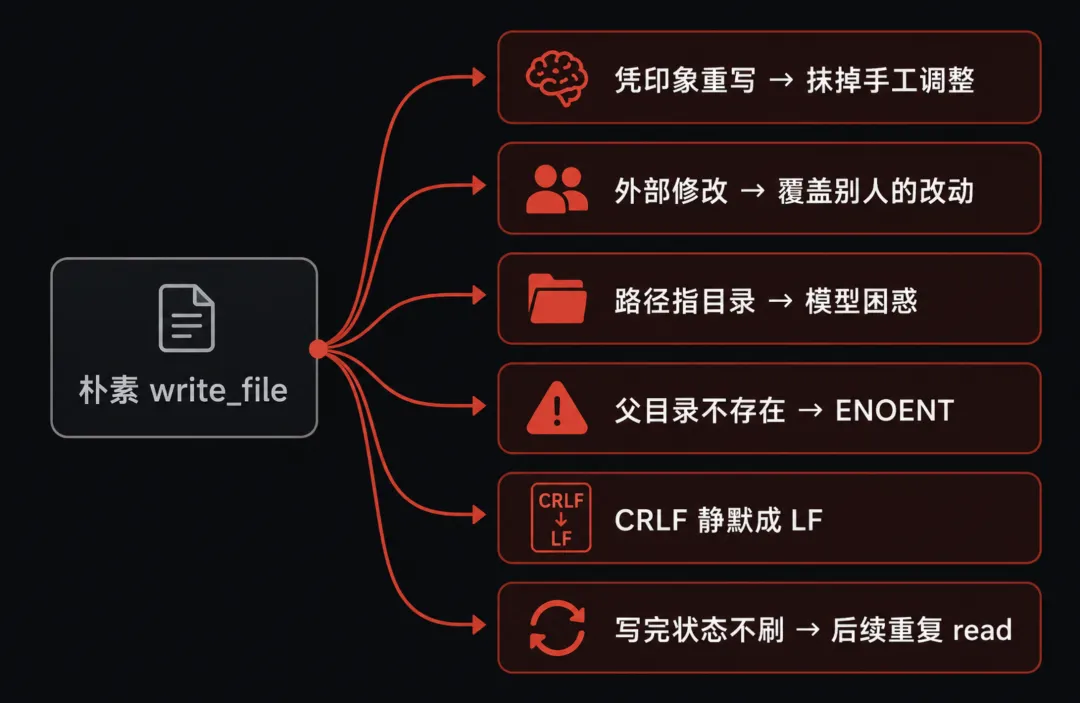
最朴素的 write_file 大概是这样的:模型给一个 file_path 和一段完整的 content,工具调用一次 os.WriteFile,结束。
十行不到的代码。但只要这个工具被 Agent 调用过几百次,下面这些事故就会一桩桩冒出来。
模型「凭印象重写」。
模型没读过这个文件,但它觉得自己「应该知道这个文件长什么样」,于是把整个文件按印象重新生成一份,扔进 write_file。
外部修改了文件。
模型 5 分钟前读过 main.go,期间用户手动编辑了一次,文件已经不是当时那个文件了。
模型基于过期内容生成的「完整版本」覆盖回去,等于把别人的改动全部丢掉。
目录被一刀写成文件。
file_path 写错指到一个目录,朴素的 os.WriteFile 会报错,但错误信息对模型不友好,可能会把它带到「我先 rm -rf 这个路径吧」的糟糕路径上。
父目录不存在。
模型想创建 pkg/utils/helper.go,但 pkg/utils/ 目录本身还没建。
os.WriteFile 直接报错 ENOENT,模型一头雾水。
CRLF 文件被静默改成 LF。
write_file 是整个文件覆写,原来的换行风格直接没了。
写完之后状态没维护。
写完之后再 read,缓存里还是旧版本;
一次操作变两次。
二、和 edit_file 的分工:什么时候才该用 write
在 FileWriteTool 的 prompt 描述里有这样一句话。
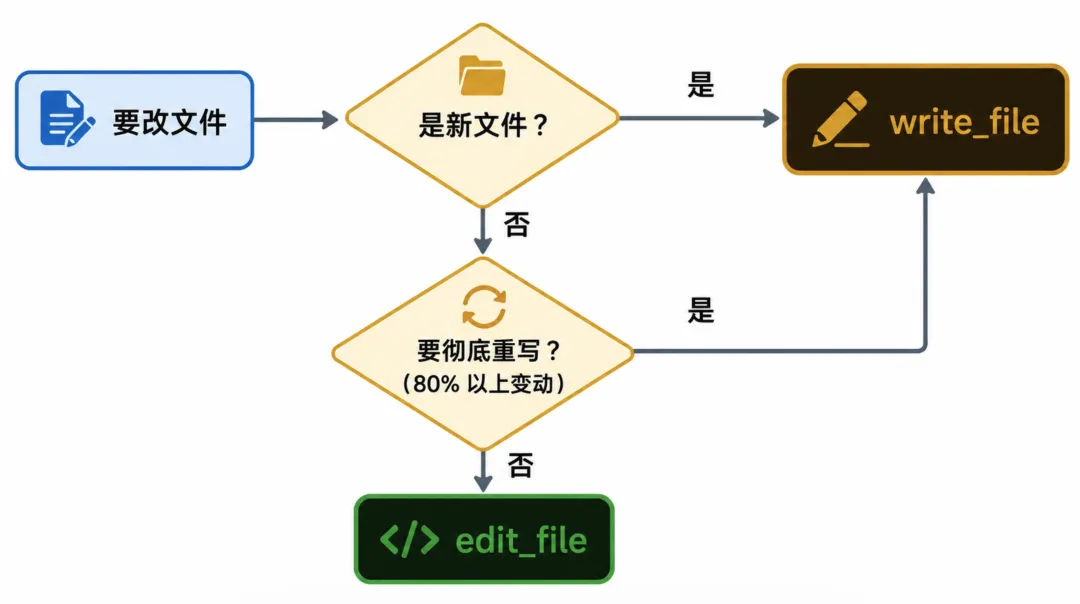
Prefer the `edit_file` tool for modifying existing files — it only sends the diff. Only use this tool to create new files or for complete rewrites.这是工具设计上的明确分工。
write_file 只在两种场景里出场:第一是创建一个全新的文件,第二是对已有文件做完整重写。
其它所有场景应该走 edit_file。
这个分工是为了省 token 和降风险。
edit_file 只发 old_string 和 new_string 两段,几百字符就能改一行;
write_file 必须把整个文件原样发一遍,几千行的文件要塞几万 token 进 prompt。
降风险才是更重要的那一面。
edit_file 改的是文件的局部,原文里那些模型没碰过的部分天然保留;
write_file 是整文件覆写,原文里任何东西都得在 content 里被显式重写出来才能保留,任何遗漏都是删除。
所以能用局部改的地方绝不用整体重写,把模型可能搞错的地方收窄到最小。
三、Must read first
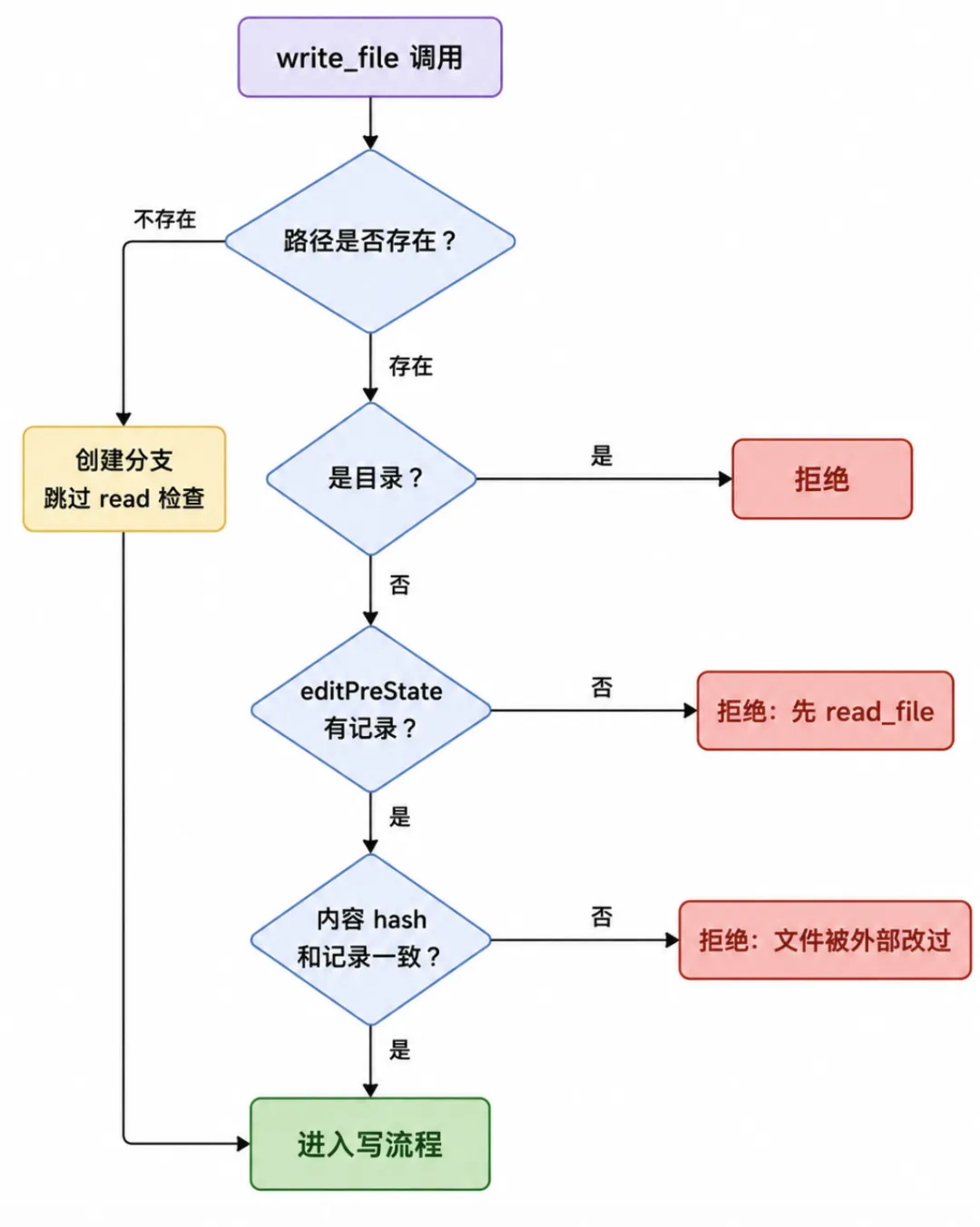
「写之前必须读过」这道前置检查,write_file 和 edit_file 共用一份状态——editPreState。
type EditPreState struct {Mtime int64Hash [16]byte}var editPreState = map[string]EditPreState{}
read_file 每次完整读完一个文件就在这张表里记一笔 (absPath, mtime, hash),write_file 进来后第一件事就是查这张表:
pre, hasPre := GetEditPreState(absPath)if !hasPre {return "", fmt.Errorf("write_file: %s has not been read in this session — call read_file on the full file before overwriting it",filePath,)}
注意这道检查只对「已存在的文件」生效。
如果 file_path 指向一个不存在的路径,那这是「创建新文件」场景,没有「读过」的前提可言,跳过这道检查直接进入写流程。
这道分支判断就是把这两种场景的安全边界对齐到了同一行代码里:「文件存在 → 必须读过;文件不存在 → 直接写」。
四、No stale writes:写之前再 hash 一次
即使读过了,也不一定能写。
文件可能在「读」和「写」之间被外部修改——用户手动保存、IDE 的 format-on-save、git checkout、prettier、pre-commit hook。
所以需要先 ReadFile 再 hash 比对,再 WriteFile。
理论上 hash 比完到 WriteFile 之间还可能被改一次。
对于一个 LLM Loop 来说,这个窗口几乎不会构成事故。
为什么 hash 而不是 mtime
mtime 在某些情况下会更新但内容没变,按 mtime 拒绝反而会浪费token。
代价是读一遍文件做哈希,对几百 KB 的源代码文件几乎可以忽略。
五、CRLF:故意不保留
write_file 的策略为——读到什么就写什么,不做任何 CRLF 还原。
例如,bash 脚本在 Linux 上必须是 LF 结尾。
如果一个仓库里有文件因为某种历史原因变成了 CRLF,模型纠正这个错误后, 工具保留 CRLF 又给改回去,那么 LLM 永远都无法纠正这个错误。
所以 FileWriteTool显式不保留 CRLF 。
六、父目录创建:MkdirAll 提到关键路径之前
创建一个新文件时,父目录不一定存在。
朴素的 os.WriteFile 在这种情况下直接 ENOENT,给模型一个「no such file or directory」的错误。
模型当然能看懂,但接下来它可能会:先调一次 bash mkdir -p pkg/utils 再重试。
多一轮工具调用是真实的 token 浪费。
FileWriteTool 在写文件之前主动 MkdirAll:
if err := os.MkdirAll(filepath.Dir(absPath), 0o755); err != nil {return "", fmt.Errorf("write_file: mkdir: %w", err)}if err := os.WriteFile(absPath, []byte(content), 0o644); err != nil {return "", fmt.Errorf("write_file: %w", err)}
七、写完反馈:创建 vs 更新
write_file 在 tool result 里做了一份针对模型的反馈优化。
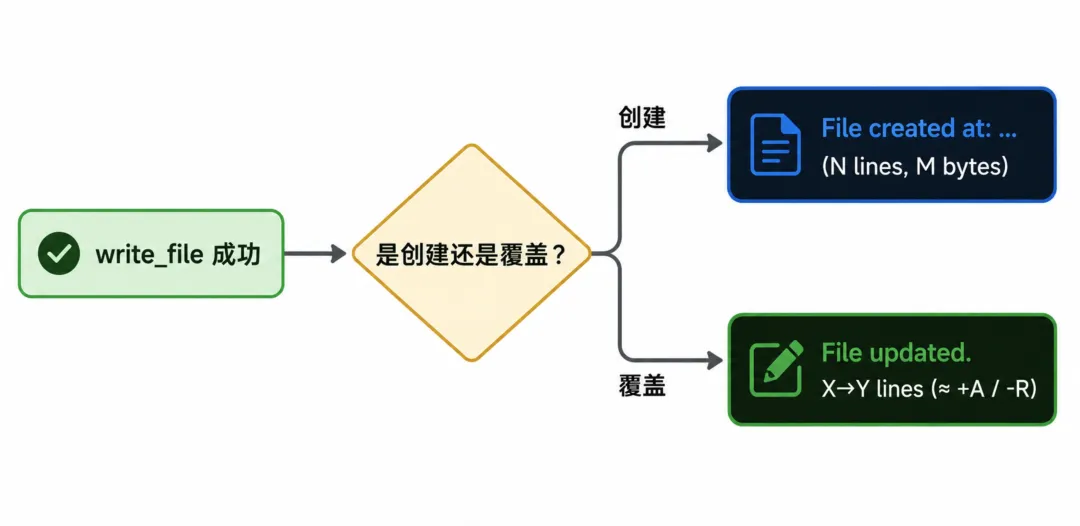
最朴素的反馈是「success」或者「failed」一句话完事。
模型只能从「没报错」推断写成功了,但不知道写了多少、写到哪个具体路径、是新建还是覆盖。
FileWriteTool 把这一步分成两种回复。
创建场景的回复:
File created successfully at: pkg/utils/helper.go (wrote 42 lines, 1234 bytes).覆写场景的回复:
The file main.go has been updated successfully.120 line(s) before, 135 line(s) after (≈ +18 / -3).
创建场景里报「写了多少行多少字节」。
覆写场景里报「前后行数」+「近似增删」。
这是一个非常明显的「写超过预期」的信号,可以让模型在下一轮主动验证写的是否符合预期。
八、写后状态维护:让 read 看到新世界
写完之后,所有相关的内存状态都要刷一遍。
InvalidateReadState(absPath)if newInfo, statErr := os.Stat(absPath); statErr == nil {RecordEditPreState(absPath, newInfo.ModTime().UnixNano(), []byte(content))}
第一件事是把 read 去重缓存里这个文件的条目清掉。
否则下一次 read_file 调用进来,看到缓存存在,就会返回 File unchanged since last read.
而实际上文件已经被 write_file 整个覆写过了。
第二件事是用新内容重新 RecordEditPreState。
这一步是为了让模型可以在同一个 turn 里连续写或者改同一个文件。
write_file 创建完 helper.go,下一步直接 edit_file 给它加几行内容,不需要中间再插一次 read_file。
这个一致性是工具集层面的契约,单个工具的实现只要触碰共享状态就要负责把它刷正确。

九、什么没移植
对照上游 FileWriteTool.ts,evo-agent 当前版本故意没做几件事。
Notebook 写入——.ipynb 文件按 cell 改写、保留 metadata。
这条会随 read_notebook / edit_notebook 单独成一个工具一起做。
Diff 渲染——上游的 tool result 里会附带一个结构化 diff 给前端 UI 渲染绿/红色块。
evo-agent 的 TUI 没有 diff 面板,用文本的 +18 / -3 概要替代,已经够用。
1 GiB 写入硬上限——上游为了防止 V8 字符串爆掉加了这道闸。
Go 侧 string 没有这种限制,但是单次写 1 GiB 仍然会消耗大量内存,这条之后会按需补。
这些点不是「不需要」,是「场景不同所以暂时不做」。
一个工具的复杂度本身就是它服务场景的折射。
十、最后
回头看一下 FileWriteTool 解决的问题清单。
前置检查、no stale writes、CRLF 显式不保留、MkdirAll 提到关键路径之前、创建/覆写区分反馈、近似 diff 让模型 sanity check、写后刷新共享状态。
写文件这件事看起来是 read_file 的对偶,但它多了一层「破坏不可逆」的属性。
读错了重读一次就好,写错了文件就回不去了。
所以 write_file 上的设计哲学和 read_file 不太一样:read 的目标是「省 token、稳输出」,write 的目标是「别让模型把自己不知道的东西覆盖掉」。
下一篇接着聊这一组里最复杂的那个——edit_file。
它把 read 和 write 放进了同一个调用,复杂度也跟着上了一个台阶。
《完》
-EOF-
