 夜雨聆风
夜雨聆风很多老板对 AI 的态度是:想用,但不敢用。
合同、客户名单、财务报表,传到别人服务器上,心里不踏实。律所、会计师事务所、做政企生意的公司,这个顾虑更重——有些数据按规定就是不能出内网。
过去的答案是「那就别用了」。2026 年有了新答案:把模型装进自己电脑,数据一个字都不出门。
两年前,在自己电脑上跑大模型,还是个以失望告终的周末实验。今天不一样了:几百块的树莓派(巴掌大的小电脑)能跑聊天机器人,一台 MacBook Air 能跑到当年 GPT-3.5 的水平,一块 700 美元的二手 RTX 3090 显卡,能给你接近 GPT-4 的东西。问题不再是「能不能跑」,而是:该装哪个工具、配什么电脑、值不值得花钱。
这篇把三个问题一次讲完,每一步写到「在哪点什么、敲什么命令」,照着做就能跑起来。文里点名的工具和数字,我都去官网、GitHub 一个个核过。
先把账摆全。本地跑模型的好处,不止「数据不出门」一条:
1.隐私:提示词和数据全程不离开你的机器。律师、医生、财务,这条没得商量
2.省钱:用量大的话,几个月回本,之后没有按字计费,没有限速
3.离线能用:飞机上、地下室、保密场所、网络差的工地——云端 AI 罢工的地方它照干
4.不矫情:开源模型不会因为过度谨慎,把正常的活也拒了
5.学得最快:想真搞懂 AI 是怎么回事,自己跑一遍是最短的路
代价后面「丑话」那节讲。下面按能直接抄的顺序,一层一层来:先搞懂底牌,再挑工具,再配机器,最后算账。
一、先搞懂一件事,少走一半弯路
市面上的本地 AI 工具有十几个,名字一个比一个唬人。但底牌其实很简单:它们底下几乎是同一个引擎,叫 llama.cpp,真正负责「算字」的就是它。
Ollama、LM Studio、GPT4All,全是在这个引擎外面套壳。壳和壳的区别只在三点:有没有图形界面,装起来麻不麻烦,能不能当服务器给多人用。
二、四个工具,对号入座,附装法
Ollama,默认选项。命令行操作(就是在黑窗口里敲命令),别被吓到,全程就一条命令。它自带一个和 OpenAI 格式兼容的接口,市面上几乎所有 AI 开发工具都认它——以后想把 AI 接进自己的系统、做自动化,走它阻力最小。缺点也直白:没有图形界面。
装法,四步:
① 浏览器打开 ollama.com,点 Download,选你的系统(Mac、Windows 都有),下载完双击安装
② 打开终端:Mac 按 Command+空格,输「终端」回车;Windows 按 Win 键,输 cmd 回车——就是那个黑窗口
③ 敲 ollama run qwen3:8b,回车。第一次会自动下载模型,5GB 多,等进度条走完
④ 看到 >>> 提示符就成了,直接用中文问它问题。想退出,敲 /bye
装完顺手验证一下:浏览器打开 localhost:11434,看到 "Ollama is running" 几个字,说明它已经在后台待命,随时能接你的脚本和系统。
不想敲命令的,用 LM Studio。图形界面,自带模型商店。Mac 用户还有额外福利:它内置了苹果自家的 MLX 加速框架,同一台 Mac 比用别的工具跑得快。缺点是不开源,介意的人会介意。
装法,三步:
① 浏览器打开 lmstudio.ai,下载安装
② 打开后点搜索(放大镜图标),搜 qwen,列表里挑一个体积不超过你内存一半的版本,点 Download
③ 下载完切到聊天页,顶部选中刚下好的模型,开聊
家里有老电脑的,认准 GPT4All。没显卡、内存 8GB 以下的旧机器也能跑。慢,但能用。装法和 LM Studio 一个路数:gpt4all.io 下载安装,打开后在模型列表里挑个小的(Phi-3 Mini 就行),下载完直接聊。公司里那台积灰的旧笔记本可以拿来当试验品。
要给全公司几十号人同时用,上 vLLM。前三个都是单人工具,这个是公司级方案:同样一块显卡,它能比普通方案多扛 2 到 4 倍的并发请求。代价是只支持 Linux 加英伟达显卡,部署也复杂,一个人用就别碰它,到了「团队共用」那一步再回来找它。
另外两个点一下名:Jan AI 全开源、不收集任何数据,适合隐私要求顶格的场景;llama.cpp 直接裸用最省资源,整个程序不到 90MB——对比之下,Ollama 装完要占 4.6GB。
三、你手头是什么电脑,就装什么
这部分最值钱,一张硬件对照表,照着找自己的位置:
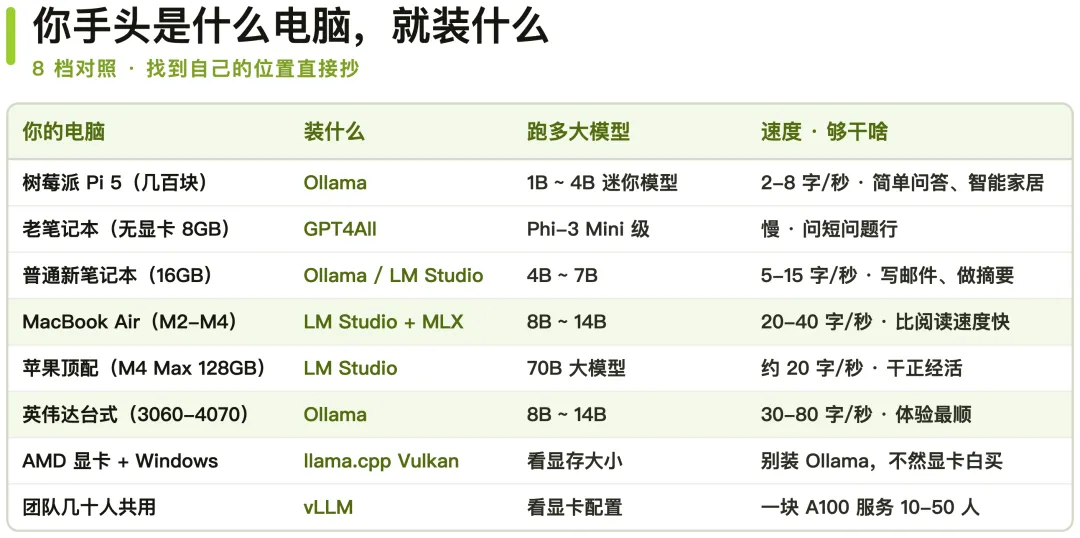
·树莓派 Pi 5(几百块的巴掌电脑,8GB/16GB 内存):装 Ollama,跑 1B~4B 的迷你模型,每秒 2 到 8 个 token。做简单问答、当智能家居的大脑够了,别拿它写正经东西。这是本地 AI 的最低入场价。
·老笔记本(i5、无显卡、8GB 内存):装 GPT4All,跑 Phi-3 Mini 这种小模型。慢,问短问题行,别指望写长文。
·普通新笔记本(16GB 内存、无独立显卡):装 Ollama 或 LM Studio,跑 4B 到 7B 级别的模型。B 是参数量单位,越大越聪明,也越吃硬件。每秒输出 5 到 15 个 token(模型吐字的单位),写邮件、做摘要够用。
·MacBook Air(M2/M3/M4 芯片):装 LM Studio、开 MLX 加速,跑 8B 到 14B 模型,每秒 20 到 40 个 token,比你阅读的速度还快。苹果芯片在这件事上出乎意料地能打。
·苹果顶配(M4 Max、128GB 内存):能跑 70B 大模型,每秒约 20 个 token,干正经活没问题。靠的是苹果的统一内存——同样能力放在 PC 上,得配五千美元的专业显卡。
·英伟达显卡台式机(RTX 3060 到 4070):装 Ollama,8B 到 14B 模型每秒 30 到 80 个 token,几档里体验最顺的。
·AMD 显卡加 Windows:别装 Ollama,用 llama.cpp 的 Vulkan 模式或 LM Studio,不然显卡白买。
·团队多人共用:vLLM,一块 A100 显卡能同时服务 10 到 50 个人。
跑什么模型?推荐两个国产的:Qwen(阿里开源的通义千问)和 DeepSeek。中文能力比海外开源模型靠谱。在 Ollama 里就是一条命令的事:ollama run qwen3:8b 或 ollama run deepseek-r1:8b,数字按上面表里你那一档能跑的大小换。
四、进阶:四台 Mac mini 跑「满血版」DeepSeek
4 台 Mac mini,用一个叫 EXO 的开源软件连成集群(几台机器拼成一台用),就能跑起 6710 亿参数的 DeepSeek——就是大家说的「满血版」。没有数据中心,没有云,没有一次 API 调用。
EXO 的原理是把模型切开,分到每台机器上各算一段。它在 GitHub 上开源(搜 exo-explore/exo,4.5 万星),官方数据:2 台机器最多提速 1.8 倍,4 台提速 3.2 倍。
最省心的是组网:把几台机器连进同一个局域网(插同一台路由器、连同一个 Wi-Fi 就算),每台装上 EXO,它们会自动发现彼此、自动组成集群,不用手动配置。
五、替你算笔账
入门档:0 元。现有电脑装 Ollama,跑个 7B 的 Qwen,一个晚上搞定。先试清楚本地模型够不够用,再谈花钱。
像样档:一台 Mac mini M4(16GB 内存),官网起售价 4499 元。跑 7B 到 14B 模型很轻松,可以当小团队的内部 AI 服务器,全天开着。
认真档:二手 RTX 3090(24GB 显存),市价五千上下(行情价,以实际成交为准),配台机器跑 32B 级模型,能给你接近 GPT-4 的东西。

买不买,不拍脑袋,先把自己的真实开销查出来。三步:
① 查 API 账单:用 OpenAI 的,登 platform.openai.com,左边菜单点 Usage(用量),按月看;用国内大模型的,去各家控制台的「费用中心」看
② 加上订阅费:ChatGPT Plus、各种 AI 工具会员,全公司一个个数出来
③ 近 3 个月加总除以 3,得出月均
月均两三千元:一台五千块的机器两三个月回本,之后电费几乎可以忽略,值得动手。月均就几十块:别折腾,API 继续用,这篇存着,等用量上来再说。本地部署是给「用量大」或「数据敏感」的人准备的。
什么样的企业值得做?三条占两条再动手:
1. 数据敏感:合同、病历、财务、政企项目
2. AI 用量大:月开销稳定超 2000 元
3. 团队里有一个愿意折腾电脑的人
这账划不划算,你自己看。
丑话说在前面
本地模型干不过云端最强的。最难的推理任务上,最好的本地模型仍然落后 GPT-5.1 和 Claude 这一档。
所以别想着一步到位全替换。先拿现有电脑试,试明白了再花钱。
往后看,三件事
1. MCP(让 AI 接外部工具干活的通用接口)正在变成标配,LM Studio 已经装上了,到年底主流本地工具都会跟上——到时候本地模型也能像云端 AI 一样「接活干」,不只是聊天
2. 手机端要起飞,正经的本地 AI 正在往手机里搬
3. 和云端的差距会继续缩小,但最顶尖那一档短期内仍是云端独有——所以「二八开」的用法,一两年内都不会过时
给中小企业的能抄清单
1. 今晚就能做:去 ollama.com 下载安装,敲 ollama run qwen3:8b,拿你平时问 ChatGPT 的问题问它,亲自感受差距有多大
2. 翻出公司最旧的还能开机的电脑,装 GPT4All,测出你的「零成本底线」在哪
3. 按第五节的三步,拉出过去 3 个月的 AI 开销,月均超 2000 元,再考虑买硬件
4. 列一张「数据敏感业务清单」:合同审阅、客户资料整理、财务分析——这些是最先搬到本地的活
5. 多人共用别一步到位:10 人以内每人装 Ollama 各用各的,超过 10 人同时用再上 vLLM
