 夜雨聆风
夜雨聆风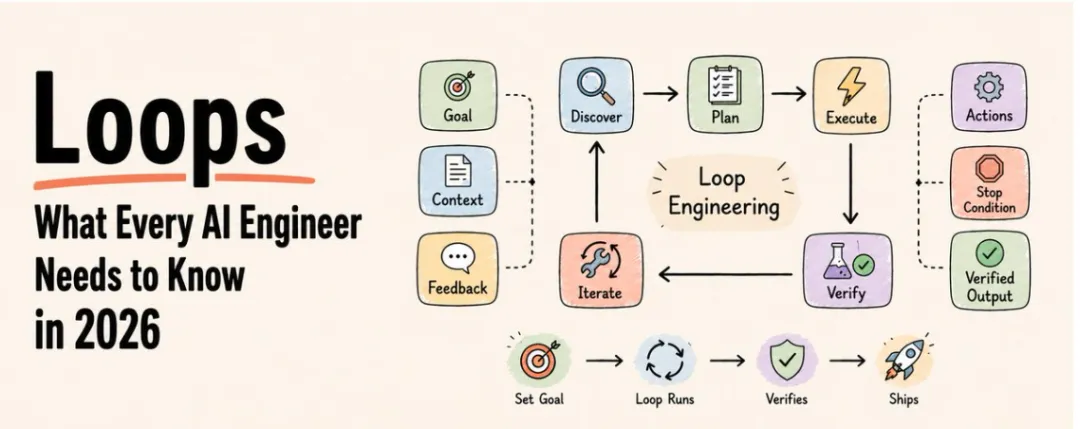
从"怎么写好提示词"到"怎么设计让 AI 自己跑起来"——这个转变值一整篇文章。
先看一下我的小南瓜(openclaw agent)一次性成功做的坦克大战游戏:
Claude Code 负责人最近说了句话
Boris Cherny(Claude Code 负责人)在一期播客里说了一句:
"我不再写提示词了,我的工作就是写 loop。"
OpenClaw 的作者 Peter Steinberger 跟了一条推,被转了几百万次:
"你不应该再手动给 Agent 写提示词了,你应该设计让 Agent 自动跑起来的 loop。"
Addy Osmani 随后写了一篇长文,正式把这事儿命名为 Loop Engineering——2026 年 AI 圈最火的新概念之一。
什么是 Loop Engineering
先说人话。
以前你怎么用 AI 编程?一条条写 prompt 喂给它——"帮我写这个函数"、"改一下那个逻辑"、"帮我 review 这段代码"。每次都是人主动,AI 被动。
Loop Engineering 的思路完全不同:写一个"循环程序",这个程序自动去找任务(读 GitHub issue、扫 CI 失败),自动把任务丢给 AI Agent,自动验证结果对不对,不对就再跑一轮。
人在整个过程里的角色,从"喂 prompt"变成了"设计 loop 的规则"。
传统方式:人 → 写 prompt → 丢给 AI → 等结果Loop Engineering:人 → 设计 loop 规则(触发条件 + 验证逻辑 + 失败策略) ↓loop 自动触发 → AI Agent 执行 → 验证结果 ↓失败 → 回到触发,不对 → 继续跑成功 → 报告人,结束这不是在说"AI 会取代人",这是在说"人应该从操作者变成设计者"。
Loop Engineering 的四个关键组件
根据 Addy Osmani 的框架,一个完整的 loop 包含:
1. 触发条件(Trigger)
什么时候启动 loop?常见的触发方式:
Cron 定时:每隔 N 分钟扫一次 GitHub Issues 事件驱动:PR 创建、CI 失败、issue 更新 人工唤醒:用户说"去做 XX"
没有触发条件,loop 就不会跑。
2. 执行层(Agent)
收到任务后具体做什么。这是 Agent 的工作空间:给它什么上下文、什么工具、什么约束。
关键不是"Agent 有多聪明",而是"Agent 所在的环境设计得有多好"。这又回到了 Harness Engineering 的核心:Agent = Model + Harness。
3. 验证层(Verify)
Agent 跑完了,怎么知道它做对了?
这是最容易被忽视的一环。大多数 Agent 系统没有真正的验证层——跑完就结束了,不检查结果对不对。
验证可以是:
单元测试是否通过 文件是否按约定格式生成 用户是否确认 结构化断言(比如"JSON schema 是否匹配")
没有验证的 loop 是在闭眼狂奔。
4. 状态管理(State)
Loop 跑了 5 轮,每一轮的上下文、历史决策、当前进度,需要有一个地方记录下来。
否则第二次触发时,Agent 就不知道上次做到哪儿了、哪个方案试过了、哪个失败了。
我们踩过的坑:一个真实的 Loop Engineering 案例
光讲概念不过瘾。说说我们自己的实践。
我们做了一套 AI Agent 的四层强化系统(agent-reinforcement-system),本质上就是 Loop Engineering 的具体实现。其中 L3 层(OODA+RV 闭环)是最核心的 loop。
过程中踩了两个坑,每个坑都让我们对 loop 的理解深了一层。
坑一:Loop 没有外部强制力
第一个版本(A 版),我把 loop 规则写进了 Agent 的工作规范,让它"自觉"按七步执行:Observe → Orient → Decide → Act → Verify → Record → Loop。
规则写得明明白白。验证步骤要求:用工具实际检查,不能凭感觉。
然后我用一个任务测试:让 Agent 自己做一个网页版坦克大战游戏。
结果:游戏做完了,但玩家坦克出生在基地上,被卡死不能动。Verify 步骤被完全跳过。然后让他修改了一版,结果直接黑屏了。
根因分析:规则写进文档里,Agent 执行时跳过就是跳过,没有外部机制强制它执行。
这暴露了一个根本问题:Loop 的每个步骤,如果没有外部强制,就不是真正的步骤。
坑二:Loop 没有状态持久化
第二个版本(B 版),我吸取了教训,把 loop 做成了一个真正的 runtime:
每一步的执行结果写入 checkpoint 文件(JSON) Cron 定时触发,每次只执行一步 Verify 步骤不通过,不推进到下一步,直接回到 Observe 重来
用同样的坦克大战任务测试:一次通过,零 bug。
关键区别:B 版的 Verify 是被系统强制执行的,不是靠 Agent 自觉。失败就回到上一步,没有任何妥协空间。
A 版 Loop(没有外部强制):Observe → Orient → Decide → Act → Verify(跳过)→ Record → 交付 ❌B 版 Loop(有外部强制):Observe → Orient → Decide → Act → Verify(失败) ↑ ↓ ← ← ← ← ← ← ← ← ← ← ← ← ← ← ← Record(重新来过)✅Loop Engineering 的取舍
Loop Engineering 不是银弹。有两个明显的缺点:
1. Token 消耗大
每个 loop 迭代都是一次完整的 Agent 调用。每次验证失败都会触发新一轮调用。如果 loop 设计得不好(比如验证条件太松),同一个任务可能跑几十轮,Token 账单爆炸。
Addy Osmani 自己也在文章里承认:token 开销波动很大,需要仔细设计停止条件。
2. 不适合所有场景
Loop 适合边界清晰、验证可自动化的任务。比如:代码格式化(检查是否符合规范)、Bug 修复(检查测试是否通过)、文档同步(检查是否更新)。
但对于需要创意判断、依赖主观偏好的任务,强行设计 loop 反而会增加成本。
Loop 设计清单
综合我们自己的实践和行业经验,一个可用的 Loop 需要检查:
[ ] 触发条件:什么事件/时间触发 loop?是否有明确的边界? [ ] Agent 环境:给 Agent 提供的是足够的上下文,还是过多的噪音? [ ] 验证层:有还是没有?验证失败后怎么处理?(回退/重试/人工介入) [ ] 状态持久化:loop 中断后能否恢复?还是从头开始? [ ] 停止条件:最多跑多少轮?什么条件下必须停止? [ ] 成本控制:Token 上限是多少?有没有熔断机制?
开源
我们把整套系统开源了,包括四层架构和完整的 Loop Engineering 实现:
GitHub: https://github.com/jiyangnan/agent-reinforcement-system
包含:
四层架构(第一性原理运行时 + HA 情景记忆 + OODA+RV 闭环 + 一致性恢复) Loop runtime(带状态机、checkpoint 持久化、Cron 驱动) HA 记忆(三级降级:Neo4j → SQLite → 文件 grep) 统一 CLI( xng)
最后
Boris Cherny 说"我不再写提示词了,我的工作就是写 loop"。
这句话值得想一下。
他的意思不是说 Prompt Engineering 不重要了,而是说:**当你开始设计 loop 的时候,你关心的不再是"怎么描述好一个任务",而是"怎么让一个系统持续可靠地完成任务"**。
这是一个维度上的跃迁:从技巧,到系统。
Prompt 是点。Loop 是线,系统的线。
如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐ 我们,下次再见。
当然,欢迎加我个人微信:baiyangwushi ,一起进白羊武士的修炼道场和其他同频道的朋友同频共振**,欢迎 AGI 时代的到来。 也期待在今后的日子里能够与你有羁绊,这是种微妙的感觉。希望我的一些想法能对你有所帮助。欢迎你的到来,修行者。
