 夜雨聆风
夜雨聆风
yt-dlp 最容易被误解成“命令行下载工具”。但从源码看,它真正厉害的地方,是把一个看似简单的 URL 下载任务拆成了几层稳定协议:命令行只负责把用户意图压成参数;Extractor 把不同站点的页面和 API 压成统一信息;Downloader 处理媒体协议和字节写入;PostProcessor 负责把最终文件生产出来。
源码基线:本文基于本地源码目录 sources/yt-dlp,分支 master,提交 acf8ab7a6e3024325f62426e35a17f365c4d5d54,提交时间 2026-05-25T23:21:37+00:00,提交标题 [utils] random_user_agent: Bump version range 137-143 => 142-148 (#16588)。
本文由 AI 辅助完成,可能存在遗漏、理解偏差或版本差异。涉及关键行为时,请以本文固定的 commit、对应源码和官方文档为准自行核对。
先看源码地图
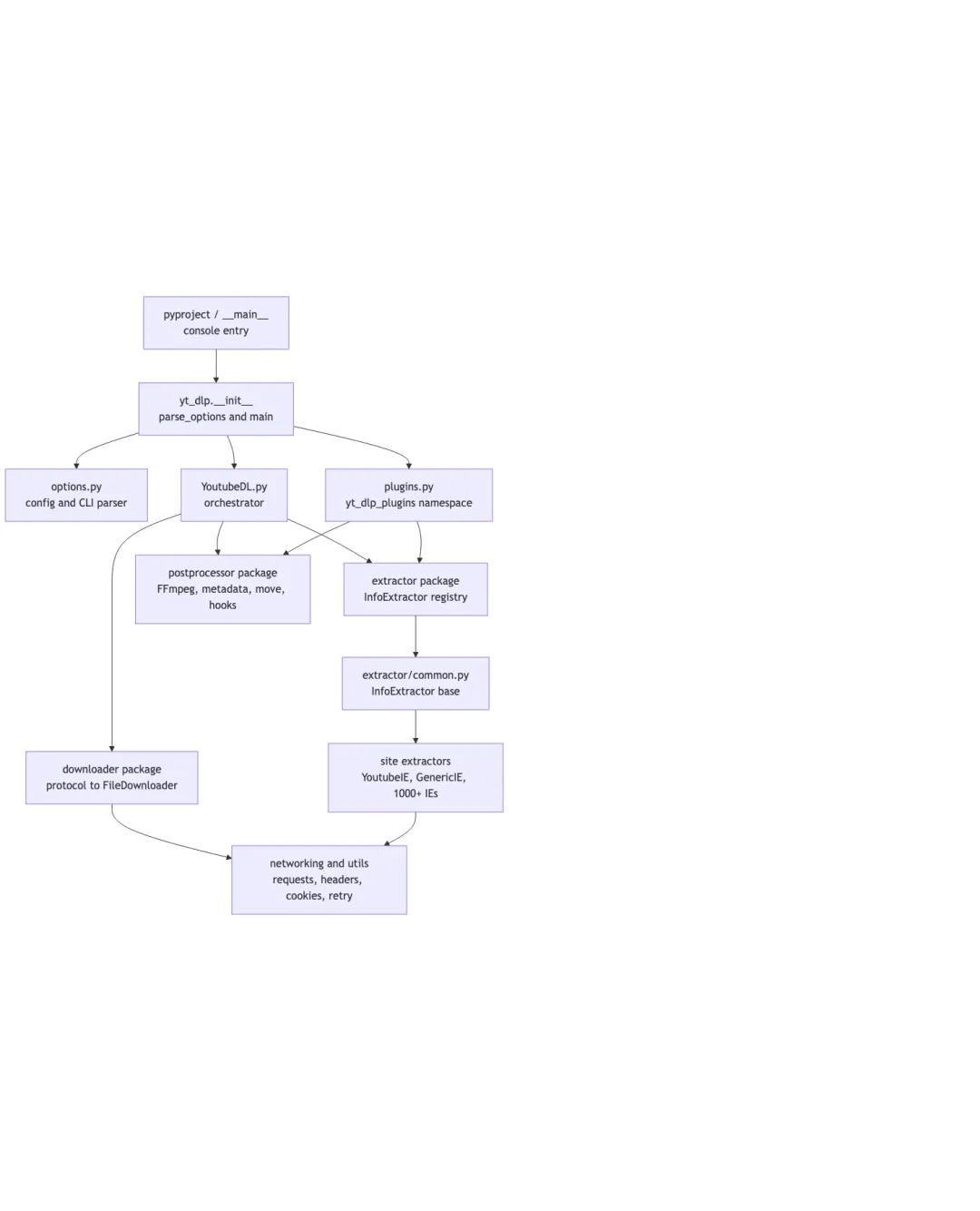
读 yt-dlp 不应该从一千多个站点 extractor 开始。那会很快陷进站点兼容细节,反而看不到主干。
更好的入口是这几块:
- •
yt_dlp/__init__.py:命令行入口和参数组装。 - •
yt_dlp/options.py:配置文件、alias、命令行参数解析。 - •
yt_dlp/YoutubeDL.py:全局调度器,负责 extractor 路由、结果递归、format 选择、下载和后处理。 - •
yt_dlp/extractor/common.py:InfoExtractor的统一契约。 - •
yt_dlp/downloader/:不同协议的下载执行器。 - •
yt_dlp/postprocessor/:合并、修复、写 metadata、移动文件等下载后阶段。 - •
yt_dlp/plugins.py:插件发现和注册。
所以这篇文章只抓一条主线:一个 URL 从 CLI 进入之后,怎样一步步变成最终文件。
CLI 只负责把意图压成 ydl_opts
pyproject.toml 把 yt-dlp 命令指向 yt_dlp:main,yt_dlp/__main__.py 也只是转调 yt_dlp.main()。真正进入业务链路前,_real_main() 会先调用 parse_options(argv),得到 parser, opts, all_urls, ydl_opts。
这里的重点不是 argparse 本身,而是 ydl_opts。它是整条流水线的控制面:格式选择、重试、cookies、proxy、字幕、外部 downloader、ffmpeg 参数、插件目录、geo bypass 等,最后都会被塞进这个字典。
options.py 里还有一个容易被忽略的工程细节:它会按 portable、home、user、system 等层级读取配置文件,也允许 --ignore-config 影响后续加载。也就是说,用户在命令行上看到的是一个工具,源码里先要解决的是“多来源配置如何合并成一次确定执行”。
这一步完成后,_real_main() 创建 YoutubeDL(ydl_opts),再对 URL 调用 ydl.download(all_urls)。从这里开始,CLI 基本退场,主角变成 YoutubeDL。
YoutubeDL 是中枢,不是下载器
YoutubeDL 的类注释已经把职责说得很清楚:它负责调度、写磁盘和下载流程,但不知道某个站点该怎么解析。站点细节交给 InfoExtractor,字节下载交给 FileDownloader,后处理交给 PostProcessor。
初始化时,YoutubeDL 会注册默认 extractor、创建 format selector、挂 progress hook、实例化 postprocessor,并预加载 download archive。这个对象像一个运行时容器:它持有配置、日志、cookie、网络能力和插件对象,同时把这些对象按约定串起来。
这也是 yt-dlp 长期能维护复杂站点支持的关键。站点变化频繁,但只要 extractor 还能产出稳定的 info_dict,后面的 format、downloader、postprocessor 大多不需要知道站点发生了什么。
Extractor 路由:第一个匹配者接管 URL
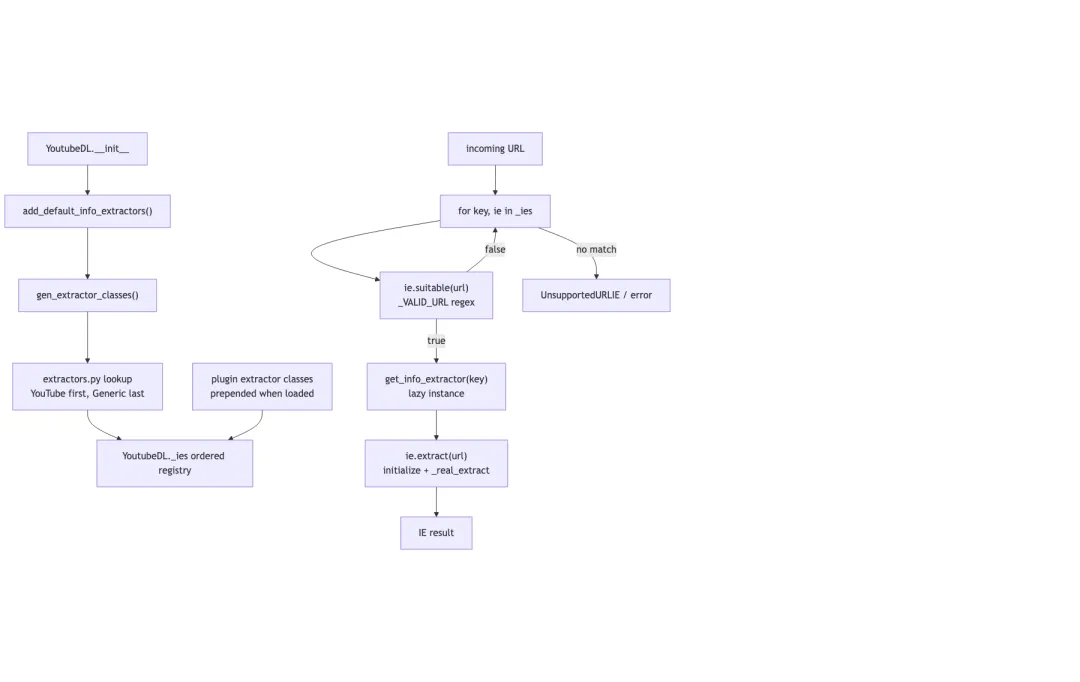
YoutubeDL.extract_info() 会遍历已注册的 extractor:
for key, ie in _ies:
if ie.suitable(url):
return __extract_info(url, get_info_extractor(key), ...)InfoExtractor.suitable() 默认就是用 _VALID_URL 正则判断是否匹配。顺序因此非常重要:extractor/__init__.py 明确说明第一个匹配的 extractor 处理 URL;extractors.py 会把 YouTube 相关 extractor 放前面,把 GenericIE 放最后作为兜底;插件 extractor 也可以 prepend 到主 lookup。
这个设计很朴素,但非常有效。主程序里没有一坨站点 if/else。每个站点只要提供自己的 _VALID_URL 和 _real_extract(),就能进入统一路由。
YoutubeIE 和 GenericIE 是两个很好的阅读样本。YoutubeIE 代表复杂站点:它要处理 watch 页面、player response、播放状态、live、字幕、thumbnail、DRM 等一堆细节。GenericIE 则是兜底:它匹配几乎所有 URL,先判断直连媒体、manifest、RSS、XSPF,再从网页里找内嵌播放器。
InfoExtractor 的产物是 info_dict
Extractor 真正的边界是 InfoExtractor.extract()。它做初始化、打印当前 URL、调用子类 _real_extract(url),再处理 geo bypass、字幕兼容项和异常包装。子类可以很复杂,但最后要尽量把站点差异压成统一结果。
这个统一结果通常就是 info_dict。它可能描述一个视频,也可能描述一个 playlist,甚至可能只是告诉 YoutubeDL:“请用另一个 extractor 继续处理这个 URL。”
这解释了为什么 yt-dlp 不是简单的一次函数调用。它更像一个递归解释器:extractor 先产出一个结构化结果,YoutubeDL 再根据 _type 决定下一步。
IE result 为什么会递归
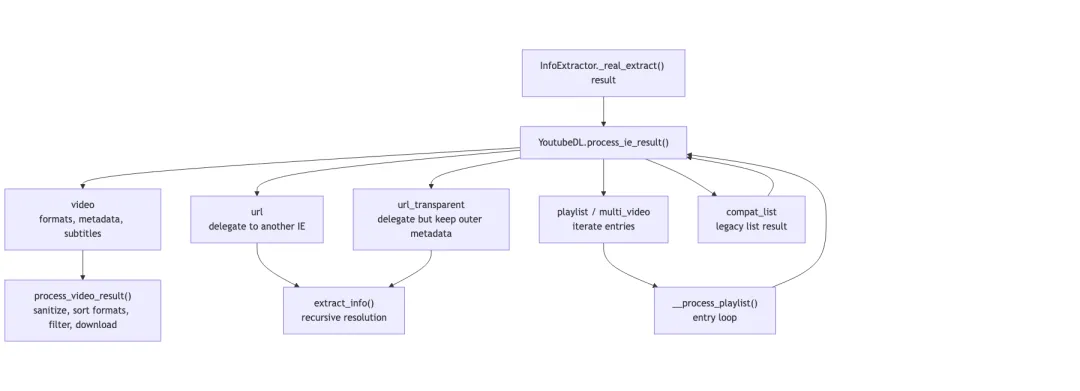
__extract_info() 拿到 extractor 结果后,会补上 webpage_url、original_url、extractor、extractor_key 等默认字段,然后交给 process_ie_result()。
process_ie_result() 的分发规则是整条链路的核心之一:
- •
_type = video:进入process_video_result()。 - •
_type = url:递归调用extract_info(),让另一个 extractor 处理。 - •
_type = url_transparent:先抽内层 URL,再把外层 metadata 合并进去。 - •
_type = playlist/multi_video:遍历 entries。 - •
compat_list:兼容旧式列表结果。
这个机制让 extractor 可以保持小边界。比如通用网页里发现 YouTube embed,它不必自己解析 YouTube,只要返回一个 url_result,后续交给 YouTube extractor 即可。复杂性被递归结果类型吸收,而不是塞进某个万能 extractor。
Format 选择是下载前最关键的决策
process_video_result() 是单视频结果的清洗和决策中心。它会校验 id,清洗字段,处理字幕,读取 formats,过滤 DRM 和 malformed formats,规范化 URL、分辨率、dynamic range、headers,再排序并保证 format_id 唯一。
这里有一个很实际的安全细节:它会移除 info_dict['http_headers'] 里的 Cookie,避免用户通过 --load-info-json 复用旧 infojson 时,把 Cookie 带到错误域名。
从用户视角看,“为什么这个格式被选中”“为什么音视频要分开下载”“为什么字幕没下来”像是下载器问题;从源码看,这些判断大多发生在 process_video_result() 和 format selector 附近。下载器只是执行最终选择。
Downloader 选择由 protocol 驱动
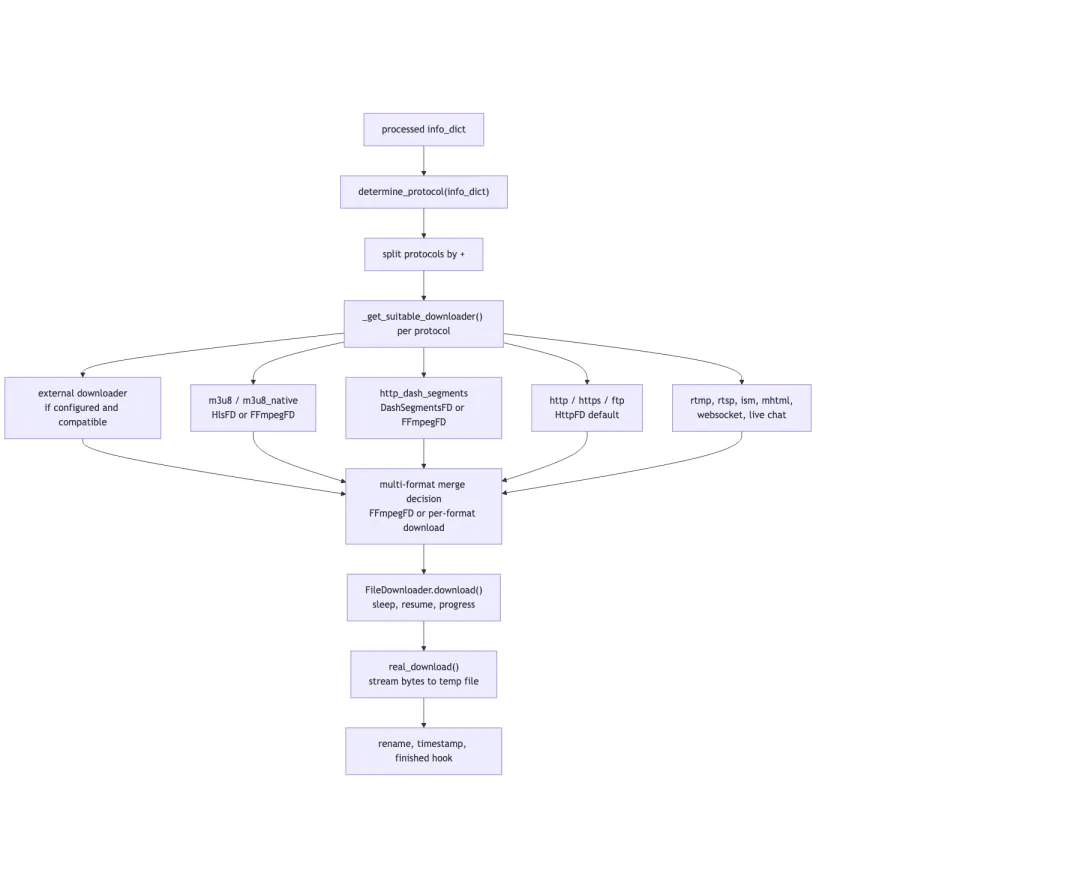
下载器选择入口是 get_suitable_downloader(info_dict, params, ...)。它先通过 determine_protocol(info_dict) 得到 protocol,再把协议映射到具体 downloader。
典型映射包括:
- • 普通 HTTP 走
HttpFD。 - • HLS 可以走
HlsFD或FFmpegFD。 - • DASH segments 走
DashSegmentsFD。 - • 多协议合并场景可能直接交给
FFmpegFD。 - • 如果配置了 external downloader 且兼容,会优先使用外部下载器。
真正写字节的公共外壳在 FileDownloader.download()。它会处理文件已存在、sleep interval、字幕下载等通用逻辑,然后调用子类的 real_download()。
以 HttpFD.real_download() 为例,它要处理 Range、resume、HTTP 416、chunk size、临时文件、进度 hook、速度限制、重试和最终 rename。也就是说,“下载”这件事在源码里不是一个 requests.get(),而是一套围绕失败恢复和进度可观测性的执行循环。
后处理决定最终文件长什么样
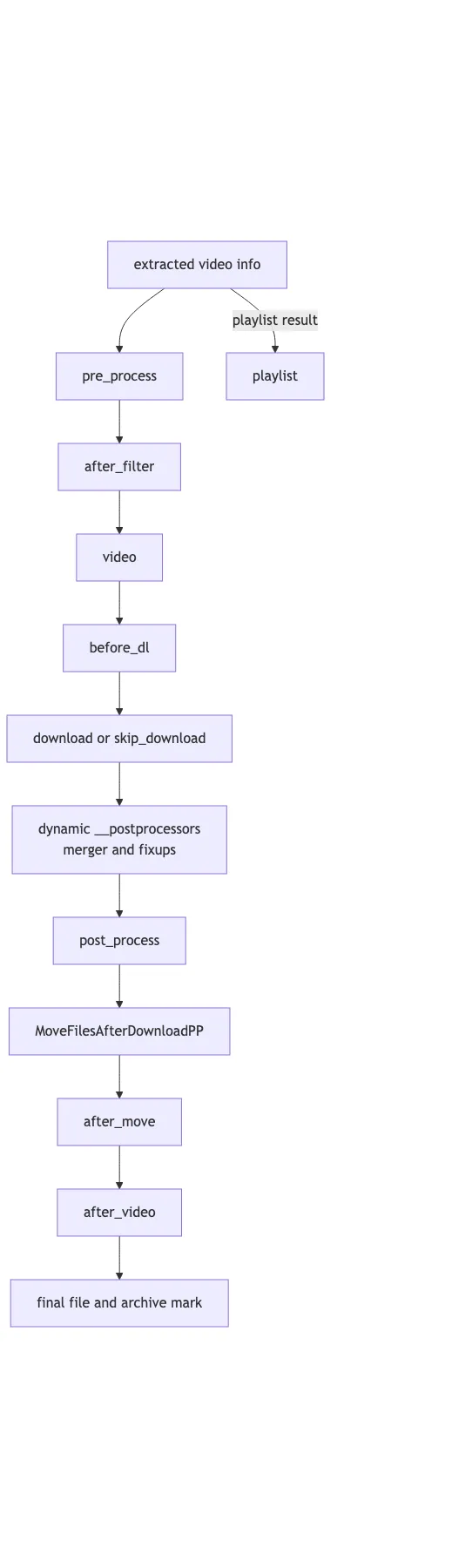
很多人把 postprocessor 理解成“下载完跑一下 ffmpeg”,但 yt-dlp 的后处理阶段更细。
POSTPROCESS_WHEN 定义了多个阶段:pre_process、after_filter、video、before_dl、post_process、after_move、after_video、playlist。YoutubeDL 通过 run_pp()、run_all_pps()、post_process() 在不同阶段执行 postprocessor 链。
多格式下载尤其能体现这个设计:如果 requested_formats 存在,可能要先分别下载音频和视频,再把 FFmpegMergerPP 塞进后处理链。后续还会根据 m4a、HLS、DASH、websocket fragment 等情况动态加入 fixup 类 postprocessor。
所以最终文件不是 downloader 单独产出的,而是 extractor、format selector、downloader 和 postprocessor 共同收敛出来的结果。
插件系统的价值
yt-dlp 的插件系统通过 yt_dlp_plugins namespace package 和 PluginSpec 工作。它不是随便扫描任意 Python 文件,而是有明确的插件类型、模块名、类名 suffix、主 registry 和插件 registry。
PluginFinder 会把 yt_dlp_plugins.<subpackage> 变成 namespace package,并支持 zip、egg、whl 等形式。load_plugins() 导入模块后,会筛出公开类,写入插件 registry,再 prepend 到主 lookup。
这和前面的 extractor 路由连在一起看才有意义:插件不是外挂脚本,而是能参与核心 registry 的一等扩展点。它可以改变 extractor 匹配顺序,也可以加入新的 postprocessor。
实用判断
读 yt-dlp 最有价值的不是背下每个站点 extractor,而是理解它如何管理“不稳定”:
站点页面和 API 不稳定,所以隔离在 InfoExtractor;媒体协议不一致,所以隔离在 downloader;最终文件生产有很多条件分支,所以隔离在 postprocessor;跨模块的递归、筛选、排序、失败策略,则放在 YoutubeDL 这个中枢里统一处理。
这套结构不花哨,但非常经得起维护压力。一个 URL 能走完完整链路,靠的不是某个巨大函数,而是一组清晰的中间协议:ydl_opts、extractor registry、IE result、info_dict、format dict、protocol、postprocessor stages。
如果只记一句话:yt-dlp 的工程价值在于,它把网页站点的不稳定性、媒体协议的不一致性和最终文件生产的复杂性拆开,再由 YoutubeDL 按统一协议串起来。这就是它能长期支撑大量站点和复杂下载场景的根本原因。
