 夜雨聆风
夜雨聆风刚好今天周末,我们花点时间来聊聊从模块化单体、API/Worker 运行角色、未来微服务边界,到转发实例、共享池、租户独享池、channel 调度、负载均衡和健康监测。
设计之初,主要是下面这2个问题.
第一个问题:后端服务要不要一开始就拆微服务?
第二个问题:LLM 上游不稳定,渠道要怎么做冗余、负载均衡和故障隔离?
这两个问题都和高可用有关,但不是同一层问题。
后端 API 和 Worker 解决的是平台业务复杂度:用户、租户、订单、财务、AI 计费、对账、审计,这些能力怎么在一个可交付的系统里协作。
LLM 渠道层解决的是上游执行复杂度:同一个模型背后可能有多个上游、多个区域、多个转发实例、共享池、租户独享池,平台要怎么选路、限流、降级和恢复。
所以我们当前的架构判断是:
不想单独纠结讲“单体好还是微服务好”,那句PHP是最好的语言的战争还历历在目。
摆一个更实际的问题,一切从需求出发:
在 AI Token 聚合平台这个阶段,哪些边界应该先做成代码边界和运行角色,哪些边界应该等组织和业务稳定后再拆成微服务。
先把两类高可用分开
如果把“平台业务高可用”和“模型渠道高可用”混成一个问题,后面一定会设计混乱。
平台业务高可用关注的是:
API 能不能稳定承接同步请求。 预算、钱包、额度、API Key spend limit 能不能在高并发下守住。 Worker 能不能处理异步账单、健康检查、对账、通知、补偿。 模块之间有没有清晰契约,未来是否能拆。
模型渠道高可用关注的是:
同一个公开模型能不能配置多个 channel。 同一个上游路线能不能部署到多个转发实例。 普通用户、平台高级用户、OEM 租户、独享客户能不能走不同池子。 路由时能不能按健康分、实时负载、权重和策略选择。 一个转发实例不可用时,系统是按策略回退,还是明确失败。
这两类问题不能互相替代。
后端拆成微服务,解决不了上游模型区域故障、账号限流、转发实例拥塞。
LLM 渠道做了冗余,也解决不了平台内部账本、租户、订单、对账边界混乱。
平台业务边界和模型执行边界必须分层设计。
为什么当前没有一上来拆微服务
我们早期确实评估过微服务形态:用户服务、订单服务、财务服务、租户服务、AI 服务、通知服务、工单服务等,每个域都可以拆成独立进程。
但从工程现实看,当前阶段不适合这么做。
微服务不是“把代码拆小”。
我一直认为,微服务真正解决的是企业内部组织架构边界问题,而不仅仅是代码边界:
不同团队可以独立交付。 不同业务域可以独立发布。 不同服务可以独立扩缩容。 某个域故障时有清晰责任边界。 数据生命周期和一致性策略可以按业务域独立演进。
如果组织还没有形成这些边界,微服务会先带来成本,而不是收益。
更准确地说:
服务边界不是照抄大厂或者脑补出来的,是内部组织协作和交付节奏长出来的。
当前我们更需要的是一个边界清晰的模块化单体,而不是一组边界还不稳定的微服务。
当前不是“大单体”,而是模块化单体
不拆微服务,不等于把所有代码堆在一个目录里。
我们现在的后端结构是模块化单体:一个应用进程内包含多个业务模块,但每个模块有自己的层次和契约。
一个典型模块内部是这样的:
text
module
-> handler 只做 HTTP binding、参数校验、响应格式
-> service 编排业务流程
-> repository 通过接口访问数据
-> model 承载领域状态和领域方法模块之间不应该互相穿透。
比如订单模块需要用到用户能力,它应该依赖用户模块暴露出来的 service interface,而不是直接去访问用户模块内部 repository。
repository 也不是随便查表。多租户场景里,租户上下文必须贯穿到数据访问层。一个用户 ID 本身不够安全,很多查询必须同时受 tenant_id 和资源归属约束。
这套结构带来的收益不是“目录好看”,而是未来可拆。
所以当前的核心不是“单体还是微服务”,而是:
我们先把业务边界做成代码边界、接口边界、事务边界和运行角色边界。等组织边界出现,再把其中一部分提升为服务边界。
API 和 Worker 是运行角色,不是两个业务服务
当前后端只有一个应用入口,但通过运行角色启动成 API 或 Worker。
text
同一套代码
APP_ROLE=api -> 启动 HTTP API
APP_ROLE=worker -> 启动异步任务和定时任务这个设计很关键。
API 进程负责同步请求:
Worker 进程负责异步和后台任务:
API/Worker 分成两个进程,是为了隔离同步请求和异步任务。
但它们现在还不是两个微服务。
原因很简单:Worker 不是一个独立业务域,它是多个业务域的异步执行面。
订单有 Worker 任务,财务有 Worker 任务,通知有 Worker 任务,AI 渠道也有 Worker 任务。如果把 Worker 简单当成“另一个服务”,就容易出现一个坏味道:同步路径写一套业务规则,异步路径再写一套业务规则。
正确做法是:
API 和 Worker 共享同一套领域模型、repository 契约、配置和基础设施,只是在运行时承担不同职责。
这就是当前 API/Worker 设计的价值。
Worker 的工程价值,不是“异步”两个字
很多系统说自己有 Worker,但只是把一些逻辑挪到后台。
真正有价值的 Worker,需要回答三个问题:
哪些事情不应该放在 API 请求线程? 任务失败后怎么重试? 多个 Worker 实例同时运行时,怎么保证同一件事不会重复执行?
我们现在的 Worker 框架做了几件基础能力。
第一,支持长任务和定时任务。
长任务用于持续消费队列,例如异步计费 outbox。定时任务用于健康检查、对账扫描、月计数 flush、订单超时处理等。
第二,定时任务支持 singleton。
多个 Worker 实例可以水平部署,但某些任务同一时间只能有一个实例执行。比如渠道健康检查、实例存活检查、异步对账扫描,如果多个 Worker 同时跑,可能会重复降级、重复恢复、重复写审计。
所以 Worker 的 singleton cron 会用 Redis lease 做互斥:拿到锁的实例执行,没拿到锁的实例跳过;执行期间续约,退出时释放。
第三,API 和 Worker 之间通过队列抽象解耦。
当前通知链路使用 Redis List 做跨进程桥接,但业务代码依赖的是 Publisher/Consumer 抽象,而不是直接依赖某个具体队列实现。
text
API 侧
-> Publish(event)
-> Redis Queue
Worker 侧
-> Subscribe(topic)
-> claim / handle / retry这意味着未来切换到 Kafka 时,不需要重写通知消费者业务逻辑,只需要替换 Publisher/Consumer 的基础设施实现。
第四,异步计费使用 durable outbox。
高并发 AI 请求里,钱包、额度、API Key spend、月阶梯计数都可能成为热行。如果请求线程在上游返回后同步锁这些表,单用户高 QPS 很容易把延迟打爆。
异步计费的方向是:
text
API 请求线程
-> Redis 原子预算 reserve / pending
-> 写 durable billing event
-> 返回响应
Worker
-> claim pending event
-> 钱包扣款
-> 额度扣减
-> usage log
-> charge line
-> API Key spend
-> 成功标记 posted
-> 失败进入 retry 或 reconcile_required这里有两个重点。
一个是 outbox 必须 durable。否则 API 返回成功后,后台没有可靠事件,账本就丢了。
另一个是 Worker 必须幂等。钱包扣款有业务引用,额度扣减有 marker,outbox 有状态机,重复 claim 不应该造成重复扣费。
这才是 Worker 的价值:它不是把慢逻辑“丢到后台”,而是把慢任务、重试任务、补偿任务做成可证明的异步边界。
为未来拆微服务做了哪些铺垫
当前不拆微服务,不代表未来不能拆。
我们真正要避免的是两种极端:
现在就拆,导致每个需求都跨服务联调。 完全不留边界,未来想拆时只能重写。
当前已经做的铺垫可以用一张表概括:
未来如果要拆,不应该按 controller 文件夹拆,也不应该按数据库表名拆。
合理的拆分顺序更像这样:
先拆运行角色:API / Worker。 再拆异步执行面:通知、对账、健康检查、异步账单。 再拆稳定业务域:用户、财务、AI 账本、渠道管理。 最后再考虑数据物理拆分。
为什么数据拆分放最后?
因为数据一旦物理拆开,事务语义、查询路径、对账方式都会变化。如果业务边界还没稳定,过早拆库会让每一次产品调整都变成数据一致性问题。
什么时候才应该真正转微服务
微服务不是信仰题,而是判断题。
可以用这张 Go / No-Go 表来判断:
当这些条件没有出现时,拆微服务只是在提前支付复杂度。
当这些条件出现时,模块化单体里已经存在的接口、outbox、任务状态机、审计和可观测字段,就会成为拆分基础。
LLM 渠道高可用,不能靠后端微服务解决
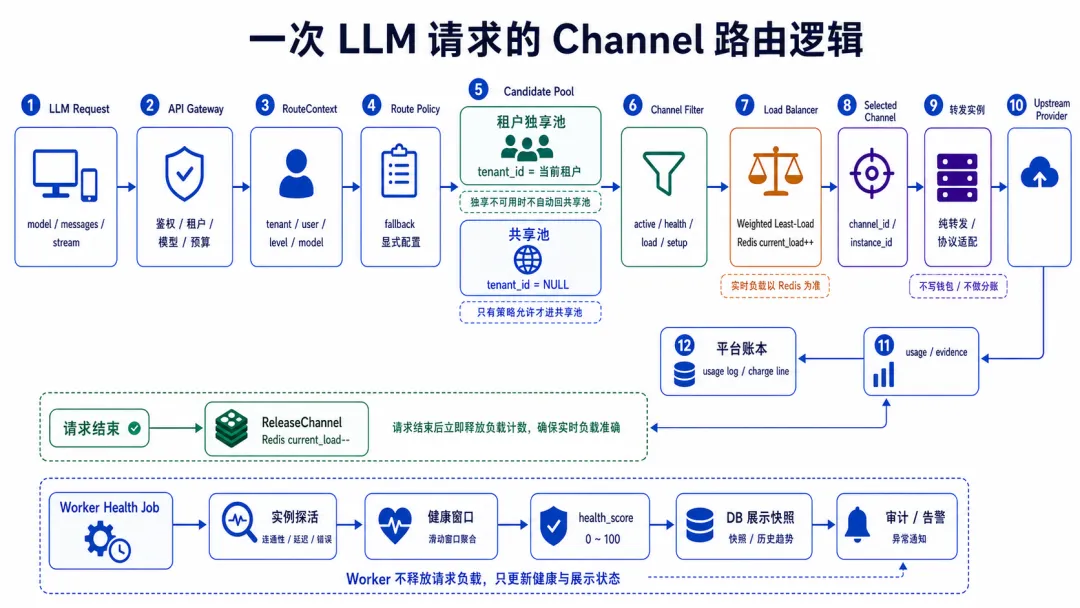
讲完后端 API/Worker,再看 LLM 渠道。
LLM 渠道的不稳定来自执行层:
某个上游账号被限流。 某个区域网络波动。 某个转发实例健康异常。 某个模型路线临时不可用。 某个共享池被大客户打满。 某个 OEM 独享池配置还没完成。
这些问题不是把 API 拆成用户服务、订单服务、AI 服务就能解决的。
正确的边界是:
text
API
-> 只做平台门禁、预算、路由选择和账本收口
channel
-> 平台侧流量调度和成本归因单元
转发实例
-> 上游协议转发和执行入口
Worker
-> 健康检查、实例探活、路由配置对账、异步账单和补偿这四个对象的职责不能混。
API 不能变成上游连环重试机器。
转发实例不能变成平台账本系统。
Worker 不能阻塞同步请求。
channel 不能只是 provider key 的别名。
转发实例只做转发
转发实例是一个执行入口。
它可以部署在不同区域,也可以按租户、用户等级、业务场景绑定到不同池子。它要做的是协议转发、上游适配、实例内部 timeout、实例内部 retry、实例内部 provider fallback。
转发实例应该做:
转发实例不应该做:
转发实例的关键字段也体现了这个边界:
这里的核心原则是:
转发实例越纯,平台越容易替换上游适配层。
如果把钱包、折扣、租户、分账都写进转发实例,未来换转发实现时,等于要重写平台账本。
channel 才是平台的流量调度单元
channel 不是一个简单的 provider key。
channel 表达的是:
text
某个公开模型
在某个租户范围内
通过某个转发实例
使用某个转发路由别名
以某个权重、并发上限和健康状态
参与平台调度和计费归因也就是说,转发实例是执行入口,channel 是平台侧的调度、隔离和归因单元。
关键字段包括:
为什么 channel 要承载成本和归因?
因为同一个公开模型可能背后有多个上游路线,成本不同、币种不同、稳定性不同、可用能力不同。
如果只在转发实例里表达这些差异,平台侧就不知道本次请求到底走了哪条商业路径,也无法准确计算毛利、对账和渠道质量。
所以平台账本里必须记录本次选择的 channel、转发实例、路由策略、上游模型名和成本快照。
共享池、租户独享池和混合池
企业级平台不能只有一个“默认上游”。
不同客户会有不同诉求:
普通用户希望成本低、可用即可。 高级用户希望走更稳定的共享高质量池。 OEM 租户希望默认走自己的实例池。 大客户希望独享实例和专属 channel。 某个用户或等级需要灰度某条新上游路线。
当前可以用两层配置表达:
text
tenant_llm_bindings
tenant_id
instance_id
binding_type = dedicated / shared_pool / hybrid
priority
status
channel
tenant_id = NULL -> 平台共享 channel
tenant_id = 当前租户 -> 租户专属 channel几类典型场景如下:
这里最重要的是最后一列。
共享池不能默认兜底一切。
如果一个 OEM 独享客户买的是独享能力,独享池故障时,系统不应该偷偷把请求打到共享池。短期看成功率提高了,长期看成本、SLA、合规边界都会被破坏。
是否允许共享兜底,必须由策略显式表达。
路由不是 if/else,而是 RouteContext + Route Policy
如果只靠代码里写 if/else,很快就会失控。
比如:
某租户默认走实例 A。 某租户下的高级客户走实例 B。 某个用户灰度新上游 channel C。 图片请求走专门的多模态 channel。 chat 请求按共享池调度。 命中特定策略但目标不可用时直接失败。
这些规则不能写死在请求代码里。
我们把运行时路由上下文抽象成 RouteContext:
text
tenant_id
user_id
level_scope = platform_user_level / oem_customer_level / none
user_level_id
public_model_name
request_typeRoute Policy 按这些维度匹配:
策略目标有两种:
fallback 也必须显式配置:
这个设计解决的是“灵活”背后的治理问题。
灵活不是随便兜底。
灵活是每个兜底都有策略记录、审计记录和可解释的目标范围。
默认路由:先租户绑定池,再共享池
没有命中 Route Policy 时,系统走默认路由。
默认路由不是简单随机挑一个上游,而是先构建候选池:
text
SelectChannel(tenant, public_model)
-> 查租户 active bindings
-> 按 binding priority 构建实例候选
-> 查实例下匹配 public_model 的 channels
-> 读取 Redis current_load
-> 过滤状态、健康、并发、pending setup
-> 若租户候选为空,再进入 shared pool
-> weighted least-load 选择 channel
-> Redis current_load++
-> 返回 SelectedChannel
-> 请求结束 ReleaseChannel候选过滤条件如下:
这里要注意:DB 里的 current_load 只是展示副本,路由时以 Redis 为准。
原因很直接。
高并发路由需要毫秒级的实时计数,DB 字段不适合承担这个职责。DB current_load 更适合作为 Admin 面板展示和冷备快照,由 Worker 周期同步。
负载均衡:weighted least-load,不是简单轮询
渠道负载均衡不能只做轮询。
因为不同 channel 的质量、成本、限额和并发能力不一样。
一个 channel 权重高,表示它更适合承接流量。但如果它当前已经很忙,就应该降低它在本轮选择里的有效权重。
当前算法是 weighted least-load:
text
availableSlots = max_concurrency - current_load
effective_weight = weight * availableSlots / max_concurrency语义很清楚:
负载为 0 时,拿满配置权重。 负载越高,有效权重越低。 达到并发上限,直接从候选池剔除。 如果策略目标带 target_weight,会作为权重乘数叠加进去。
Redis 负载 key 是:
text
ai:channel:load:{channelID}路由时会批量 MGET 候选 channel 的负载,选中后 INCR。
这里还有一个并发保护:
text
读到 current_load = 99
max_concurrency = 100
两个请求同时选中该 channel
两个请求都准备 INCR如果没有 INCR 后检查,就可能突破上限。
所以实现里会在 INCR 后再看新值:
如果没有超过 max_concurrency,继续执行。 如果超过,立即 DECR,移除该候选,重选一次。 如果仍然没有可用候选,返回无可用 channel。
请求结束时必须 ReleaseChannel,把 Redis 计数减回去。
Release 使用不低于 0 的 Lua 脚本,避免重复释放导致负载变成负数。同时 key 有 TTL,避免进程崩溃后计数永久残留。
健康监测:Worker 管状态,不塞进请求线程
渠道健康不能靠人工盯。
当前有两类健康治理。
第一类是 channel / instance 的运行窗口健康分。
当前执行器会把平台选中的成功调用写入 Redis 分钟级 bucket。窗口读取器本身按 ok / total 聚合,后续如果要把更多失败样本纳入同一窗口,不需要改健康任务的状态机。
Worker 每 60 秒读取最近窗口,计算 health score,并把结果写回 channel 和实例记录。
简化后的模型是:
text
success_rate = ok / total
health_score = success_rate * 100状态机是:
第二类是转发实例存活检查。
Worker 每 60 秒探测转发实例的 liveliness endpoint。连续失败达到阈值后,实例进入降级;连续成功达到阈值后,降级实例恢复。
这类检查解决的是实例入口本身不可达的问题,和 channel 的业务流量窗口不同。
所以这里有两个层次:
两者都由 Worker 维护,而不是塞进 API 请求线程。
原因是健康检查本质上是周期性治理,不应该让用户请求承担扫描、降级、恢复、审计和告警的成本。
同模型多上游怎么配置
同一个公开模型,可以对应多个 channel。
例如:
对客户来说,请求的都是 model-a。
对平台来说,每个 channel 有自己的:
租户范围 权重 并发上限 健康分 成本价 上游模型名 转发实例 路由策略归因
这才是真正可运营的同模型多上游。
这里还有一个重要取舍:
平台层不会在一次请求失败后跨 channel 连环重试。
平台先选择一个 channel,本次请求的 usage、成本、健康、证据都归属这个 channel。
provider 级 retry 和 fallback 应该属于转发执行层的内部路线能力。否则平台层 A channel 已经产生上游成本,再切到 B channel 成功,账本和证据归属会非常难解释。
简单说:
text
平台层:
选择一个 channel
记录本次请求归因
完成账本收口
转发执行层:
在选定路线内部处理 provider retry / fallback这个边界看起来保守,但对账、毛利和争议处理会稳定很多。
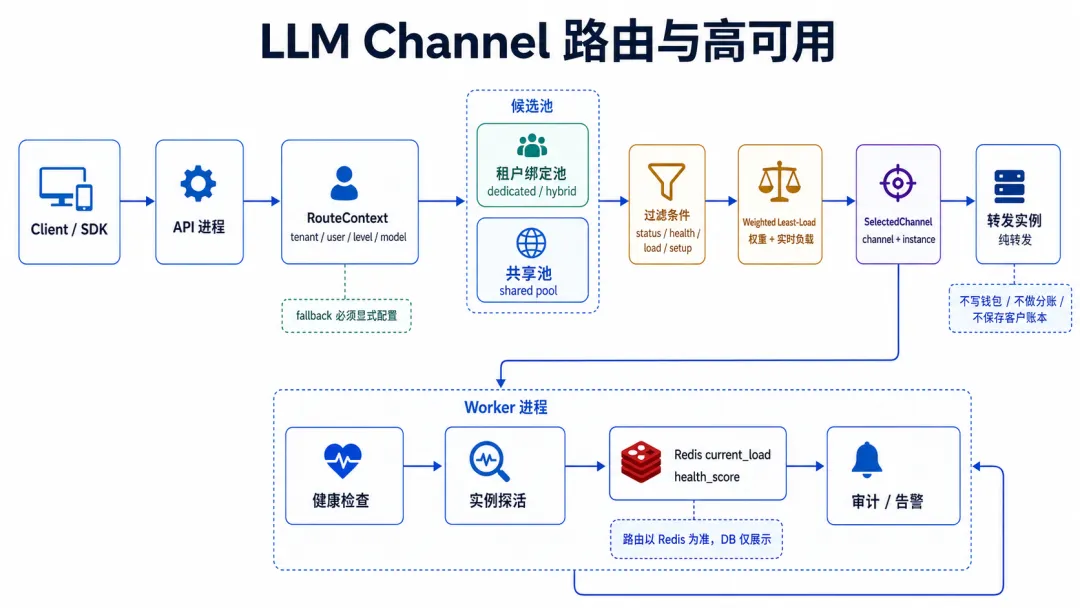
API / Worker 和渠道架构如何配合
把两条主线合起来,可以得到这张架构图:
text
Client / SDK
|
v
API 进程
鉴权 / 租户 / 预算 / 模型门禁
构建 RouteContext
调用 Route Policy + RoutingService
|
v
SelectedChannel
channel_id
instance_id
route_policy_id
cost snapshot
|
v
转发实例
执行上游协议转发
返回 response / usage / evidence
|
v
API 收口
usage log / charge line / budget commit
|
v
Worker
健康检查 / 实例探活 / 异步账单 / 对账 / 补偿这张图里,每个对象都有自己的边界:
真正稳定的架构,不是每层都能做所有事,而是每层只做自己该做的事。
常见错误设计
第一种错误:业务还没稳定就拆微服务。
结果是服务边界天天变,跨服务联调、数据一致性、配置发布先爆炸。
第二种错误:把 Worker 当成另一个服务随便写业务逻辑。
结果是同步路径和异步路径各写一套规则。等需要补偿和对账时,没人能证明两套规则一致。
第三种错误:把转发实例做成业务系统。
一旦转发实例里写了钱包、租户、折扣、OEM 分账,平台账本和执行层就耦死了。未来想换上游适配层,成本会非常高。
第四种错误:channel 只是 provider key 的别名。
如果 channel 不能表达租户范围、权重、并发、健康、成本和归因,它就不是调度单元,只是配置项。
第五种错误:独享池不可用时自动回共享池。
短期成功率变高,长期破坏成本、SLA 和合规边界。能不能回共享池,必须由策略显式决定。
第六种错误:用 DB current_load 做实时路由。
高并发路由需要实时原子计数。DB 字段适合展示,不适合承担毫秒级调度。
第七种错误:平台层 A 主 B 备跨 channel 重试。
一旦 A 已经产生上游成本,再切到 B 成功,账本、usage、provider evidence 会变得很难对齐。
架构检查清单
如果你也在设计 AI Token 聚合平台,可以用这张清单自检。
API / Worker:
是否有统一应用入口,并通过运行角色区分 API 和 Worker。 API 是否只承接同步请求和必要强一致操作。 Worker 是否承接定时、异步、补偿、对账、健康检查。 模块之间是否通过 service interface 调用。 是否避免跨模块直接访问 repository。 Worker 任务是否有业务唯一键和幂等保护。 队列和事件是否有抽象接口,未来可替换基础设施。 哪些模块未来可以拆服务,边界是否已经能描述。
微服务拆分:
是否已经有独立团队负责独立业务域。 是否需要独立部署、独立扩缩容。 是否能接受事件最终一致性。 是否已经有服务治理、链路追踪、告警和灰度能力。 数据归属是否清楚。 失败补偿和幂等机制是否成熟。
LLM 渠道:
转发实例是否保持纯执行层职责。 channel 是否承担平台调度和归因。 同一个 public model 是否可以配置多个 channel。 channel 是否可以绑定不同转发实例和区域。 是否支持共享池、租户独享池和混合池。 是否有 Route Policy 表达租户、用户、等级、模型、请求类型。 fallback_policy 是否显式控制共享池兜底。 负载均衡是否使用实时 current_load。 health_score 是否由 Worker 根据运行窗口更新。 Admin 手动禁用是否不会被自动恢复覆盖。
结尾
这篇文章的核心判断是:
AI Token 聚合平台当前更适合用 API + Worker 的模块化单体承载业务复杂度,同时把 LLM 渠道高可用独立建模为转发实例、channel、共享池、独享池、Route Policy、负载和健康治理。
微服务不是架构起点。
微服务是组织、业务和基础设施发展到某个阶段后的结果。
在那之前,更重要的是把边界先做对:代码边界、运行角色边界、异步边界、账本边界、渠道边界。
