 夜雨聆风
夜雨聆风上一篇我们聊了一个问题:
大模型不只有 ChatGPT、Claude、DeepSeek 官网这种“网络模型”,也有可以跑在自己电脑里的“本地模型”。
这篇就不讲太多概念了。
我们直接做一件事:
把一个大模型,真正部署到自己电脑上。
不过在开始之前,先说一句大实话:
本地部署大模型,不是让你一上来就跑 DeepSeek-V3、Kimi K2、GPT-OSS 120B 这种大家伙。
这些模型确实很强,但对普通电脑来说,基本属于:
看得见,跑不动。
普通人玩本地模型,重点不是追求“最强”,而是先解决三个问题:
我的电脑能跑什么? 我该下载哪个模型? 怎么把它跑起来?
这篇就按这个顺序来。

一、先判断:你的电脑到底能跑什么模型?
很多人一听“本地大模型”,第一反应就是:
“我电脑是不是不行?”
“是不是必须 4090?”
“是不是要 64G 内存起步?”
其实没那么绝对。
本地模型能不能跑,主要看几个东西:
显存、内存、模型大小、量化版本。
简单理解:
显存越大,能跑的模型越大。
内存越大,兜底能力越强。
模型越大,效果通常越好,但速度越慢。
量化越低,模型越小,但质量也会有损失。
比如同样是一个 7B 模型,原始精度可能很大,但用 Q4 量化后,体积会小很多,对普通电脑更友好。
所以这一步不要靠猜。
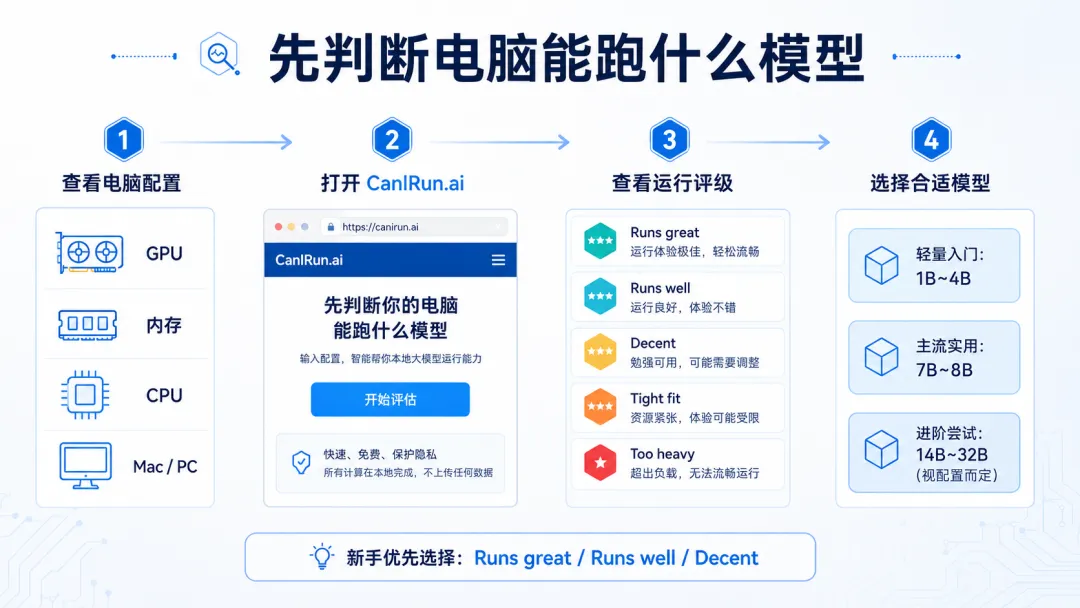
这里推荐一个网站:
CanIRun.ai
你打开之后,它会根据你的电脑配置,估算你大概能跑哪些模型。
它的结果会把模型分成几个等级,比如:
Runs great:跑得很舒服
Runs well:可以正常用
Decent:能用,但可能需要调低要求
Tight fit:勉强能跑,体验可能一般
Too heavy:太重了,不建议硬上
我的建议很简单:
新手只看前三档。
也就是:
Runs great / Runs well / Decent
如果一个模型已经被标成 Tight fit,那就别硬上了。
因为能跑和好用,是两回事。
二、普通人怎么选模型?
如果你不知道选什么,先按这个思路来。
1. 没有独立显卡,只是普通办公电脑
优先选小模型:
1B 3B 4B
这类模型不要指望它写复杂方案,但做简单问答、改写、总结、翻译、学习体验,是够用的。
比如可以先试:
Llama 3.2 3B Qwen 3 4B Gemma 小尺寸模型
2. 有 8GB 显存
比如 RTX 4060、3070、部分游戏本显卡。
可以尝试:
7B 8B 部分 14B 的低量化版本
这个档位是普通玩家比较舒服的入门区。
中文聊天、简单代码、文档总结类任务,都可以试试。
3. 有 12GB 到 16GB 显存
比如 3060 12G、4070Ti、4080 这类机器。
可以考虑:
8B 14B 20B 左右的量化模型 部分 32B 的低量化版本
这个档位已经比较能玩了。
写代码、写文章、做知识库问答、分析文档,都可以尝试。
4. Mac 用户怎么看?
如果你是 M 系列芯片,比如 M1、M2、M3、M4,它和普通 PC 不太一样。
Mac 是统一内存,不是独立显存。
所以 Mac 不是只看“显卡显存”,而是看总内存。
16G、32G、64G 的体验差距会很明显。
Mac 用户也可以直接用 CanIRun.ai 看结果,别自己猜。
三、部署方式一:Ollama,适合喜欢简单命令的人
如果你想用最简单的方式跑模型,我建议先用 Ollama。
你可以把 Ollama 理解成“大模型版 Docker”。
安装好之后,一条命令就能下载并运行模型。
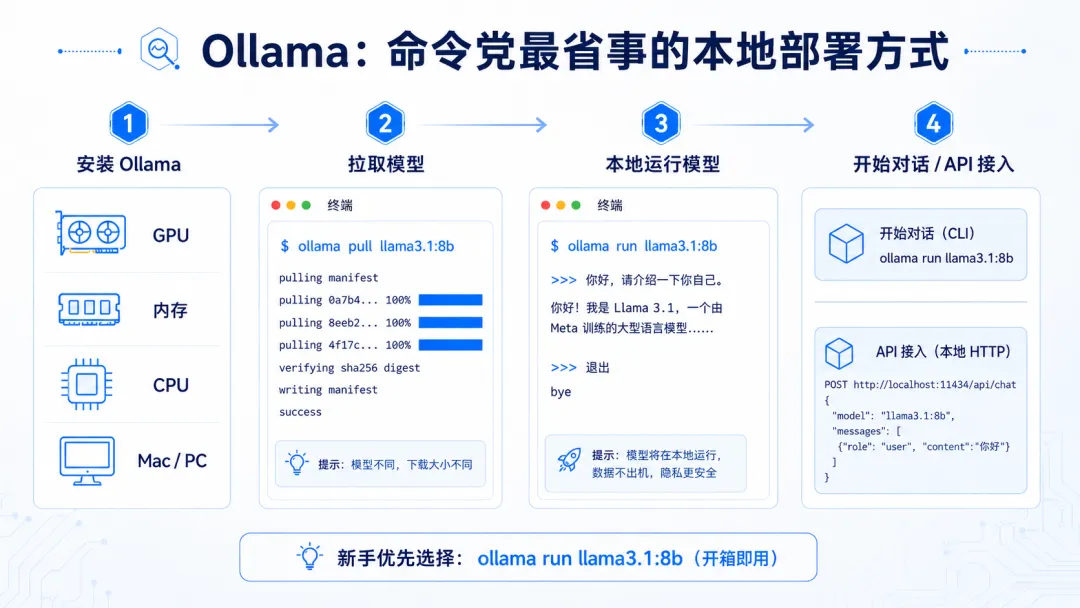
第一步:安装 Ollama
Mac 和 Linux 可以用命令安装:
curl -fsSL https://ollama.com/install.sh | sh
Windows 用户可以去 Ollama 官网下载安装包。
安装完成后,打开终端,输入:
ollama -v
如果能看到版本号,说明安装成功。
第二步:运行一个模型
比如我们先跑一个小一点的模型:
ollama run llama3.2:3b
或者跑 Qwen:
ollama run qwen3:4b
如果你的显卡和内存更好,也可以试试:
ollama run qwen3:8b
第一次运行会自动下载模型。
下载完成后,终端里就会出现一个对话框,你可以直接输入问题。
比如:
请用通俗的话解释一下什么是本地大模型
如果它正常回复,说明你已经成功在本地跑起来了。
注意,这一步之后,你的电脑即使断网,也可以继续和这个模型聊天。
前提是模型已经下载好了。
四、部署方式二:LM Studio,适合不想敲命令的人
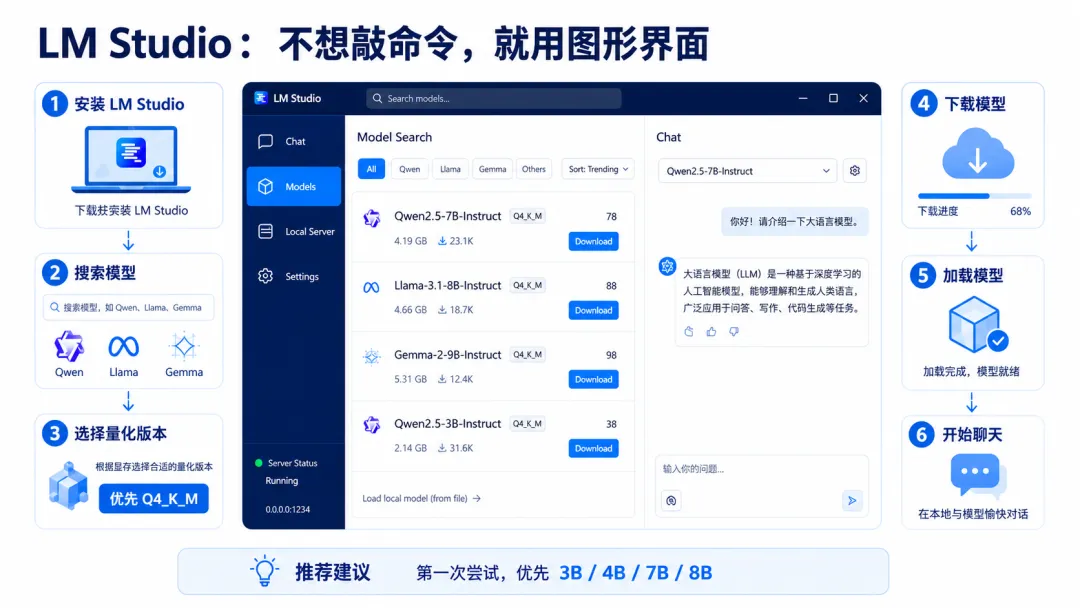
如果你不喜欢终端,也可以用 LM Studio。
它更像一个本地版 ChatGPT 客户端。
安装之后,可以直接在界面里搜索模型、下载模型、加载模型,然后聊天。
大致流程是:
安装 LM Studio 搜索模型,比如 Qwen、Llama、Gemma 选择合适的量化版本 下载模型 加载模型 开始聊天
新手重点看模型后面的大小。
不要看到一个模型名字很厉害就直接下。
比如 70B、120B 这种,对普通电脑来说大概率跑不动。
如果你是第一次尝试,优先选择:
3B、4B、7B、8B
量化版本建议先选:
Q4_K_M
这个版本通常是体积和效果比较平衡的选择。
五、本地模型跑起来之后,能干什么?
本地模型跑起来以后,可以做很多事。
1. 处理私密内容
像工作笔记、会议纪要、内部文档,不想上传到网络模型,就可以丢给本地模型处理。
当然,前提是你自己电脑配置够,模型能力也够。
2. 离线使用
断网的时候,本地模型仍然可以工作。
比如出差、高铁、网络不好,依然可以让它帮你写东西、改文案、做总结。
3. 接入自己的工具
Ollama 默认会在本地启动一个接口。
很多 AI 工具都支持接入 Ollama。
默认地址一般是:
http://localhost:11434
这就意味着,你不只是能在终端里聊天,还能把本地模型接到别的软件里。
这才是本地模型真正有意思的地方。
六、几个新手最容易踩的坑
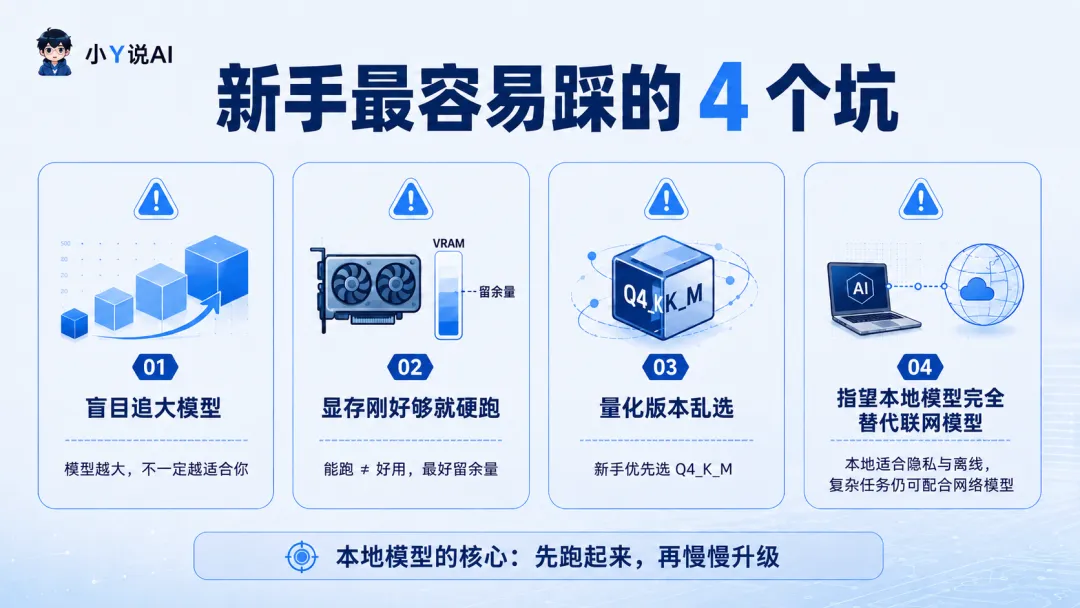
坑一:模型越大越好
不是。
模型越大,确实可能更聪明,但也更吃机器。
如果你的电脑跑一个模型已经很吃力,那它回复会很慢,甚至卡死。
新手先选能流畅跑的。
流畅,比参数大更重要。
坑二:显存刚好够就硬跑
也不建议。
比如一个模型需要 8GB 显存,你的显卡刚好 8GB。
理论上能跑,但实际体验可能一般。
因为模型运行时不只占模型文件本身,还会占上下文缓存、运行时开销。
所以最好留一点余量。
坑三:量化版本乱选
量化版本不是越小越好。
太小的量化版本虽然更省资源,但回答质量可能会下降。
新手不知道怎么选,就先记一个:
Q4_K_M
它通常比较适合作为第一次尝试。
坑四:本地模型可以完全替代网络模型
目前还不能完全替代。
本地模型的优势是:
隐私好 可离线 可控 不用每次请求云端
但网络模型的优势也很明显:
能力更强 上下文更长 多模态更完整 深度推理更稳 可以联网搜索
所以我的建议不是二选一。
而是:
普通问题、本地资料、隐私内容,用本地模型。
复杂推理、联网搜索、重要方案,用网络模型。
这样更现实。
七、总结一下
如果你也想尝试本地模型,不要一上来就折腾一堆复杂教程。
按这个顺序来就行:
第一步,打开 CanIRun.ai,看你的电脑能跑什么。
第二步,优先选择 Runs great / Runs well / Decent 的模型。
第三步,新手从 3B、4B、7B、8B 开始。
第四步,命令党用 Ollama,普通用户用 LM Studio。
第五步,先跑起来,再慢慢研究知识库、插件、Agent 接入。
本地模型最重要的不是“跑最强模型”。
而是让你第一次意识到:
原来 AI 不一定非要在云端。
它也可以在你自己的电脑里。
