 夜雨聆风
夜雨聆风AI 自动化 vs 传统自动化:移动端 UI 测试的两条路
什么时候该用 AI,什么时候该用传统方案,以及如何把两者结合起来。
一、两种自动化,解决同一个问题
移动端 UI 自动化测试的目标从未变过:让机器代替人去操作手机,验证功能是否正常。
但实现方式出现了技术分水岭。
传统方案的核心逻辑是:
定位元素 → 执行操作 → 校验属性
通过控件 ID、XPath、accessibilityId 找到目标元素,调用 click() / sendKeys() 执行操作,最后检查元素的 text、exists 等属性判断结果。
AI 方案的核心逻辑是:
截图 → 视觉推理 → 执行操作 → 截图 → 视觉断言
每一步操作先截屏,发送给多模态大模型"看",模型理解页面后输出操作指令(点击坐标、输入文本、滑动方向),执行后再截图确认。
两条路都能到达终点,但路径特性完全不同。
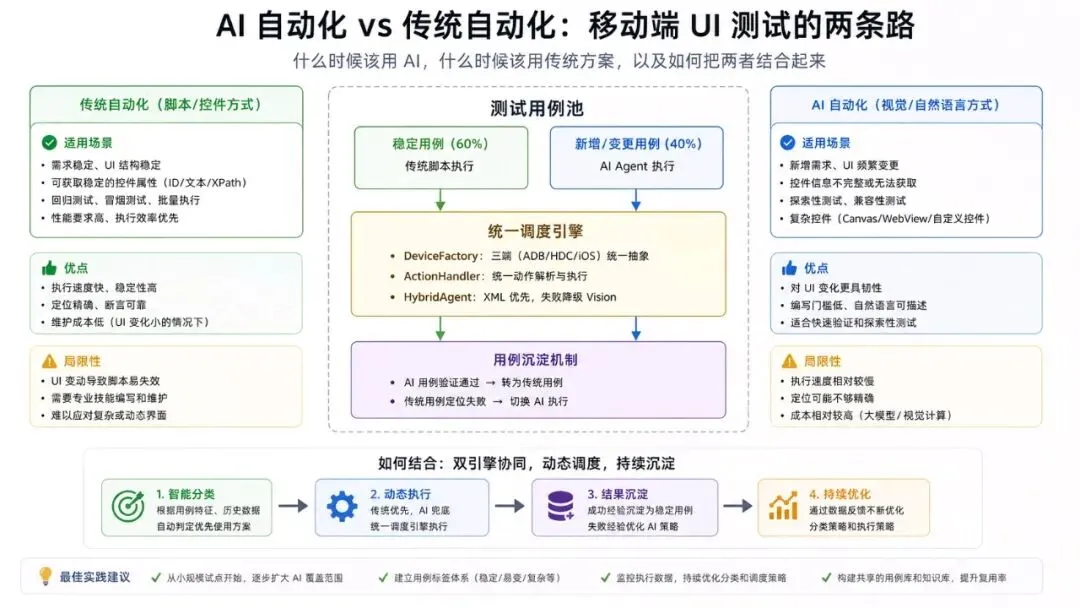
二、六维对比
2.1 元素定位:脆弱 vs 语义
传统自动化的命门在定位器。一条典型的定位语句:
driver.find_element(By.XPATH, '//android.widget.TextView[@resource-id="com.example:id/title"]')
这段代码绑定了控件类型、resource-id、层级路径三个维度。产品改了其中任何一个,用例就挂。实际项目中,一次中等规模的 UI 重构可以导致约 30%-50% 的用例定位失败(行业经验值)。
AI 方案根本不做元素定位。它截一张图,用自然语言告诉模型"点击屏幕上的登录按钮",模型输出坐标直接执行。只要按钮还在屏幕上、文案语义没大变,就能正常工作。
但 AI 不是万能药:
1. 速度慢 — 每次定位需要调用一次 VLM 推理,耗时约 2-5 秒(实测),传统只需约 50-100ms(行业常识) 2. 不确定性 — 同一张截图推理两次,坐标可能有 10-20px 偏差;遇到相似元素可能点错
AutoPilot 的两种 AI 路径
Vision Kernel:截图→多模态模型→坐标
screenshot = device_factory.get_screenshot(device_id)
response = model_client.request([
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{screenshot.base64_data}"}},
{"type": "text", "text": "点击登录按钮"}
])
# 输出: do(action="Tap", element=[523, 847]) ← 归一化坐标 (0-1000)
XML Kernel:UI 树→纯文本 LLM→元素索引
xml_content = dump_ui_tree(device_id) # uiautomator dump
elements = parse_xml(xml_content)
response = model_client.request(f"{task}\n\nUI元素列表:\n{elements_text}")
# 输出: do(action="Tap", element=[523, 847]) ← 基于元素信息
归一化坐标:模型使用 0-1000 空间,执行时根据实际分辨率换算,同一用例可在不同设备执行。
混合模式:XML 优先(代码注释标称快 10-20 倍),失败自动降级 Vision。
2.2 用例编写:代码 vs 自然语言
传统用例是一段代码:
deftest_login():
driver.find_element(By.ID, "com.example:id/username").send_keys("testuser")
driver.find_element(By.ID, "com.example:id/password").send_keys("123456")
driver.find_element(By.ID, "com.example:id/login_btn").click()
assert driver.find_element(By.ID, "com.example:id/welcome").text == "欢迎回来"
写一条复杂用例需要:找元素→写代码→调试→确认。一个功能模块 20 条用例,熟练工程师约需 1-2 天(经验值)。
AI 用例是一段自然语言:
步骤:
1. 启动应用
2. 在用户名输入框输入 "testuser"
3. 在密码输入框输入 "123456"
4. 点击「登录」按钮
断言:
1. 页面显示 "欢迎回来"
编写效率约提升 5-10 倍(经验值),无需编程知识。但代价是:AI 生成的用例质量不稳定,需要人工审核。
2.3 执行速度:毫秒 vs 秒
AutoPilot 实测
AI 比传统慢 5 倍。 一次完整回归(100 条用例,估算),传统方案约 30 分钟,AI(Vision)方案约 3 小时,混合模式约 1.5小时。
速度优化
AutoPilot 通过三层优化降低延迟:
1. 任务预处理器:系统指令(打开应用、返回桌面)直接执行,跳过 LLM 2. XML 优先:auto 模式优先使用 UI 树(快),失败才降级 Vision 3. 上下文压缩:历史消息中的截图被移除,只保留文本
2.4 维护成本:持续投入 vs 一次性的
传统自动化的维护成本是持续增长的:每版本迭代后,约 30%-50% 的用例需要修复定位器。每 100 条用例,每版本约需 5-10 人天维护。
AI 自动化的维护成本是前期高、后期低:用例是自然语言,UI 变更只要语义不变就不需要修改。长期看(3-5 个版本后),AI 方案的总维护成本更低。
2.5 覆盖场景
传统:只能操作已知元素,原生控件没问题。WebView、自定义控件、Canvas、跨应用交互(系统弹窗、分享面板)很困难。
AI:理论上能看到就能操作。任何视觉可识别的元素都能处理,包括自定义控件、WebView、跨应用弹窗。
2.6 可靠性:确定性 vs 概率性
传统:同一条用例跑 100 次,结果应该一致。失败一定是真的失败,可信度 100%。
AI:同一条用例跑 100 次,可能有 2-5 次因推理偏差失败(经验估算)。误报率存在,需要多次执行或人工确认。
可靠性工程
AutoPilot 通过多层设计提高可信度:
1. 动作解析容错:解析失败时重试最多 3 次 2. 模型重试策略:空响应或异常时指数退避重试 3. 双模型断言:执行和断言使用独立模型,避免"自己验证自己" 4. 强约束模式:严格按步骤执行,完成后立刻 finish 5. 操作可视化:每次 tap/swipe 自动生成带标注截图
三、决策表
| 传统 | ||
| AI | ||
| AI | ||
| 传统 | ||
| AI | ||
| AI | ||
| 传统 | ||
| AI |
四、混合架构——不是二选一
实际项目中,AI 和传统是互补关系。最优解是混合使用:
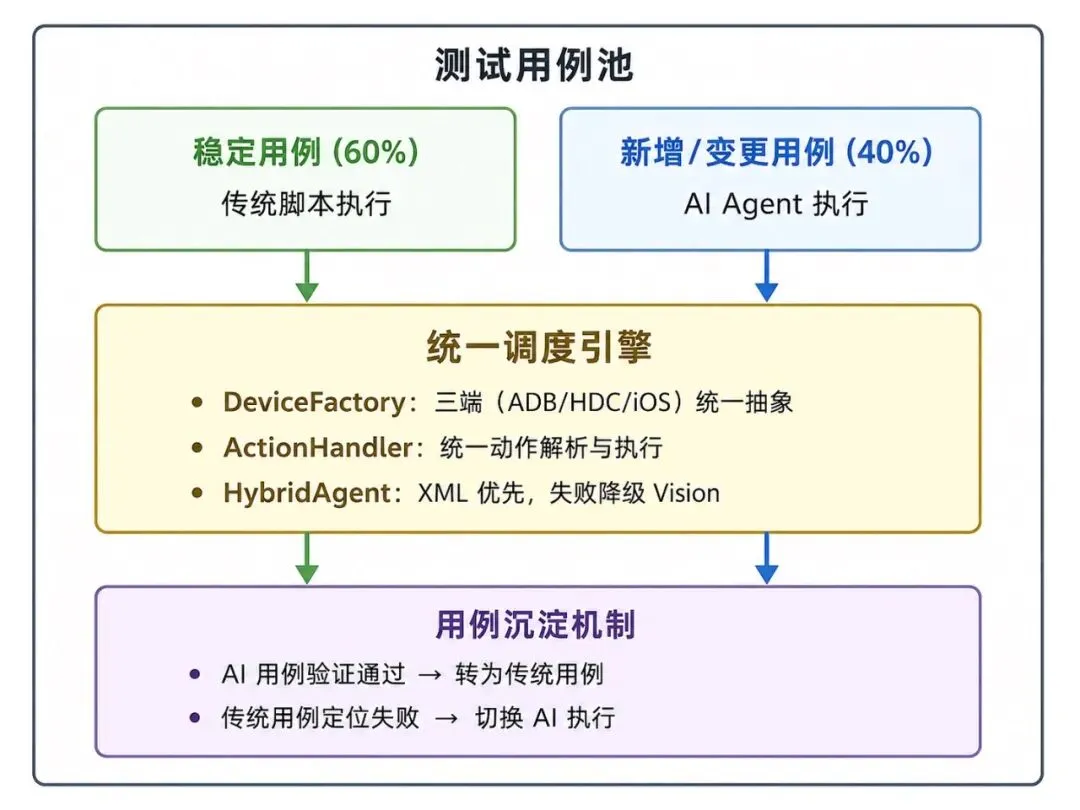
核心循环:
1. 新功能上线 → AI 快速生成并执行用例(分钟级覆盖) 2. 用例验证通过 → 沉淀为传统自动化用例 3. 版本迭代 → 传统用例高效回归,定位失败自动切 AI 4. UI 大改版 → AI 重新验证,传统用例重建
五、AutoPilot 实践数据
耗时数据为 AutoPilot 实测,通过率为经验估算,仅供参考。
• 稳定用例(XML 优先):单条约 5-15 秒(5 步),通过率约 90%+ • 复杂场景(Vision):单条约 10-25 秒(5 步),通过率约 85%+ • 混合模式比纯 Vision 估算快约 2-3 倍
六、总结
核心结论:不是 AI 替代传统,而是两者共生。
传统方案的确定性和速度在高频回归场景中不可替代;AI 方案的灵活性和低门槛在新功能验证和探索性测试中价值巨大。通过混合架构(XML+Vision)、任务预处理、双模型断言等工程设计,可以显著提升 AI 测试的速度和可靠性。
相关文章:
- 欢迎关注 AutoPilot,获取更多移动端测试工程实践。
