 夜雨聆风
夜雨聆风
AI工具在不断赋能教育的同时,也给教学带来了新的挑战。
近日,有高校发布通知明确,如果学生不规范使用AI,教师可能被暂停指导资格、通报批评,甚至被追究教学事故责任。
陕西某高校发布《关于规范本科毕业论文(设计)使用人工智能工具的通知》,提出如发现毕业论文存在违反AI工具使用规范的问题,一经查实,除学生需承担相应责任外,还将依据学校《教学事故认定与处理办法》追究指导教师责任。
广东某高校发布《关于规范实践环节学术不端行为及合理使用AI工具的通知》,明确要求学生规范使用人工智能工具开展毕业论文(设计)、实习实践等工作。值得关注的是,通知同时提出,教师未履行审查责任的,将视情况暂停指导资格或给予通报批评。
……
过去两年,高校关于生成式AI的讨论,更多集中于学生利用AI代写作业、撰写论文等学术诚信问题。而如今,随着AI深度进入课程教学、论文指导、实践训练等环节,高校开始关注另一类风险——AI生成的错误内容进入教学和学术成果之后,会带来什么后果?
此前引发广泛关注的香港大学论文撤稿事件,就给高校敲响了警钟。
一篇发表于《当代中国人口与发展》的论文因存在大量无法核实来源的参考文献而被撤稿。作者事后承认曾使用AI工具辅助整理文献,但未进行核查与披露。受此影响的不仅是论文作者本人,作为论文通讯作者和导师的叶兆辉教授也公开承认自己负有责任,并卸任社会科学院副院长等职务。
这一事件背后,折射出的正是高校正在面对的新问题:当AI深度参与教学的各个环节之后,如何避免AI出错导致的危害?
在讨论这一问题时,一个绕不开的概念是“AI幻觉”。所谓AI幻觉,是指人工智能生成看似合理、逻辑完整,但实际上存在事实错误、内容虚构甚至完全捏造的信息。例如编造参考文献、虚构案例出处、捏造数据来源等。香港大学事件中的虚假文献,就是典型表现之一。
值得警惕的是,AI幻觉往往不像传统错误那样容易被发现。它不会告诉你“我不知道”,反而会以一种非常自信的方式给出答案。很多时候,其表述逻辑严密、语言流畅,甚至带有很强的专业感和权威感。想要规避AI幻觉,往往还需要人工进行审核其回答有没有权威来源。
为什么会这样?从技术原理来看,AI并不是在“查资料后回答问题”,而是在已有训练数据基础上预测最有可能出现的内容。当面对缺乏可靠信息支撑的问题时,它仍然倾向于生成一个答案,而不是直接承认不知道。
与此同时,目前主流AI模型的训练和评价机制也更鼓励“给出答案”,而非“选择弃权”。再加上模型本身并不具备准确判断自身知识边界的能力,这使得“AI幻觉”很难被彻底消除。
换句话说,AI幻觉并不是某一个工具的特殊问题,而是当前大模型技术普遍存在的局限。但对于高校教师而言,真正棘手的问题是:如果学生没有主动说明,教师如何判断论文中的文献是否真实存在?数据是否真实可靠?案例是否真实发生?论证过程是否经过独立思考?
“坏消息”是,目前国内外都尚未形成完全可靠的AI内容识别方案。许多检测工具都存在误判和漏判问题,难以作为最终依据。
这意味着,在多数情况下面对学生交上来的学习成果,教师需要人工识别,这也无形中增加了教师的工作负担:过去,教师关注的是学生有没有抄袭,而且查重工具还比较靠谱。而现在,相关工具并不能准确识别问题,因此教师还需要核实参考文献是否真实、数据来源是否可信、案例出处是否准确、研究过程是否符合学术规范。
麦可思“2025年高校师生AI应用及素养研究”数据显示,“AI幻觉”带来的审核压力较突出。77.1%的高校教师都遇到过AI生成内容——看起来合理,实际却有错误。为了避免教学、科研出现失误,教师必须花大量时间查阅权威资料核对、调整提问方式,甚至筛选更可靠的AI工具。
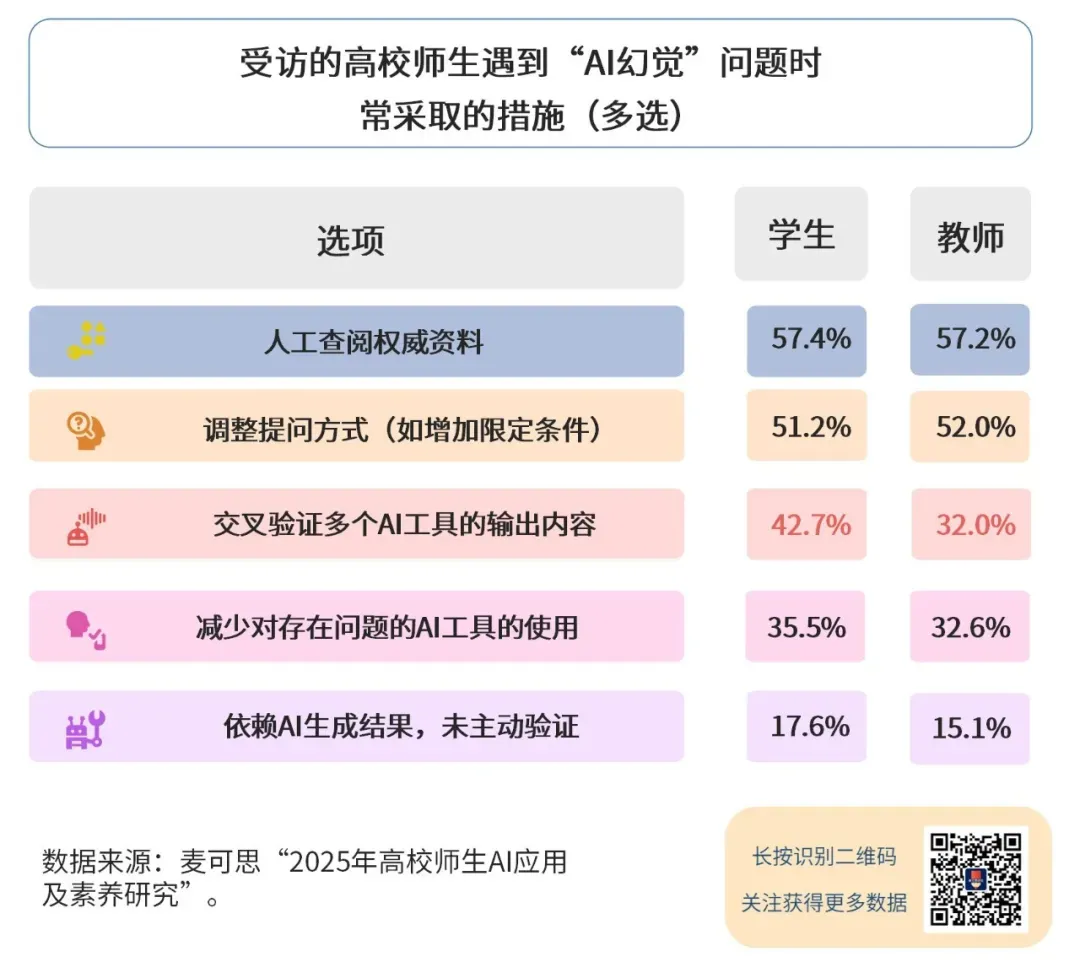
《中国教育学刊》刊发的《论人工智能时代我国的教师能力建设》指出,人工智能时代教师面对大量AI生成内容,需要投入更多时间和精力进行核验。经合组织(OECD)在《2026年数字教育展望》中指出,教师需要投入大量精力甄别学术不端行为、验证AI生成内容的准确性,这已经成为一种新的隐性工作负担。对于不少教师来说,AI节省下来的时间,往往又以审核、核验和把关的形式被“还”了回来。
目前来看,人工智能可以参与教学过程,也能够生成内容,但无法对内容的真实性、准确性和教育价值负责。在当前技术条件下,教师仍然是课堂教学、论文指导和学术评价中的关键把关者。
从这个意义上看,高校陆续出台相关规范,不仅是在回应AI快速进入教育场景所带来的现实挑战,也是在重新明确技术应用与教育责任的边界。当AI越来越深入地参与教学活动时,如何在提高效率与保障质量之间找到平衡,或许将成为未来一段时间高校共同面对的重要课题。
【拓展阅读】为什么AI宁可瞎编,也不说“不知道”
当前,人工智能系统经常出现“一本正经地胡说八道”的现象,即生成看似合理实则错误的内容,而不愿意直接表示“不知道”。为什么会这样呢?麦可思研究综合科普了相关科普文章——
首先要明确的是AI并非故意“胡编乱造”,根本原因在于其“能力有限”。主要原因可归纳为以下三个方面。
一、随机事实的答案空间过大,记忆容量有限
对于需要回答随机事实类问题的场景,正确答案的数量有限,而可能的错误答案则近乎无限。从概率分布看,正确答案在所有可能答案中的占比趋近于零。
更为关键的是,这类问题属于“随机事实”——单个答案的正误无法通过逻辑推理推广至其他答案。因此,人工智能系统只能依靠对训练数据的记忆来应对此类问题。尽管当前模型的参数规模远超人脑的记忆能力,但对于现实中存在的近乎无限的随机事实组合,其容量仍然严重不足。
即使能够排除绝大多数错误答案,剩余的错误候选项仍足以淹没真实的正确答案。在此情形下,模型只能随机选取一个输出,从而产生所谓“AI幻觉”。
二、评价机制的二元性鼓励模型输出而非弃权
当前主流的人工智能评价基准大多采用二元评分体系——回答正确得分,回答错误不得分。在此类框架下,模型输出“我不知道”也被视为错误回答。一项针对多个主流评测基准的调查显示,绝大多数基准均未赋予“弃权”任何分值。
在此种评分机制下,敢于随机输出答案的模型反而更有可能获得正分,而选择承认不知道的模型则被扣分。这就在客观上“鼓励”了模型在不确定时仍然进行猜测,而非表达不确定性。——因为回答错误和说不知道均扣分,但万一猜对了呢
三、模型缺乏自知之明,允许弃权可能适得其反
那可以允许模型说不知道来解决其胡说八道的问题吗?研究表明,人工智能系统并不具备对自身知识边界的准确感知能力——即“自知之明”。模型在不确定性与确定性之间的判别能力极为有限,其无法可靠地判断某一问题是否属于其能力范围之内。
一项研究数据显示,允许模型说“我不知道”后,并未能完全消除幻觉;相反,原本能够正确回答的部分问题反而因模型误判而转为弃权或错误,导致整体正确率下降。也就是说即使调整评价机制,允许模型输出“我不知道”,问题也无法从根本上解决。
基于此,福建省科技馆建议,虽然AI幻觉频发但用户不必全盘否定AI,关键在于理性使用:
关键信息要核实:将AI回答视为“线索”而非“标准答案”,重要内容需经权威渠道确认。
提问时留条“退路”:加上“如不确定请说明”等提示语,AI更可能坦诚承认不确定。
复杂问题拆开问:分解大问题,降低AI出错概率,便于定位问题。
主要参考文献:
[1]为什么AI宁可瞎编,死都不愿意说“不知道”?[EB/OL]. 好奇博士实验室, 20260506.
[2]如何防止AI一本正经地胡说八道?[EB/OL].福建省科技馆微信公众号, 20251209.
[3]2025年高校师生AI应用及素养研究[EB/OL]. 麦可思研究微信公众号,2025.
[4]朱旭东, 徐沛缘, 高鸾.论人工智能时代我国的教师能力建设[J].中国教育学刊, 2025(9): 10-16.
[5]OECD.2026年数字教育展望: 探索生成式AI在教育中的有效应用[R],2026.
[6]各校网站

点击下方获取更多相关主题内容
☞教学评价
☞新双高
☞审核评估
☞专业建设
☞就业工作
关注“麦研文选”,获取更多数据——
☞回复“蓝皮书”,可获取最新就业蓝皮书数据。
