 夜雨聆风
夜雨聆风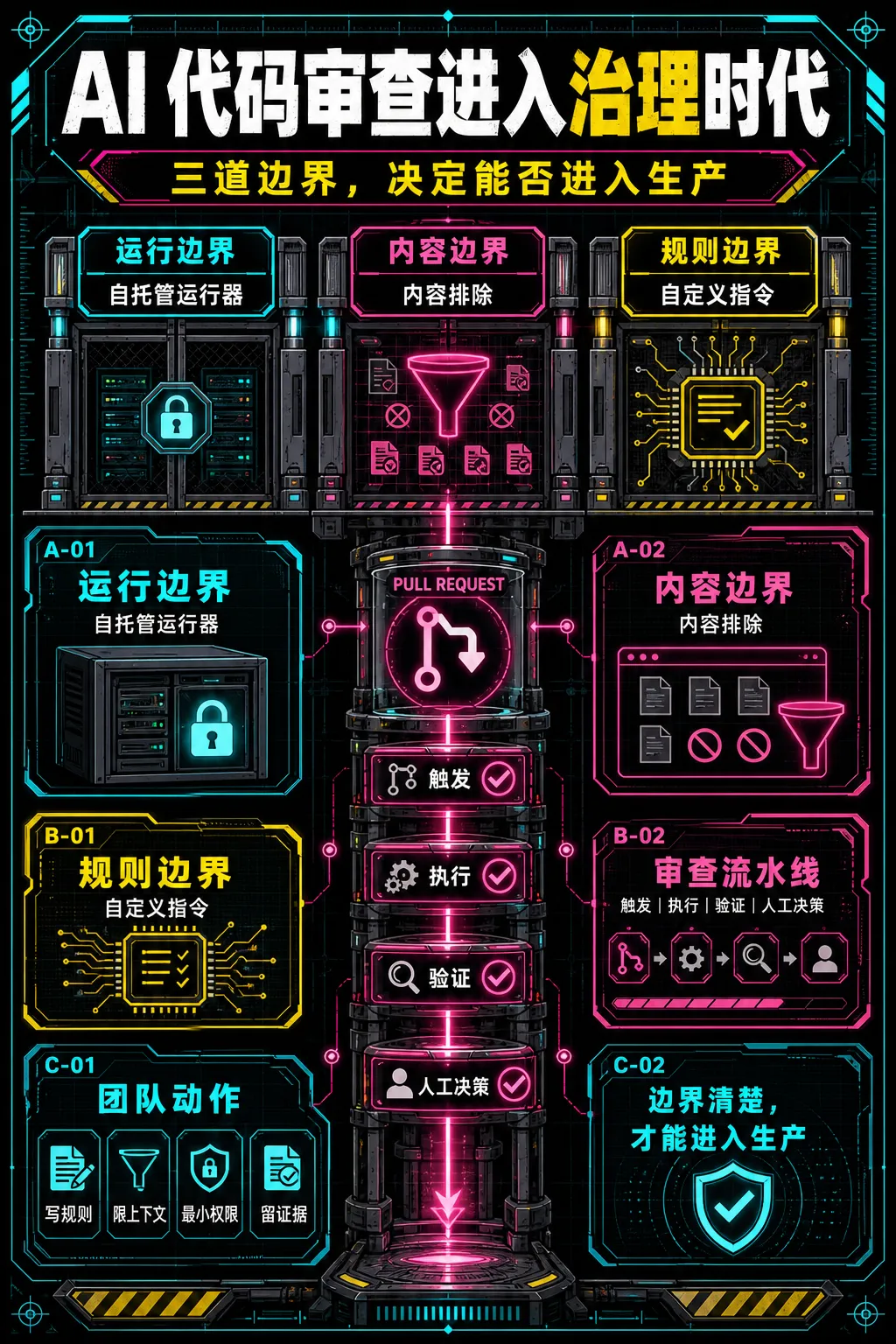
AI 代码审查开始进入治理时代:GitHub 把规则、边界和运行器交给团队
过去一年,AI 代码审查最常见的卖点是“更快发现问题”。
但当它真正进入企业仓库后,团队很快会发现,准确率只是第一道门槛。更难的问题是:它在哪台机器上运行?可以读取什么内容?应该遵守哪些团队规则?建议能否追溯?不同仓库能否采用不同策略?
6 月 12 日,GitHub 为 Copilot code review 发布了一组新的配置与控制能力。开发团队可以为代码审查配置自托管运行器、控制审查时可读取的内容,并通过自定义指令让 Copilot 遵循团队自己的工程规范。
这次更新看起来不像一个炫目的模型升级,却释放了一个更重要的信号:
AI 代码审查正在从“一个会发表评论的机器人”,变成“可配置、可约束、可纳入组织流程的工程节点”。
一、为什么代码审查比代码生成更需要边界
生成代码时,开发者通常会主动选择上下文,把一个任务交给 AI,再检查它产出的修改。
代码审查不同。审查者天然处在更广的观察位置:它要读取变更、理解仓库结构、查找相关实现、识别安全风险,还可能参考构建配置、测试规则和内部约定。
观察范围越广,价值越大,风险也越高。
企业真正关心的问题包括:
- AI 审查是否必须运行在组织控制的基础设施中;
- 它能否看到仓库之外的网络或服务;
- 哪些文件可以作为上下文,哪些内容应被排除;
- 它应该依据通用最佳实践,还是团队自己的规范;
- 审查建议是否稳定、一致,能否进入现有合规流程。
如果这些问题没有答案,AI 审查很容易停留在个人开发者的辅助工具阶段。团队可能愿意试用,却不敢把它设置为关键仓库的默认审查者。
GitHub 这次新增的三类控制,恰好对应了生产落地最核心的三道边界:运行边界、内容边界和规则边界。
二、自托管运行器解决的是“在哪里执行”
新配置允许 Copilot code review 使用自托管运行器。
对于普通项目,GitHub 托管环境通常已经足够方便。但在企业场景中,代码审查有时需要访问内网依赖、私有包、专用构建工具,或者必须遵守特定的数据驻留和网络隔离要求。
自托管运行器让组织可以把执行环境放在自己控制的基础设施里,并沿用既有的网络、身份、日志和安全策略。
它带来的价值不只是“能跑起来”,而是可以回答一系列治理问题:
- 运行器属于哪个安全区域;
- 可以访问哪些内部资源;
- 使用什么身份和临时凭证;
- 执行日志保留在哪里;
- 出现异常时由谁暂停和排查。
这与普通 CI/CD 的演进非常相似。自动化能力一旦成为生产流程的一部分,团队关心的就不再只是功能,而是执行环境是否可控。
三、内容排除解决的是“允许看什么”
AI 审查需要上下文,但上下文并不是越多越好。
仓库中可能存在生成文件、快照、第三方代码、大型数据文件,以及不应该进入模型上下文的特定目录。让审查系统无差别读取所有内容,会增加噪声、成本和不必要的数据暴露。
新的内容控制让团队能够更明确地限定 Copilot code review 在审查时应排除的内容。
这会直接改善两件事。
第一,减少无效上下文。审查者把注意力集中在真正需要判断的源代码、配置和测试上,而不是被生成产物或供应商代码干扰。
第二,建立最小必要原则。AI 只读取完成当前审查所需的内容,而不是默认获得整个仓库的最大可见范围。
对企业来说,这种“少看一点”的能力,往往和“多发现几个问题”同样重要。
四、自定义指令解决的是“依据什么判断”
通用模型可以识别常见错误,但每个团队都有自己的工程语境。
有的团队禁止在业务层直接访问数据库,有的团队要求所有外部请求必须设置超时,有的团队对日志脱敏、错误码、依赖方向、测试覆盖和 API 兼容性有明确约定。
如果 AI 不知道这些规则,它给出的建议可能技术上没有错,却不符合项目实际。
自定义指令让团队可以把这些审查标准明确写下来,供 Copilot code review 在判断变更时参考。它把过去散落在 Wiki、口头经验和资深工程师记忆中的隐性规则,逐步转化为机器可读取的工程约束。
真正有价值的自定义指令不应该是一篇空泛的编码规范,而应该足够具体:
- 检查外部请求是否设置超时和重试上限;
- 禁止在日志中输出访问令牌和个人信息;
- 数据库迁移必须提供回滚或兼容策略;
- 公共 API 变更必须说明向后兼容影响;
- 修复缺陷时必须补充能够复现问题的测试。
规则越清晰,AI 审查越接近团队的真实判断标准。
五、Agentic Workflows 让审查从评论走向流水线
6 月 11 日,GitHub 还宣布 Agentic Workflows 进入 public preview。
把这两次更新放在一起看,方向更加清楚:AI 不再只是在 Pull Request 页面里留几条评论,而是开始进入可以触发、执行、验证和交接的自动化工作流。
未来的代码审查链路可能包括:
1. 变更触发 AI 初审;
2. 在受控运行器中执行测试与安全检查;
3. 按仓库规则过滤上下文并评价风险;
4. 对高风险问题生成可复现证据;
5. 将仍需判断的事项交给人类审查者。
这里最关键的不是取消人工审查,而是重新分配注意力。
AI 负责重复、广覆盖和可自动验证的部分;人类负责架构权衡、业务语义、风险接受和最终责任。
六、团队现在应该做什么
第一,把审查规则从“大家都知道”变成仓库里的明确文本。
优先整理最容易造成事故、最适合客观判断的规则,例如权限、隐私、超时、错误处理、迁移兼容和测试要求。
第二,为 AI 建立最小上下文边界。
列出生成目录、第三方代码、大文件和敏感区域,明确哪些内容无需或不应进入审查上下文。
第三,把 AI 审查当成自动化账号治理。
它需要独立身份、最小权限、受控运行环境、日志记录和故障处置流程,而不是继承某位开发者的全部能力。
第四,用误报率和漏报类型评估效果。
不要只统计 AI 留了多少评论。更有意义的指标是:哪些建议被采纳、哪些规则最常触发、哪些严重问题仍然漏掉,以及它为人工审查节省了多少有效时间。
结语
AI 编程的前半场比拼生成速度,下一阶段会越来越多地比拼治理能力。
当 AI 进入代码审查,它拥有的不是一个文本框,而是对组织代码、规则和交付流程的观察权。这样的能力必须有明确的运行位置、内容边界和判断依据。
GitHub 这次更新的意义,就在于把这些过去留给企业自行补齐的问题,开始变成产品的一等配置。
真正成熟的 AI 代码审查,不是评论更多,而是在正确的环境里,只读取必要的内容,按照团队认可的规则,给出可以追溯的判断。
---
参考资料
- GitHub Changelog: New configuration options and controls for Copilot code review, 2026-06-12
https://github.blog/changelog/2026-06-12-new-configuration-options-and-controls-for-copilot-code-review/
- GitHub Changelog: Agentic Workflows in public preview, 2026-06-11
https://github.blog/changelog/2026-06-11-agentic-workflows-in-public-preview/
