 夜雨聆风
夜雨聆风导语:这两年你被"AI 要取代一切"轰炸得够呛。可最近硅谷在吵一件相反的事——AI 是不是开始变慢了?这篇咱们把"缩放定律""数据墙""撞墙论"几个词一次讲清楚,看完你大概能分清,哪些是真问题,哪些是吵架。

一、先说个反常识的事
你有没有发现,最近一年,AI 新模型发布会上的"哇"声,明显小了?
前几年不是这样。2023 年一个新模型出来,能把你看傻:会写代码、会做题、会画图,每隔几个月就上一个台阶。那种感觉,就像看着一个孩子,今天会爬、明天会走、后天就能跑了,你都来不及惊讶。
可到了 2025、2026 年,画风变了。新模型当然还在出,参数更大、跑分更高,但你心里那个"卧槽"越来越难被点着。更要命的是,2026 年 6 月,一篇题目就叫《AI 正在放缓》的评论文章,在程序员聚集的 Hacker News 上炸了锅——500 多分、500 多条评论,吵成一团。一派说"早就该慢了,泡沫要破";另一派说"你们根本不懂,人家换赛道了"。
这就奇怪了。一边是各家公司天天喊"通用人工智能就在眼前",一边是技术圈自己人开始唱"它快到顶了"。到底谁对?
要看懂这场架,得先搞清楚一个词:缩放定律 (Scaling Laws)。说白了,它是过去五年整个 AI 行业的"信仰"。这篇咱们就从这个信仰讲起,看看它现在为什么动摇了。
事件速览
• 争论引爆点 :2026 年 6 月,评论文《AI is slowing down》登上 Hacker News 热榜(约 504 分、525 条评论),重新点燃"AI 进展是否在递减"的辩论。 • 核心概念 :缩放定律——OpenAI 团队 2020 年(Kaplan 等)提出,DeepMind 2022 年用"Chinchilla"实验修正,大意是模型能力随"参数 + 数据 + 算力"的增加而可预测地变强。 • 关键裂痕 :2024 年底,OpenAI 联合创始人 Ilya Sutskever 在 NeurIPS 公开说"我们所知的预训练将会终结"。 • 两派态度 :Sam Altman 坚持"没有墙"(there is no wall);Anthropic 的 Dario Amodei 认为缩放"大概率会继续";怀疑派则认为收益已明显递减。
二、缩放定律:AI 行业信了五年的那条"曲线"
要理解今天的争论,得先回到 2020 年。
那一年,OpenAI 的研究者 Kaplan 等人发了一篇论文,干了件特别"理工男"的事:他们把模型做大、把数据喂多、把算力堆高,然后画了一条曲线。结果发现——模型的"损失"(可以粗暴理解成"犯错的程度")随着这三样东西的增加,居然以一种相当规整、可预测的方式往下掉。
这是什么概念?等于说,AI 的进步第一次有了"配方"。 你不用靠灵感、靠运气,只要往里砸钱、砸数据、砸显卡,模型就会按一条曲线稳稳变强。这在科学上很罕见——大部分领域,你投入翻倍,产出根本不会乖乖跟着走。
2022 年,DeepMind 又用一组叫"Chinchilla"的实验把这个配方调精细了:他们指出,之前大家普遍"参数堆太多、数据喂太少",最划算的练法,是参数和数据按一定比例一起涨。这就是著名的"Chinchilla 最优"。
打个比方,这就好比熬汤。Kaplan 告诉你"火越大、料越多、时间越长,汤越鲜";Chinchilla 进一步告诉你"料和水得按比例放,光加料不加水,咸得没法喝"。
有了这个配方,过去五年整个行业的逻辑就清晰了:拼命变大。 谁的显卡多、谁的数据多、谁敢烧钱,谁的模型就强。于是你看到了那场疯狂的军备竞赛——英伟达的显卡被抢空,几百亿美元砸进数据中心,电力都快不够用了。

这条曲线,就是 AI 行业信了五年的"上帝公式"。问题来了——它,开始不灵了。
三、往下挖一层:曲线为什么会"压扁"
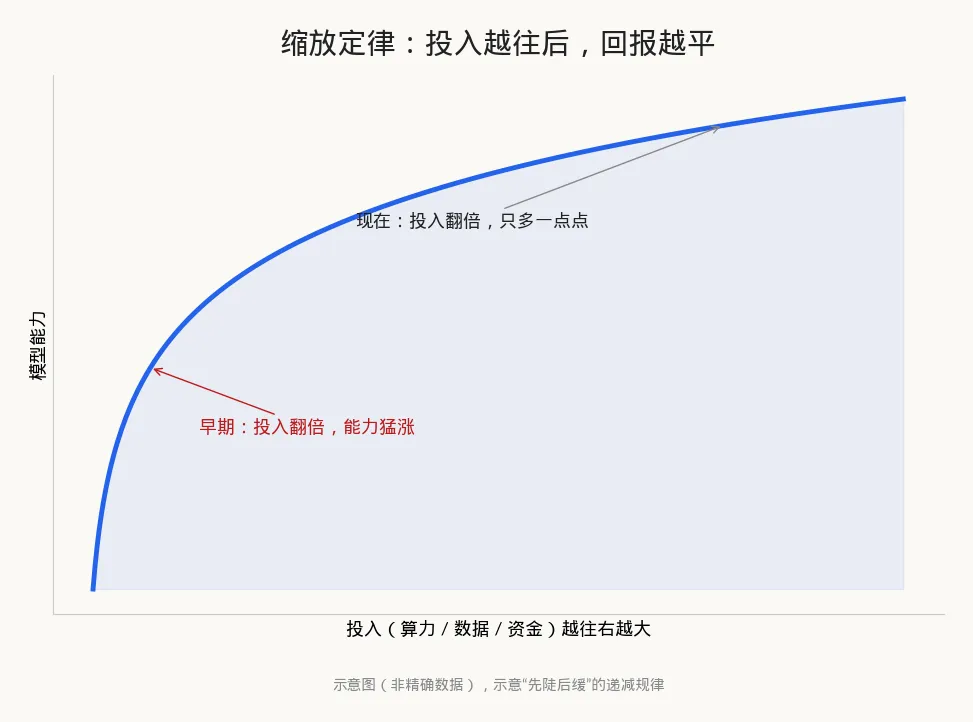
注意,没有人说曲线断了、反转了。争论的焦点是两个字:递减。
什么叫递减?还是看那条曲线。它从来不是一条 45 度的直线,而是一条"先陡后缓"的弧线。一开始,你投入翻一倍,能力蹭蹭涨;可越往后,同样翻一倍,涨幅越来越小。到了某个阶段,你花了双倍的钱,模型可能只在最难的推理题上好了 10% 到 20%。
这就是麻烦所在。早期,从"小学生"到"大学生",投入不大、提升惊人;现在已经是"博士"了,想再往上拱一点点,得砸进去几倍的资源。投入是真金白银地翻番,体感进步却越来越不明显。
为什么必然会这样?至少有三道坎,咱们一道道看。
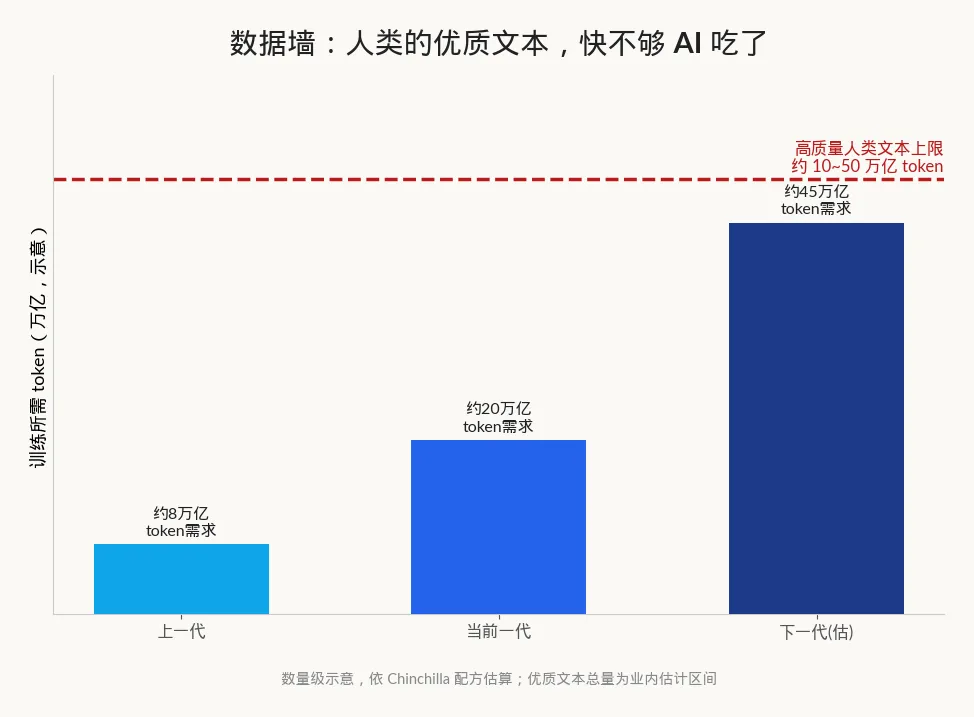
第一道坎,是数据墙。 这是最硬、也最容易被忽略的一条。前面说了,配方里有一项是"数据"。可数据不是无限的——高质量的人类文本,全互联网加起来,业内估算大概就在 10 万亿到 50 万亿 token 这个区间(token 你可以粗略理解成"词的碎片")。听着很多?但一个万亿参数级别的模型,按 Chinchilla 的配方,胃口就得 20 万亿 token 上下。
换句话说,人类几千年攒下的文字,快不够 AI 吃了。 这就好比一个学霸,把图书馆所有书都背完了,你让他再聪明一点,他上哪儿找新书?剩下的,要么是低质量的网络垃圾,要么是 AI 自己生成的内容——可拿 AI 的输出再喂 AI,容易"近亲繁殖",越练越蠢。这道坎,光靠钱是推不动的。
第二道坎,是成本墙。 缩放定律有个残酷的隐含前提:你想要线性的能力提升,往往得指数级地加投入。结果就是训练成本坐了火箭。业内估算,如今训一个前沿模型,单是算力就要约 5 亿美元;下一代的数字,被一些分析摆到了 10 亿乃至 100 亿美元。
钱能解决的问题都不是问题?可当账单大到这个程度,它本身就成了问题。因为商业是要算回报的。 你花 100 亿训出来的模型,如果只比上一代好那么一点点,用户感知不强、愿意多付的钱也有限,这笔买卖就开始亏。资本不是慈善,递减的不只是技术曲线,还有投资回报曲线。
第三道坎,是体感墙。 这条最微妙。模型在跑分榜上还在涨,可普通用户的"哇"声为什么小了?因为人对"聪明"的感知,本身就是非线性的。一个能答对 80% 问题的助手和一个能答对 90% 的,你日常用起来,差别没有数字看上去那么大;但要把那 10% 啃下来,研发难度是地狱级的。跑分还在涨,惊艳已封顶——这是递减最直观的样子。
把这三道坎叠一块儿你就明白了:所谓"放缓",不是 AI 不行了,而是"光靠把预训练做大"这条最好走的路,越来越贵、越来越挤、越来越不划算。
四、再往下:行业其实早就在换路了
那是不是 AI 就到头了?这正是吵架的另一方要反驳的地方。他们说:你们盯着的是一条已经走得差不多的老路,可人家早换赛道了。
这话有依据。2024 年底,连"缩放定律"的旗手之一、OpenAI 联合创始人 Ilya Sutskever,都在 NeurIPS 大会上公开说了一句分量很重的话——"我们所知的预训练,将会终结。" 他还说,2010 年代是"缩放的时代",而现在,我们重新回到了"探索和发现的时代"。
请注意,他说的是"我们所知的预训练"终结,不是"AI"终结。这中间差着十万八千里。意思是:单纯把模型练大这一招,红利快吃完了,但故事换了主角。
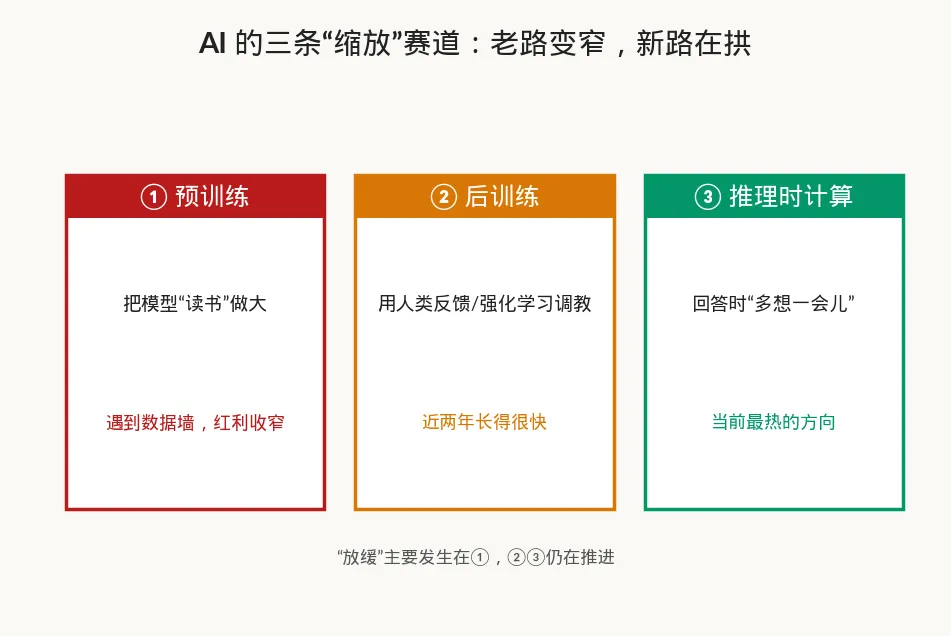
新主角是谁?现在业内大致把"缩放"拆成了三条不同的轴,预训练只是其中一条:
第一条,预训练(pre-training)。 就是前面说的老路——把海量文本喂给模型,让它先把世界"读"一遍。这条遇到了数据墙,红利在收窄。
第二条,后训练(post-training)。 模型"读"完书之后,再用人类反馈、强化学习去"调教"它,教它怎么把知识用得更对、更合人意。这就像一个读完万卷书的学生,还得有人带他实习、纠正他的毛病。这条路这两年长得很快。
第三条,推理时计算(test-time compute)。 这是最近最热的方向,也是 o 系列这类"推理模型"的核心。说白了,就是不在训练时死磕,而是让模型在回答你问题的时候,多想一会儿。 以前模型是"脱口而出",现在是"先在草稿纸上演算,再给你答案"。同一个模型,让它多花点时间思考,难题的正确率能明显上去。
打个比方你就懂了。预训练,像是让学生把所有教材背熟;这条路上,书快背完了。但你还有两招:一招是请名师给他开小灶、改错题(后训练);另一招是考试时别让他抢答,给他足够时间打草稿(推理时计算)。书背到头了,不代表分数到头了。 这就是反驳派的底气。
所以你看,"AI 放缓"这个说法本身就有点偷换概念。准确的说法是:预训练这条特定的路在放缓,但 AI 整体还在沿着另外两条路往前拱。 至于那两条新路能拱多远,老实说,现在谁也不敢打包票——这恰恰是 Sutskever 说"回到探索时代"的意思:配方失灵了,又得靠真本事去蒙、去试了。
五、对照:这一幕,像极了"摩尔定律"
如果你觉得这套"曲线压扁"的故事似曾相识,那是因为——它在科技史上演过太多回了。
最经典的对照,是摩尔定律。半个多世纪里,芯片上的晶体管数量每隔约两年翻一番,电脑一年比一年快,跟现在 AI 的剧本一模一样。可到了这十几年,物理极限逼近,晶体管小到不能再小,"摩尔定律要死了"的讣告每年都有人写。
结果呢?芯片确实没法靠"单纯做小"接着狂飙了,但行业换了打法:多核、堆叠、专用芯片、先进封装……性能照样在涨,只是不再是当年那条又陡又爽的直线。一条路走到头,从来不等于终点,而是逼着你去找新路。
AI 现在就站在这个路口。预训练这条"等比例放大"的高速公路快到尽头了,但这不意味着 AI 停车,只意味着它得下高速、走国道,速度和姿势都得变。
还有个更日常的例子:飞机。上世纪民航速度一路狂飙,大家以为很快人人都能坐上超音速客机。结果协和飞机退役,几十年来民航的巡航速度几乎没再涨——因为再快一点,油耗、噪音、成本就压不住了,性价比划不来。但航空业停滞了吗?没有,它只是不在"速度"这一个指标上死磕,转头在省油、安全、航程、舒适上接着进步。这跟 AI 是同一个剧本 :当一个最显眼的指标(飞机的速度、AI 预训练的规模)涨不动了,行业不会原地等死,而是把发力点挪到别的维度去。所以盯着"模型有没有更大"喊完蛋的人,很可能正好错过了它在"更会想、更便宜、更好用"上正在发生的事。
这里多说一句,也是这场争论里最容易被情绪带跑的地方。技术圈有个老毛病:要么神化,要么唱衰。前几年是无脑神化——"明年就 AGI、后年就失业潮";现在风向一转,又有人无脑唱衰——"泡沫破了、AI 完蛋"。这两种都是偷懒。 真实的情况往往最不性感:它既没那么神,也没那么衰,就是一个具体的技术,在一条具体的曲线上,遇到了一个具体的瓶颈,然后想办法绕过去。
六、那咱们普通人,该信谁?
吵了半天,落到你我身上,到底有啥用?我觉得有三条特别实在。
第一,对"AGI 明年就来"这种话,可以放轻松了。 当一个行业最好走的路开始递减、最关键的人都在说"老办法要终结",你就该明白,那种"指数级起飞、很快超越人类"的剧本,至少没有宣传的那么近。进步还在,但更像爬坡,不像起飞。这对天天被"AI 焦虑"轰炸的普通人,其实是个解压的消息。
第二,也别急着信"AI 是泡沫、马上完蛋"。 唱衰的人忽略了后训练和推理时计算这两条新路,也忽略了一个事实:哪怕 AI 今天就停在原地不再变强,光是把现有能力用透、铺到各行各业,红利就够吃很多年了。技术成熟和技术扩散,是两件事。 电早就发明完了,可把电用到每个角落,花了上百年。
第三,看 AI 新闻,学会问一个问题:你说的"进步",是哪条轴上的? 是预训练做得更大(红利在减),还是推理能力更强、用起来更顺、更便宜(这些恰恰还在快速变好)?分清这个,你就不会被任何一方的标题党带着走。说白了,别问"AI 还行不行",要问"AI 在哪方面行、在哪方面卡住了"。 前者是站队,后者才是判断。
七、说到底
缩放定律给了 AI 行业五年的好日子:只要够有钱、够大胆,进步几乎是"买"得到的。现在这条捷径变窄了,大家被迫重新回到"动脑子"的状态——这未必是坏事。
历史上每一次"定律失灵",事后看都不是终点,而是换挡。摩尔定律如此,今天的缩放定律大概也如此。真正的危险从来不是曲线压扁,而是你只会沿着一条曲线思考。
所以下回再看到"AI 撞墙了"或者"AGI 要来了"这种大标题,你不妨先笑一笑,然后问一句:你说的,到底是哪条轴?
参考来源
• TechCrunch:《Current AI scaling laws are showing diminishing returns, forcing AI labs to change course》(2024-11-20) • DeepLearning.AI The Batch:《AI Giants Rethink Model Training Strategy as Scaling Laws Break Down》 • Kaplan et al.(OpenAI, 2020)缩放定律原始论文;DeepMind "Chinchilla" 计算最优论文(2022) • Ilya Sutskever 在 NeurIPS 2024 的公开发言("pretraining as we know it will end")转述,见多家科技媒体报道 • 数据墙与训练成本估算:综合 buildfastwithai、aimultiple 等行业综述(数字为业内估算区间) • 引爆点:评论文《AI is slowing down》(Where's Your Ed At)及 Hacker News 讨论(2026-06) • 本文涉及人物公开言论均为转述其已报道的观点,非直接引语原文
配图来源
• AI放缓-封面/01/02/03.png:自制示意图(缩放曲线、数据墙、三条缩放轴),为概念示意,非精确数据图• AI放缓-网络1.jpg:数据中心服务器机柜,来自 Wikimedia Commons 文件页 Datacenter Server Racks (22370909788).jpg,授权 CC BY 2.0(授权以 Commons 文件页为准)
