 夜雨聆风
夜雨聆风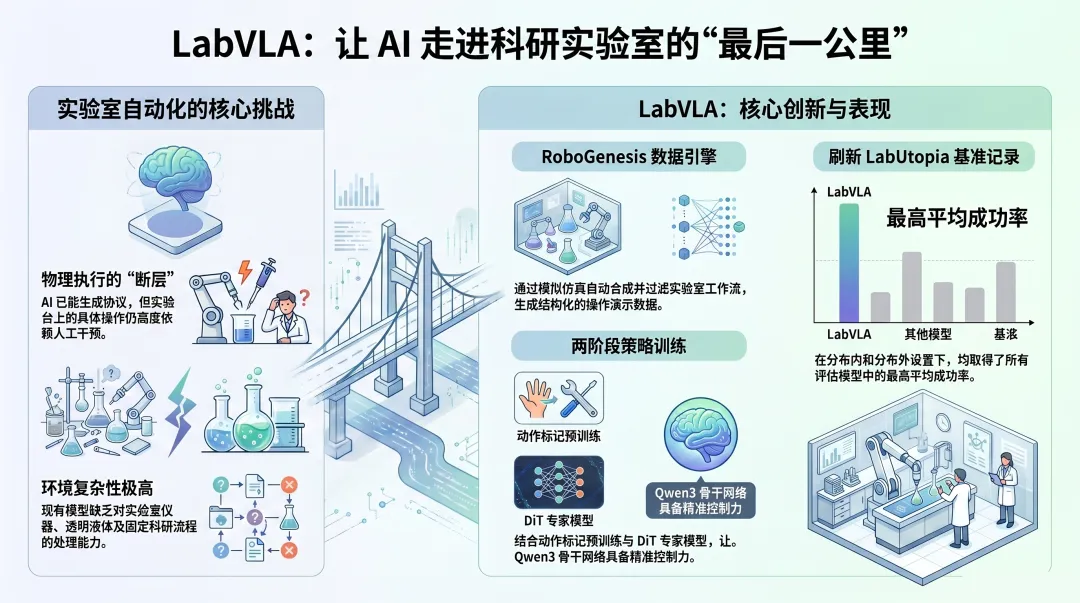
导读
想象这样一个场景:一位化学家在深夜的实验室里,面对着数十个等待处理的样本。她需要精确移液、操作离心机、在显微镜下观察、记录数据——这些重复且耗时的操作占据了她超过60%的科研时间。与此同时,AI已经能帮她阅读上千篇文献、生成实验假设、甚至规划出完整的实验方案。但到了真正"动手"的环节,一切又回到了人工时代。
这个矛盾正是LabVLA要解决的核心问题。来自浙江大学、上海AI实验室等机构的18位研究者,在2026年6月提出了一套完整的解决方案——不仅是一个模型,更是一整套"数据引擎+训练策略+评测基准"的系统工程。他们的目标很明确:让机器人真正成为合格的"AI实验员",而不只是一个会聊天的科研助手。
这篇解读将带你深入理解LabVLA的技术架构,看看研究团队如何用仿真数据引擎解决"没有实验室数据"的困境,又如何用两阶段训练让一个语言模型学会精密的物理操作。
背景与动机
科学AI的"脑手脱节"困境
当前的AI科研助手其实正处于一种尴尬的状态:大脑很发达,四肢却几乎为零。大语言模型可以理解复杂的实验方案,视觉模型能识别显微镜图像,但没有任何一个系统能够把"按照方案第三步,向96孔板的A1孔中加入50微升缓冲液"这样的指令,转化为机械臂的精确动作。
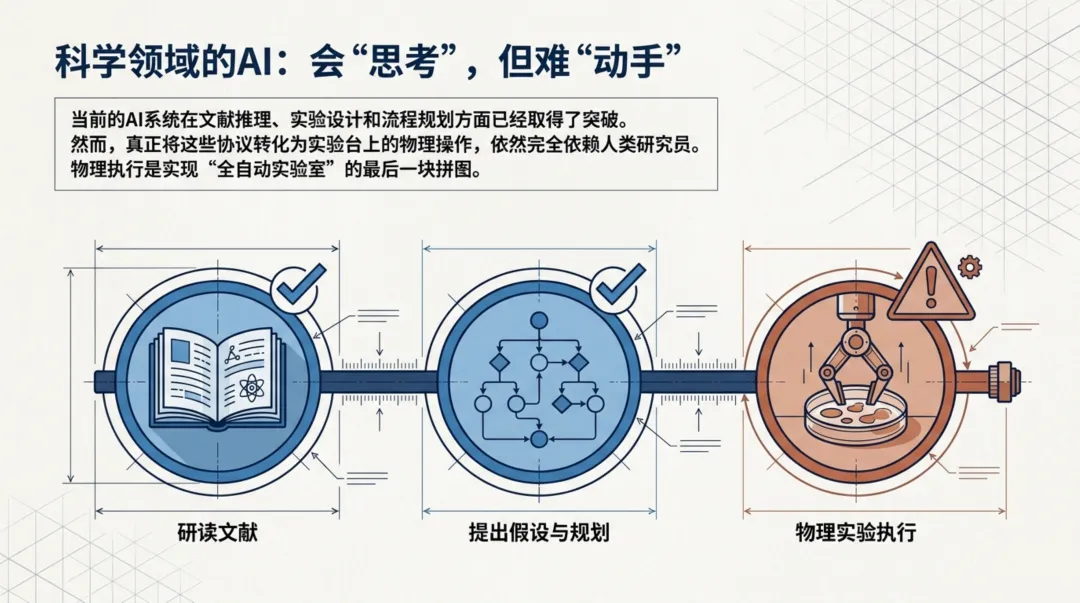
问题的根源不只是模型能力不够,更在于三个结构性瓶颈。
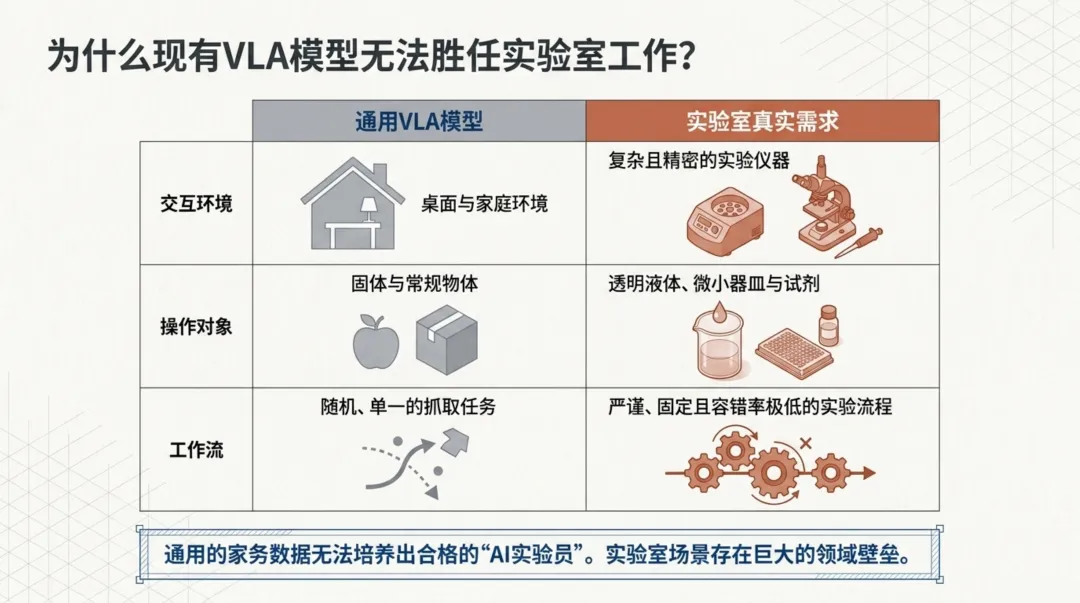
通用VLA模型为什么搞不定实验室?
视觉-语言-动作模型(VLA)是连接文本指令与机器人执行的桥梁,OpenVLA、RT-2等模型已经在家庭场景中展现了不错的能力。但把它们搬进实验室,就会遇到三个层面的"水土不服":
交互环境不同。 通用VLA在厨房台面、办公桌上训练,面对的是碗碟杯盘。实验室里是高精度天平、多通道移液器、PCR仪——这些仪器的操作精度要求高出一个数量级。
操作对象不同。 家庭场景处理的是固体和常规物体,而实验室充满了透明液体、微小器皿和试剂瓶。透明物体在视觉上极难感知,这对模型的视觉理解能力是严峻考验。
工作流不同。 家庭任务通常是随机的单一抓取,但实验操作遵循严谨的协议流程,容错率极低。一个步骤出错,整个实验可能报废。
数据与具身:双重瓶颈
研究团队敏锐地意识到,单纯改进模型算法是不够的。他们将核心瓶颈归结为两个方面:
数据稀缺。 没有人为实验室机器人操作收集过大规模的示范数据。真实实验室的数据采集成本极高——你不可能为了训练AI而浪费大量昂贵的试剂和仪器时间。
具身多样性。 不同实验室使用不同的机器人硬件——有的用Franka双臂,有的用UR5单臂,还有的用定制夹爪。一个合格的实验室策略需要能够适配多种机器人形态。
这种对问题的系统性诊断,决定了LabVLA不是一个"改改模型结构就完事"的工作,而是需要从数据生产、模型设计到评测体系的全栈式解决方案。
核心方法
RoboGenesis:实验室数据的"合成工厂"
既然真实数据获取成本太高,那就用仿真来造。RoboGenesis是一个基于模拟的数据引擎,其核心设计思路可以概括为四个环节的流水线。
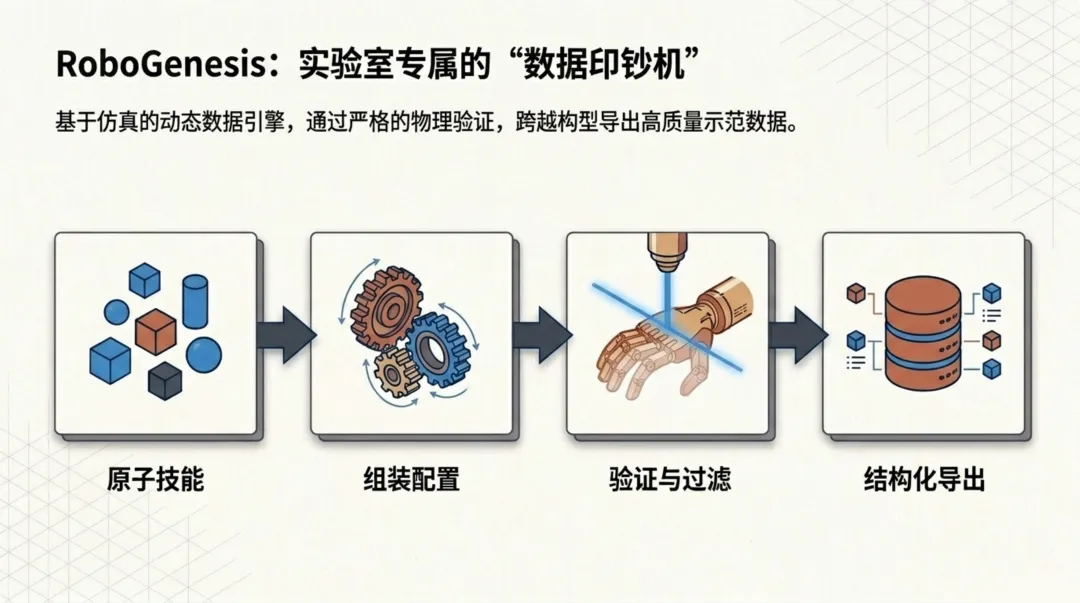
第一步:原子技能定义。 研究者将实验室操作拆解为一系列不可再分的基本动作——抓取试管、旋转瓶盖、移液、放置到指定位置等。每个原子技能都对应一个经过精确调试的仿真控制器。
第二步:组装配置。 通过组合这些原子技能,可以自动生成各种实验室工作流。比如"从试剂瓶中取出样本 -> 加入离心管 -> 放入离心机 -> 启动离心"就是一个典型的组合流程。这种组合方式的优势在于,少量原子技能可以排列组合出海量的实验场景。
第三步:验证与过滤。 不是每次仿真执行都是成功的。RoboGenesis内置了严格的物理验证机制——检查液体是否溅出、仪器是否正确操作、步骤是否遵循实验协议。只有通过验证的动作轨迹才会被保留。
第四步:结构化导出。 经过筛选的数据被导出为统一格式,支持多种机器人配置文件。这意味着同一个实验流程的数据,可以同时用于训练适配不同机械臂的策略。
这套流程的精妙之处在于"严格的物理验证"环节——它不像一般的仿真数据集那样只追求数量,而是通过自动化的质量把关,确保每一条训练数据都是真实可执行的。
LabVLA的两阶段训练方案
有了数据之后,如何训练一个既懂语言又能操作的模型?LabVLA选择在Qwen3-VL-4B-Instruct基础上,设计了一个精心编排的两阶段训练配方。
第一阶段:FAST动作令牌预训练——让模型先"认识"动作
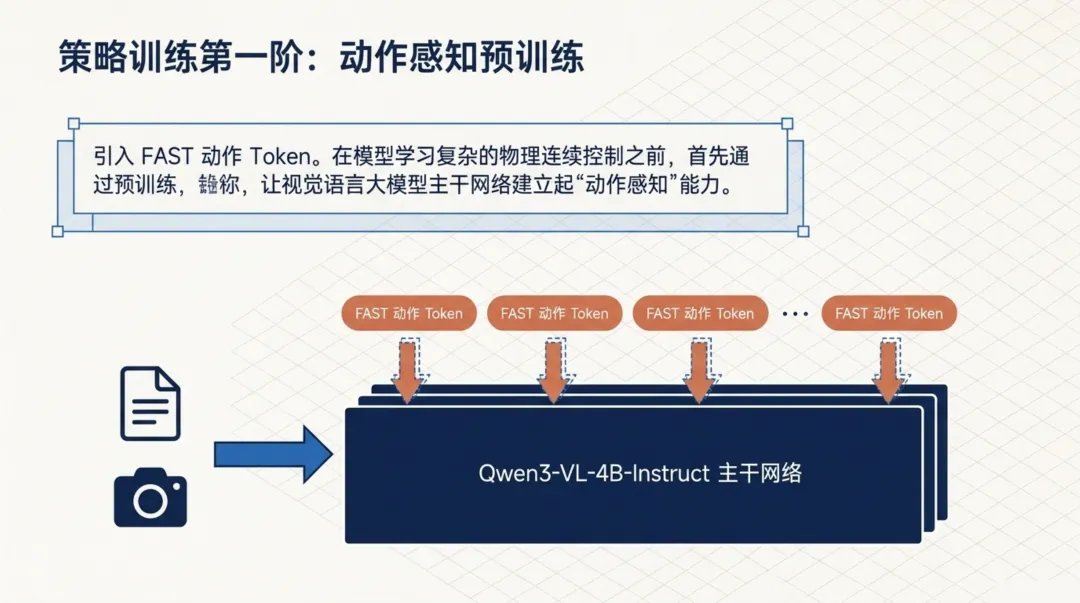
在直接让模型学习物理控制之前,LabVLA先做了一件关键的准备工作:引入FAST(Fine-grained Action Sequence Tokenizer)动作令牌,对视觉语言大模型的骨干网络进行预训练。
为什么要多这一步?因为Qwen3-VL原本是一个纯粹的视觉语言模型,它的"词汇表"里只有文字和图像的概念,完全不理解"向右移动3厘米""旋转手腕15度"这类动作语义。FAST令牌本质上是在给模型扩充一套"动作词汇",让它在学习精细控制之前,先建立起对动作空间的基本认知。
这个阶段的输入是图像和文本指令,输出是离散化的FAST动作令牌序列。模型通过大量的"看图说动作"任务,逐步学会将视觉场景与动作语义关联起来。
第二阶段:流匹配后训练——接入精密控制"外挂"
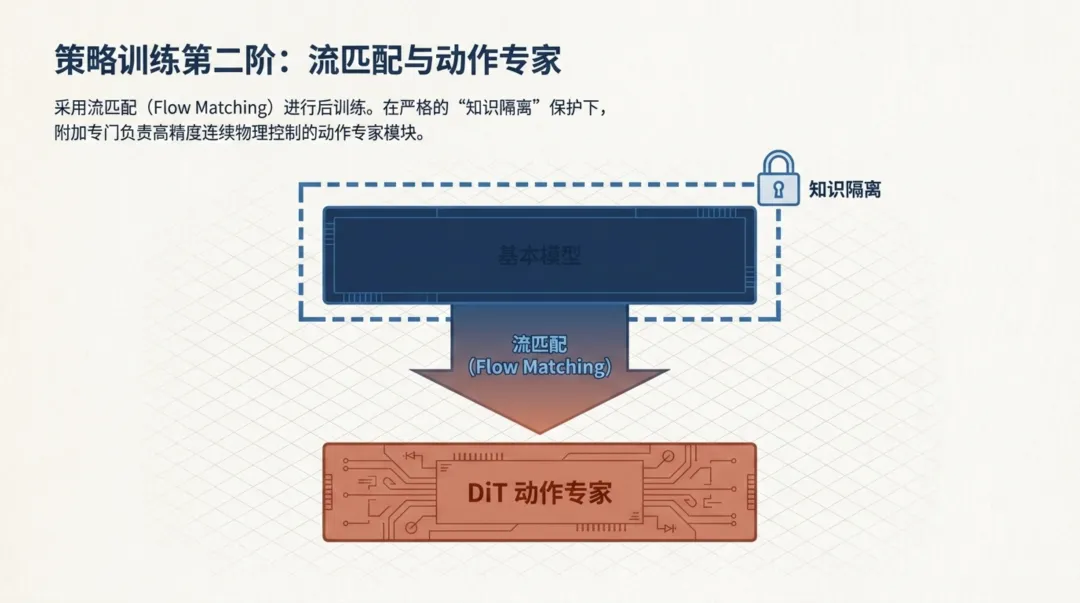
第一阶段让模型有了动作感知,但离散令牌无法直接驱动机械臂——真实的机器人控制需要连续的6-DOF或7-DOF动作输出。这就是第二阶段要解决的问题。
LabVLA采用了流匹配(Flow Matching)技术进行后训练,并引入了一个关键组件——DiT动作专家(Diffusion Transformer Action Expert)。这个专家模块专门负责将模型内部的动作理解,转化为高精度的连续控制信号。
最值得关注的是"知识隔离"(Knowledge Insulation)机制。在接入DiT动作专家时,研究者通过锁定骨干网络的权重,确保新接入的动作控制能力不会破坏模型已有的视觉-语言推理能力。这就好比给一个经验丰富的"实验策划师"配备了一双灵巧的"机械手"——策划师的思维能力完好无损,同时获得了物理执行能力。
这种"先认知后控制"的两阶段设计,体现了对VLA训练中一个核心矛盾的深刻理解:语言理解和物理控制是两种本质不同的能力,强行一起学容易两败俱伤。分阶段训练让每种能力在最适合的学习条件下获得最充分的发展。
LabVLA总体架构:从数据到执行的完整链路
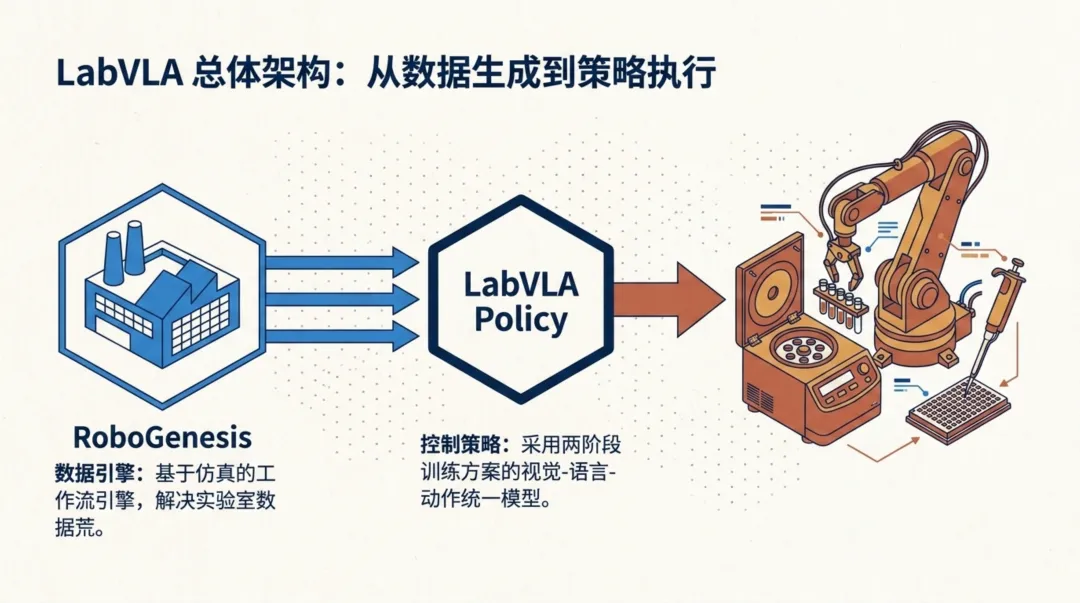
从全局来看,LabVLA的整体架构形成了一条清晰的链路:RoboGenesis负责在上游源源不断地生产高质量的仿真数据;LabVLA策略在中游通过两阶段训练获得"理解+控制"的双重能力;下游在LabUtopia基准测试平台上验证实际性能。
实验与结果
LabUtopia:为科学机器人量身定做的"考场"
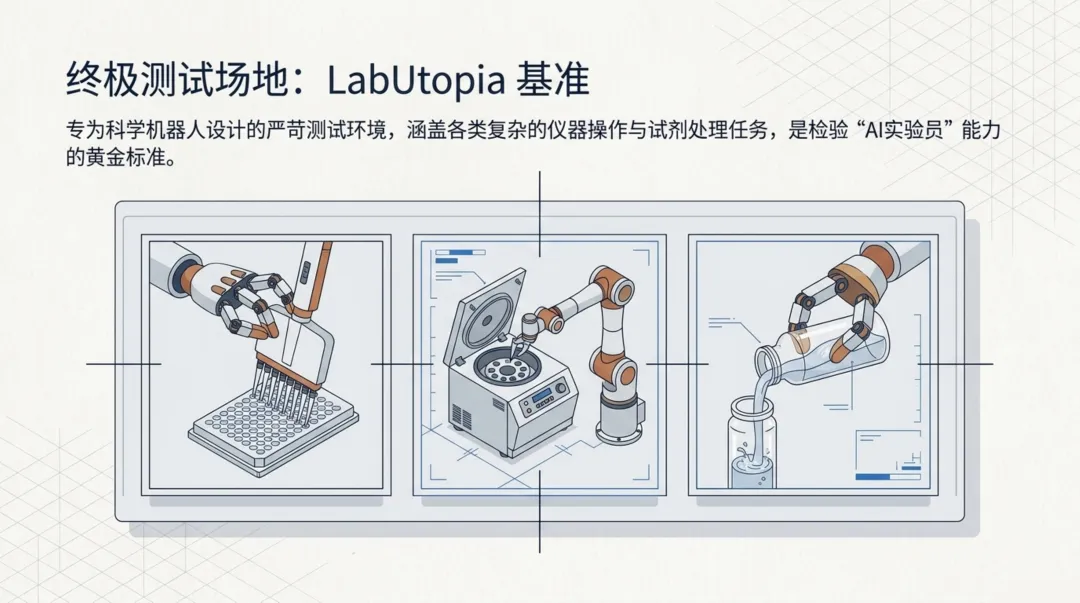
LabUtopia是一个专为科学实验室场景设计的基准测试平台,涵盖了多种典型的实验室操作任务:多通道移液器操作、离心机样品处理、显微镜观察等。这些任务不仅要求视觉感知的准确性(尤其是对透明液体的识别),还要求动作执行的精度和实验协议的严格遵守。
全面领先的性能表现
在LabUtopia基准上,LabVLA的表现令人印象深刻。在分布内(ID)设置下——即模型面对训练时见过的实验室环境和任务类型时,LabVLA取得了所有评估基线中最高的平均成功率。更重要的是,在分布外(OOD)设置下——面对全新的、训练时从未接触过的实验场景,LabVLA依然展现出了极为稳健的执行能力。
这一点尤为关键。实验室环境是不断变化的:新的试剂、新的仪器、新的实验方案层出不穷。一个真正实用的实验室AI,必须具备面对未知场景时的泛化能力,而不仅仅是对训练场景的死记硬背。
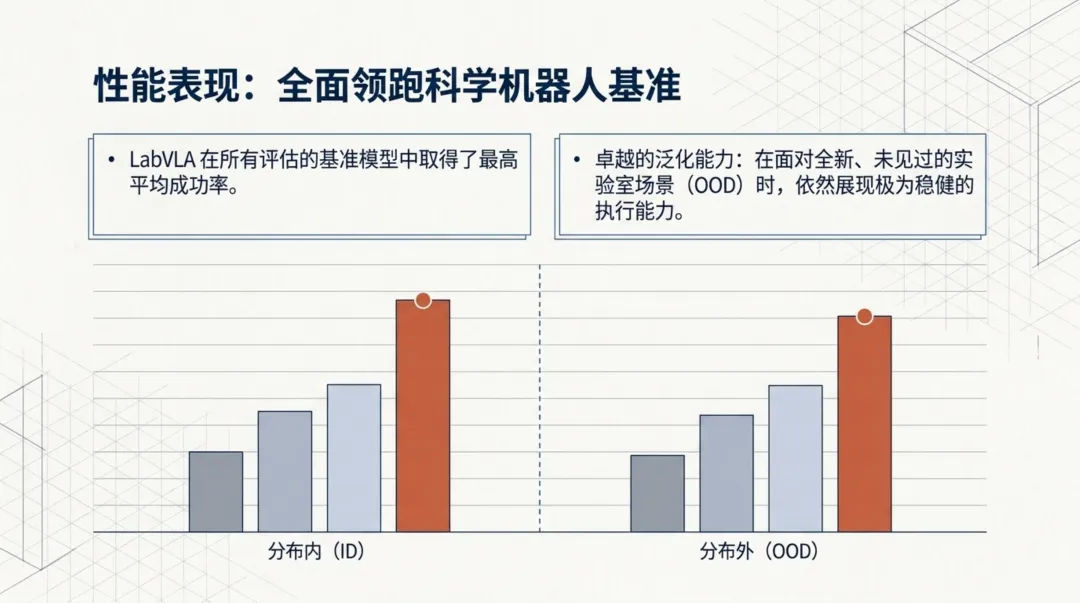
从对比柱状图中可以清晰看到,无论是ID还是OOD设置,LabVLA(橙色标记)都稳定地位于最高位置。尤其是在OOD设置下,LabVLA与其他基线方法的差距更为显著——这说明两阶段训练策略带来的不只是对已知任务的记忆,更是真正的理解和泛化能力。
讨论与思考
真正的创新在哪里?
LabVLA的核心贡献不是单一的技术突破,而是一套系统性的解决方案。在我看来,其最大的创新有三点:
第一,问题定义的准确性。 很多研究者可能会本能地认为"实验室机器人"只是一个应用场景的迁移问题,用更多数据微调一下现有VLA就行。但LabVLA团队清楚地识别出了数据、具身和模型设计这三个维度的瓶颈,并为每个瓶颈给出了针对性方案。这种系统性思维在当前"刷榜为王"的研究风气中显得格外珍贵。
第二,RoboGenesis的"组合爆炸"策略。 用原子技能组合出复杂工作流,再通过物理验证筛选——这种思路在某种程度上模拟了人类学习实验操作的过程:先学基本手法,再组合成完整实验,最后通过实践淘汰不合格的操作。这比简单地录制大量人类演示要高效和可扩展得多。
第三,知识隔离的精细化设计。 将视觉语言理解与物理控制解耦,让两种能力各自独立发展再融合——这体现了对多模态学习中"能力冲突"问题的深刻认识。在大模型领域,如何在不损害既有能力的前提下引入新能力,一直是核心挑战之一,LabVLA的知识隔离方案提供了一个值得借鉴的范式。
局限性与挑战
当然,LabVLA目前还面临一些明显的局限。首先,RoboGenesis依赖仿真环境,而实验室中的许多操作——比如处理生物样本的触觉反馈、试剂浓度的微妙变化——在仿真中很难精确模拟。Sim-to-Real的鸿沟在实验室场景下可能比家庭场景更为严峻。
其次,当前的工作主要聚焦于相对标准化的实验操作,对于那些需要即兴判断的开放式实验场景(比如观察到异常现象时如何调整方案),模型的应对能力还有待验证。
最后,4B参数量的模型是否足以应对真正复杂的实验推理?当一个实验方案涉及多个条件变量和复杂的逻辑分支时,更大的模型规模可能是必要的。
对领域的启发
LabVLA的意义远不止于一个基准上的SOTA结果。它代表了一种新的研究范式:不是简单地把通用模型"搬"到新领域,而是从数据源头、训练策略到评测体系进行全栈式适配。 这种思路对于其他需要AI进行精密物理操作的领域——手术机器人、半导体制造、精密装配——同样具有借鉴价值。
更进一步想,如果AI真的能够自主执行实验方案,那"假设生成-实验设计-物理执行-结果分析"的完整科学闭环就可能被打通。这将从根本上改变科学研究的生产力范式——不是替代科学家,而是让科学家从重复性的benchwork中解放出来,把更多精力投入到真正需要创造力的科研思考中。
总结
LabVLA是首个系统性地将VLA模型适配到科学实验室环境的工作,填补了"AI推理强、物理执行弱"的关键空白 RoboGenesis数据引擎通过"原子技能组合+物理验证过滤"的流程,以可扩展的方式解决了实验室训练数据匮乏的核心难题 两阶段训练策略(FAST预训练+流匹配后训练)和知识隔离机制,实现了语言理解与物理控制能力的优雅融合 在LabUtopia基准上,LabVLA在分布内和分布外设置下均取得最高成功率,展现出可靠的泛化能力 这项工作为"全自动化科学实验室"的愿景迈出了关键一步,其系统性的方法论对其他精密操作领域同样具有参考价值
本文基于 LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories[1] 解读。
引用链接
[1]LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories: https://arxiv.org/abs/2606.13578
