 夜雨聆风
夜雨聆风引言:随着大模型技术飞速迭代,具备自主思考、工具调用、循环执行能力的AI智能体,已经走向了大规模的产业应用。从企业办公自动化、数据库运维、代码开发,到智能客服和垂直领域的专属作业机器人,Agent正在替代大量重复性、流程化的人工工作。
但在落地实践中,几乎所有团队都面临同一个灵魂拷问:我们该如何科学、客观、全面地评估一个AI智能体的真实能力?
很多团队目前的评估现状是:“人工肉眼试用、凭主观感受打分”。运行顺畅就是“神级应用”,偶尔出错就是“能力不足”,效果不好就盲目去微调大模型。这种“盲人摸象”式的粗放评估,存在极大的随机性和片面性。它既无法精准定位Agent的短板在哪里(是规划出错?工具调用失败?还是上下文理解偏差?),也无法量化每次迭代的真实效果,更不可能支撑智能体走向规模化商业落地。
一个真正合格的AI智能体,绝非“能运行即可”。它需要在执行准确率、流程规范性、场景适配性、稳定性和容错性等多个维度达到严苛的标准。想要摆脱主观评判的误区,就必须依托最优实践,搭建一套系统化的评估流程。
在这里,老码农尝试深度拆解业内可直接落地的六步AI智能体评估方法。从标准定义到框架搭建,全流程拆解细节,让迭代有据可依。
第一步:明确核心目标——定义清晰、可落地的评估标准

评估工作的核心前提,是先回答一个问题:“什么是成功的执行效果?”如果标准模糊、笼统、“凭感觉”,后续所有的评测工作都是在堆砌无效数据。从主流实践来看,智能体的评估标准必须摒弃单一维度,分为“结果目标”与“过程目标”两大维度,才能全方位还原其真实作业能力。
1. 结果目标:只看最终业务产出(黑盒评估)
结果目标聚焦于Agent交卷后的“最终答案”,核心是判断任务是否真正完成、产出是否符合业务规范,例如:
数据库运维Agent:不看它怎么查的,只看最终数据库条目是否按要求创建?字段信息是否准确?有无冗余数据?
代码开发Agent:不看它改了几次,只看最终输出的代码能否编译通过?能否正常运行实现预设功能?
办公自动化Agent:只看最终生成的报表数据是否准确?格式是否符合公司规范?
结果目标最大的优势是绝对的客观性与可量化性。它不会因为评测人员的不同而产生评判偏差,是当前行业各类智能体评测基准(如AgentBench、ToolBench)的核心考核指标。
2. 过程目标:核验执行流程规范性(白盒评估)
仅仅考核结果,会留下巨大的评估漏洞。有些Agent可能凭借大模型的“玄学”运气蒙对了答案,但执行流程一塌糊涂:工具调用顺序错乱、中间步骤大量缺失、甚至出现了违规的危险操作。虽然结果碰巧达标,但稳定性极差,换一个稍微复杂的场景就会彻底崩溃。
过程目标主要针对智能体的完整执行日志进行核验:
是否按照业务SOP调用了指定工具?
调用顺序是否合乎逻辑?
是否存在无效调用(比如反复查询同一个接口)或冗余操作?
【实操案例】一个数据查询Agent,最终成功输出了目标数据。但在审查Transcript(执行日志)时发现,它错误调用了3次无关的删除工具,重复发起了5次查询才凑巧命中。这是典型的“结果合格、过程不合格”。如果忽略过程评估,一旦上线,高昂的资源消耗和极低的响应速度将直接拖垮系统。
第二步:循序渐进——搭建动态迭代的小型评测任务集

在开展评估时,很多团队容易陷入“大而全”的囤积癖:一开始就耗费几个月时间,准备几万条评测数据。结果发现大量任务冗余,评测跑一轮要几天,效率极低。
优质的评估体系,从来不是一蹴而就的,而是“小样本起步 -> 动态迭代 -> 持续优化”的飞轮。
1. MVP(最小可行性)任务集启动初期不需要海量数据,只需手动筛选、精心打磨一批高质量、高代表性的小型任务集(比如50-100条)。这批任务只需覆盖Agent的核心业务场景和基础功能模块,目的是快速跑通评估流程,低成本验证基础能力。
2. 建立“Bug-to-Test”转化机制评估体系的核心价值在于“持续适配”。在日常使用或内测中,只要发现Agent执行失败、结果偏差、流程异常,第一时间完整记录故障场景和触发条件,并将其“一键转化”为新的评测任务,补充进任务库。
3. 划分回归测试集随着任务库扩容,必须遵循“优胜劣汰、难度升级”的原则。特别要注意的是,早期那些用来验证基础能力、或者曾经让Agent栽过跟头的经典任务,不能随便删掉,要把它们统一归入“回归测试集”。
每次Agent升级模型或修改代码后,必须先跑一遍回归测试集,防止出现“修复了旧Bug,引入了新Bug”或“高级能力提升了,基础能力却退化了”的灾难性后果。
第三步:精细打磨——设计高精准、高稳定的优质评测任务

评测任务是评估能力的核心载体。任务质量差,评估结果就是垃圾进、垃圾出(GIGO)。很多团队评估结果失真,根本原因就在于任务设计不规范、存在歧义。
优质评测任务的唯一标准:结果一致性。即:无论在何时、由谁发起评测,只要使用同一任务、同一环境、同一Agent版本,得出的评测结果必须100%一致。
【反面案例:劣质任务】
“帮我查一下最近销售情况不好的原因,并整理个报告。”问题所在:极度模糊!“最近”是几天?“销售情况不好”的具体量化标准是什么(下滑5%还是20%)?报告需要什么格式(PPT还是Word)?这种任务会让Agent每次执行都靠“抽卡”,评测结果完全不可复现。
【正面案例:优质任务】
“调用SalesDatabase工具,查询2023年Q3(7月1日-9月30日)华东区所有SKU的销售总额。筛选出销售额环比Q2下降超过15%的SKU清单。将清单按降幅从大到小排序,以CSV格式输出,包含字段:SKUID、名称、Q2销售额、Q3销售额、降幅百分比。”
优势所在:需求清晰、边界明确、工具指定、格式统一。不管跑多少次,只要Agent能力达标,输出的CSV结构绝对一致。这就排除了所有外部干扰,精准测试Agent的工具调用与数据排序逻辑。
在任务设计环节,必须建立严格的“走查审核机制”,剔除所有表述模糊的劣质任务,确保每个任务都像一把精确的手术刀,专门用来测试Agent的某一项具体能力。
第四步:科学判定——分层配置多元化评测判定机制
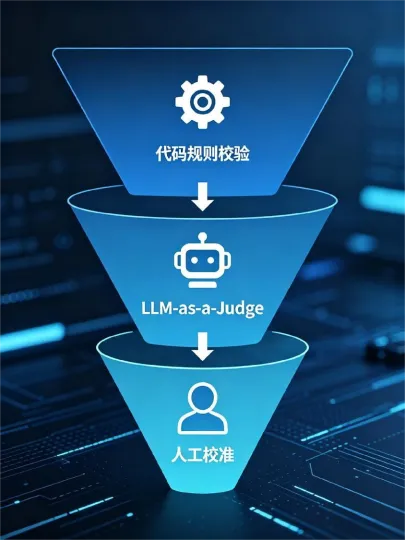
任务设计好了,谁来打分?这就是判定机制需要解决的问题。行业主流实践是采用“分层配置、软硬结合”的方式,兼顾效率与精准度。
第一层:硬判定(确定性校验)—— 能用代码决绝不用人对于可量化、标准化的场景,全部交给代码自动判定。* 校验内容:是否调用了指定工具?调用了几次?最终输出结果是否与标准答案完全匹配?格式是否合规?*优势:简单高效、零主观偏差、成本极低。可以一秒钟跑完上万条测试用例,是流程化Agent评测的绝对主力。
第二层:软判定(LLM-as-a-Judge)—— 让大模型评判大模型并非所有东西都能写死规则。比如:代码风格是否优雅?客服话术是否有同理心?文案逻辑是否严谨?这类主观场景无法用if-else判断。此时,行业通用的解法是引入一个能力更强、专门用于评测的大模型(如GPT-4o或Claude-3.5-Sonnet),给它设定极其详细的评分Rubric(评分量规),让它代替人工去打分。这比全人工评测效率提升了百倍。
第三层:人工校准—— 守住评测底线大模型评判存在“幻觉”和“偏好偏差”(比如它可能倾向于给长篇大论的回答打高分)。因此,必须建立“人类专家抽检校准”机制。业务专家需要定期抽样复核LLM Judge的打分结果。如果发现大模型的评分与人类专家的共识偏离超过阈值,就必须立即调整评测大模型的Prompt或评分规则。LLM Judge+ 人工校准,才是主观评测的正确闭环。
第五步:搭建底座——构建高效可复现的标准化评测框架

标准、任务、判定机制都齐了,把它们装在哪里?很多团队的评测之所以无效,是因为“每次跑测试的环境都不一样”。测试环境的一点点缓存残留、工具接口版本的细微差异,都会导致结果天差地别。
因此,必须搭建专属的智能体评测框架,作为全流程的技术底座,它必须具备以下三大核心功能:
1. 全真可控的场景沙盒评测框架必须能完美模拟线上真实生产环境,但又要与生产环境物理隔离。在这个沙盒里,工具权限、运行参数、网络延迟都要受到统一管控。坚决杜绝“测试环境一片大好,上线直接原地爆炸”的惨剧。
2. 全程无死角的日志采集这是排查Agent问题的“黑匣子”。框架必须自动记录Agent的每一次心跳:包括大模型的Token消耗、每一次工具调用的入参出参、每一步的中间思考过程、耗时与报错信息。没有完整的Trace链路,问题排查就是瞎子点灯。
3. 自动化的结果聚合与可视化跑完评测,不能只给出一堆干瘪的日志。框架需要自动抓取成功率、失败率、平均耗时、各类错误类型的分布占比,直接生成可视化的评测报告,让产品经理和技术人员一眼看出瓶颈所在。
核心:环境重置机制每一次评测任务开始前,框架必须强制重置一个全新的独立运行环境。清空上一轮的所有缓存、会话状态和历史数据。绝对不能让上一次测试的“残留记忆”污染下一次测试,从根源上保障可复现性。
第六步:持续迭代——打造动态进化的长效评测基准体系

这是最容易被人忽视,却也是决定评估体系生命周期的一步。评测基准绝对不是一件“做完了就锁进柜子”的一次性纪念品。
警惕“评测饱和”现象AI智能体的迭代速度极快。随着模型微调和Prompt优化,Agent很快就会把原有的基础评测任务“吃透”。这时候你会看到,评测报告上永远是95%以上的高分,全部显示绿色通过。这意味着什么?意味着你的评测基准失效了。它已经无法区分Agent到底是一般优秀还是极其优秀,也无法再暴露出深层次的边界问题。这就好比让大学生天天做1+1=2的题,测不出他的真实学术水平。
让基准体系“活”起来专业的评测体系,必须被视为“动态生长的资产”。1.持续投喂边界案例:从线上真实的极端用户反馈、复杂长尾场景中提取任务,不断增加任务的“刁钻程度”。2.定期清理与降级:对于那些Agent连续10个版本都能100%秒过、毫无挑战性的陈旧任务,可以降级为“日常巡检任务”,不必每次发版都全量跑,节省算力。3.复盘评测体系本身:每季度审视一次:我们的评测规则还贴合现在的业务吗?LLM Judge的打分还准吗?环境配置有没有滞后?
通过常态化的维护,让评测体系的难度始终略高于Agent当前的能力水平,像一条不断扬起的鞭子,持续抽打和引导Agent向更高阶的能力进化。
小结
AI智能体的竞争是拼“迭代能力与落地稳定性”。标准化、系统化、可迭代的评估体系,就是智能体规模化落地的“压舱石”。没有科学的评估,技术团队的所有微调和重构都是盲人摸象式的试错;没有动态的评测体系,产品经理所谓的“版本升级”就只是一句缺乏数据支撑的空话。
从定义清晰标准,到搭建动态任务集;从设计高质任务,到分层判定机制;再到构建评测框架与持续迭代基准——这六步法构成了AI智能体评估的完整闭环。
对于每一家致力于将AI真正转化为生产力的企业而言,评估即产品。把评估体系本身当成一个核心产品去打磨,短期可以快速定位问题、砍掉无效的试错成本;长期则能沉淀为企业独家的评测资产与数据护城河,让AI智能体真正从“勉强能用”跨越到“稳定好用、专业可靠”。
ps,作译互助群图书推荐——
【关联阅读】
