当前时间: 2026-06-14 21:43:08
分类:办公文件
评论(0)
用闭环记忆优化增强软件工程智能体论文基本信息:Guo, X., Wang, Z. Z., Wang, Q., Neubig, G., & Wang, X. (2026). Enhancing Software Engineering Through Closed-Loop Memory Optimization. arXiv preprint arXiv:2606.05646.论文链接:https://arxiv.org/abs/2606.05646作者单位:William & Mary,CMU,OpenHands, UIUC当前的软件工程agent能够自主浏览代码库、理解复杂需求,并在不断演化的工程环境中实现跨文件、跨函数的解决方案。然而,这些agent存在一个根本性缺陷:它们本质上是"情景式"(episodic)的:无法在不同任务之间保留、提炼与复用经验。如何解决这一问题?这篇来自OpenHands团队的最新论文给出了一个基于记忆系统的改进方案。1. 引言
在软件工程场景中,代码库持续演化,大量任务共享项目特有的约定、调试模式与架构约束。然而每次面对仓库级问题,agent都要从零重建上下文、重新探索代码结构、重复无效的实现策略,并反复犯下相似的错误。问题的症结在于缺少能够把经验持续提炼为可复用知识的“原则化记忆机制(principled memory mechanisms)”。更关键的是,作者指出:简单地为智能体"加上记忆"并不能解决问题。现有记忆增强方法缺乏一个通用且原则化的"记忆效用"(memory utility)定义——它们能够存储、检索或总结过往经验,但某条记忆是否真正提升了下游表现、这一判断能否跨任务与跨智能体迁移,始终模糊不清。结果是,记忆设计往往依赖任务特定的启发式规则、复杂的记忆架构,以及人工专家来决定"记什么、怎么精炼",难以被严格评估、有效优化或迁移。针对上述痛点,作者提出MemOp,一个面向 SE 智能体的闭环记忆优化框架,其核心创新有两点:将memory utility作为"双重工具"(dual harness):MemOp 把记忆效用锚定在经过验证的下游影响上——当且仅当一条记忆能切实提升 SE 智能体在下游任务上的表现时,它才是有用的。这一以结果为依据的定义同时承担两个角色:既是用于严格、任务无关的评估基准,又是无需人工标注即可驱动优化的优化信号。闭环记忆优化:MemOp 实现了无需外部监督的闭环训练,通过反思从已完成的轨迹中蒸馏候选记忆,再通过性能验证将每个候选轨迹转化为训练信号。2. 方法:记忆增强
2.1 问题形式化:
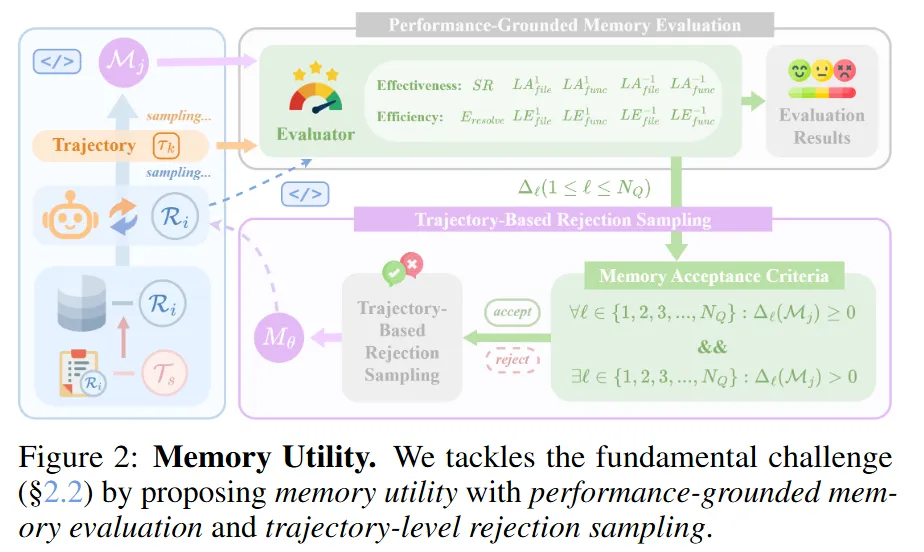
设 agent在仓库 R 上求解第 k 个任务 Tk,通过一系列动作(代码导航、文件读取、命令执行、函数修改等)与环境交互,产生一条"问题求解轨迹"。MemOp 为智能体引入一个可演化的记忆状态 Mk,存储在Memory.md 中,用以提炼经验、辅助未来任务。部署时分两个阶段运行:一是反思式记忆演化,由专门的记忆模型 Mθ 对完成的轨迹进行反思以更新记忆;二是记忆增强执行,在求解下一个任务时为智能体装配最新记忆,从而引导更高效的导航、推理与求解。2.2 Memory Utility:不起作用即不计数。
这是本文提出的关键概念:一条候选记忆被选定为高质量,当且仅当它在所有指标上都不劣于无记忆基线,且至少在一个指标上严格优于基线,如图2所示。不满足该准则的候选被拒绝。这一准则身兼评估基准与优化信号两职。3. 方法:基于性能验证微调的记忆优化
3.1 度量记忆效用。作者设计了一套系统的评估指标,覆盖智能体求解的有效性与效率两个维度,共构成 10 个多维度指标,包括:成功率(SR)、定位准确率(LA,区分文件级/函数级、首次成功/完全成功)、解决效率(E_resolve,衡量节省的迭代比例)以及定位效率(LE)。性能差异以绝对差(∆abs)与相对差(∆rel)刻画。
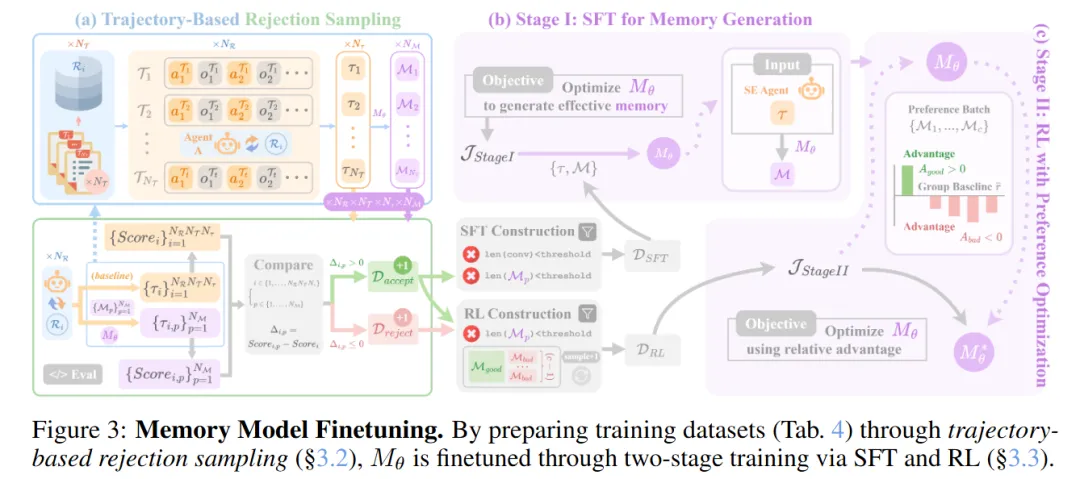
3.2 构建性能验证的训练数据。作者提出基于轨迹的拒绝采样:在从 SWE-Bench-Verified 随机抽取的仓库与任务上,让智能体多次 rollout,每条轨迹生成多个候选记忆,再用上述接受准则将候选分入"接受集"与"拒绝集",从而得到两阶段训练所需的数据集。
3.3 两阶段训练记忆模型。第一阶段通过监督微调,让 Mθ 从智能体轨迹中习得基础的记忆生成能力;第二阶段通过带偏好优化的强化学习,以"记忆带来的实际性能提升"作为奖励,进一步把 Mθ 推向能够生成高质量记忆——奖励直接源自下游结果,奖励有益记忆、惩罚冗余或有害记忆。
3.4 两类评估范式。一是单情景记忆生成:从单条轨迹蒸馏记忆并立即复用,验证记忆生成本身的质量;二是跨情景记忆演化:随智能体不断积累经验而渐进精炼记忆,验证其适应性与稳健性。
4. 实验结果
作者使用两个模型进行实验评估:Devstral-Small-2507和Qwen3-Coder-30B-A3B,并微调了六个不同规模的记忆模型(涵盖 Qwen2.5、DeepSeek-R1蒸馏版与 Qwen3 系列),在SWE-Bench_verified上进行训练和评估。实验结果表明:单情景设置。MemOp 增强的智能体在十项指标上持续优于无记忆基线,成功率绝对提升最高达↑5.25%,解决效率提升最高达↑4.63%;多数微调后的记忆模型甚至超过了直接用 Claude-4-Sonnet 生成记忆的效果。值得注意的是,未经微调的记忆模型(NFT)反而持续拉低性能,说明若无 MemOp,基座模型本身不足以胜任有效的记忆增强。跨情景设置。MemOp 同样稳定带来增益,成功率绝对提升最高达↑3.00%、定位准确率最高达↑3.17%。跨情景演化本身更具挑战,因为 Mθ 需要判断哪些信息应跨情景保留共享、哪些需要更新;NFT 在此设置下退化更明显,而 MemOp 展现出良好的适应性。泛化能力与成本。MemOp 在不同agent模型与记忆模型、不同代码仓库以及不同 RL 算法(GRPO、DAPO、GSPO)上均稳定有效,表明其与算法无关、可即插即用;与此同时,计算成本显著降低≥9.79%。两个训练阶段(SFT 与 RL)各自独立带来增益,且两者联合效果最佳,体现互补作用。5. 深入分析
在失败模式分析中,作者手工分析了 50 条失败轨迹,归纳出七类典型失败原因,其中"对仓库结构的误解"是首要原因,"长上下文推理中的重复"次之。在记忆结构研究中,作者对比九种表示方式(字符串、字典、列表、树、图、Python代码、预定义层级格式、模型自定义层级格式、和本文采用的层级化Memory.md),发现结构化程度更高的格式(如字典、Python 代码)收益显著,而 MemOp 采用的基于 Markdown 的层级化Memory.md表现最佳,由此提炼出一条设计原则:对智能体越易理解的记忆结构,效果越好。6. 总结
MemOp 的核心贡献,在于把agent的"记忆质量"从一个含糊的属性转化为可度量、可优化的指标:通过将memory utility锚定到真实的下游软件工程任务中,它同时提供了原则化的评估基准与无需标注的优化信号,从而闭合了"记忆生成—记忆质量"之间的回路。实验在单情景与跨情景设置下均显示出一致增益,并伴随计算成本的下降。本文可看做是AI社区对软件工程agent记忆机制的典型研究,关注核心不在agent自身的结构,而是使用了监督微调、强化学习等模型训练技术。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-06-14 21:44:00 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/752490.html
- 运行时间 : 0.142031s [ 吞吐率:7.04req/s ] 内存消耗:4,741.71kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=5e90ea995f269d30bef70c816fe02f34
- CONNECT:[ UseTime:0.000962s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.001331s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000624s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000564s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.001072s ]
- SELECT * FROM `set` [ RunTime:0.000417s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.001210s ]
- SELECT * FROM `article` WHERE `id` = 752490 LIMIT 1 [ RunTime:0.002569s ]
- UPDATE `article` SET `lasttime` = 1781444640 WHERE `id` = 752490 [ RunTime:0.031683s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000699s ]
- SELECT * FROM `article` WHERE `id` < 752490 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.000997s ]
- SELECT * FROM `article` WHERE `id` > 752490 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.000872s ]
- SELECT * FROM `article` WHERE `id` < 752490 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.002770s ]
- SELECT * FROM `article` WHERE `id` < 752490 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.004310s ]
- SELECT * FROM `article` WHERE `id` < 752490 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.005262s ]

0.143820s

 夜雨聆风
夜雨聆风