 夜雨聆风
夜雨聆风点个关注,带你了解具身智能最新进展!
AI 已经能读论文、找文献、写实验方案,甚至帮研究者提出假设。
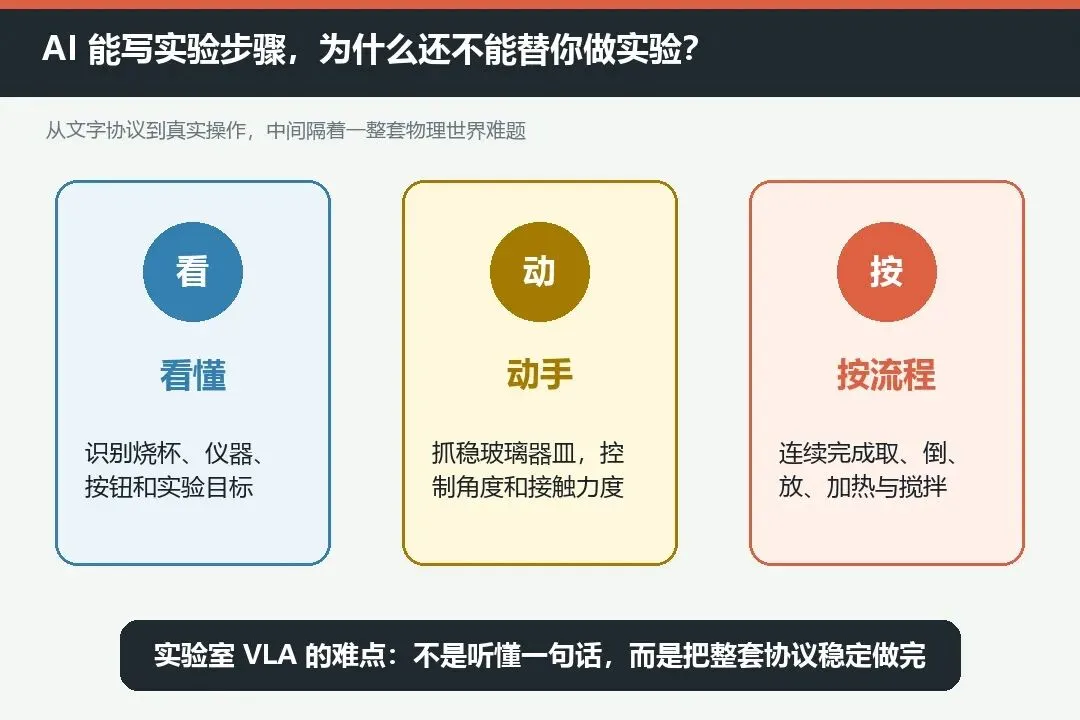
但到了真正的实验台前,事情突然又变回了人工:拿起烧杯、打开设备门、按下按钮、加热、搅拌,再把液体稳稳倒进另一个容器。
文字里的“转移液体并加热”只有一句话。机器人真正执行时,却要连续处理玻璃器皿、透明液体、接触力、倾斜角度、仪器位置和严格的先后顺序。
这正是浙江大学、上海人工智能实验室和哈尔滨工业大学等团队最新技术报告 LabVLA 想解决的问题:能不能让视觉—语言—动作模型不只看懂实验方案,还能在实验室里把它做出来?
SECTION 01
家务机器人会抓杯子,为什么进实验室就不灵了?
现在的大多数 VLA 模型,主要从家居、桌面抓取和日常物体操作中学习。它们见过玩具、抽屉、碗盘,却很少见到磁力搅拌器、加热板、试管塞和透明液体。
实验室操作还有一个更麻烦的特点:它不是“抓到就算成功”。
机器人必须按照固定协议完成一连串动作。少做一步、顺序错误、容器没放稳,整个实验都可能失效。换句话说,实验室需要的不是一次漂亮的抓取,而是把整套流程稳定地做完。
论文把这种能力放进 LabUtopia 仿真基准,用六类任务检验模型:加热烧杯、打开设备门、抓取物体、倾倒液体、按下按钮和搬运烧杯。
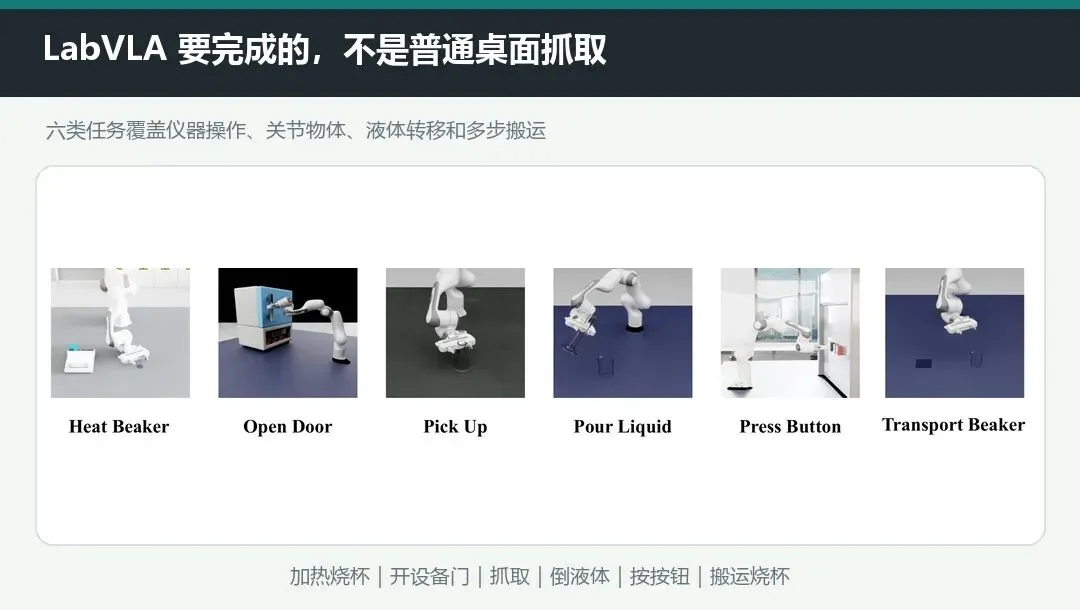
这里既有按钮这种接近“看见就按”的任务,也有倒液体这种需要持续控制角度、位置和稳定性的任务。难度差异,恰好能暴露模型究竟只是会识别物体,还是已经学会了实验操作。
SECTION 02
先别急着造模型,实验室机器人真正缺的是数据
团队没有直接把通用机器人数据丢给模型继续训练,而是先做了一套名为 RoboGenesis 的数据引擎。
它做的事情很像自动化实验室的“数据工厂”。
第一步,把烧杯、仪器、工作台和通道组合成可执行的实验环境,并检查空间是否真的可达。
第二步,把一句实验协议拆成原子技能。比如“转移液体并加热”,会被拆成抓取、倾倒、放置、按键等动作,再由不同机器人形态执行。
第三步,在仿真中真正跑起来。碰撞、失败或无法完成的轨迹会被过滤,不会因为“看起来合理”就进入训练集。
最后,成功轨迹会连同子任务、物体状态、相机信息、空间关系和动作一起导出,形成 LabEmbodied-Data。

这一步的价值不只是“数据更多”。它把实验协议和机器人的连续动作对齐了。
论文报告,即使是超过 20 个技能步骤的复合流程,数据收集成功率仍能保持在 75% 以上。这意味着复杂协议不必全部依赖人类逐条遥操作示范,至少可以先在仿真中批量生成和筛选。
SECTION 03
LabVLA 怎么学会“动作语言”?
LabVLA 的视觉语言骨干是 Qwen3-VL-4B-Instruct,后面连接一个 DiT 动作专家。训练分成两个阶段。
第一阶段使用 FAST,把连续机器人动作编码成离散 token。
你可以把它理解成先给模型补一门“动作语言课”:在要求它输出精确轨迹之前,先让视觉语言模型知道,一条自然语言指令通常对应怎样的动作结构。
第二阶段再使用 Flow Matching 学连续控制。
动作专家从随机噪声出发,逐步把它变成平滑的动作片段。模型最终输出的不是“向左、向右”这样的粗粒度标签,而是机器人可以执行的一段连续轨迹。
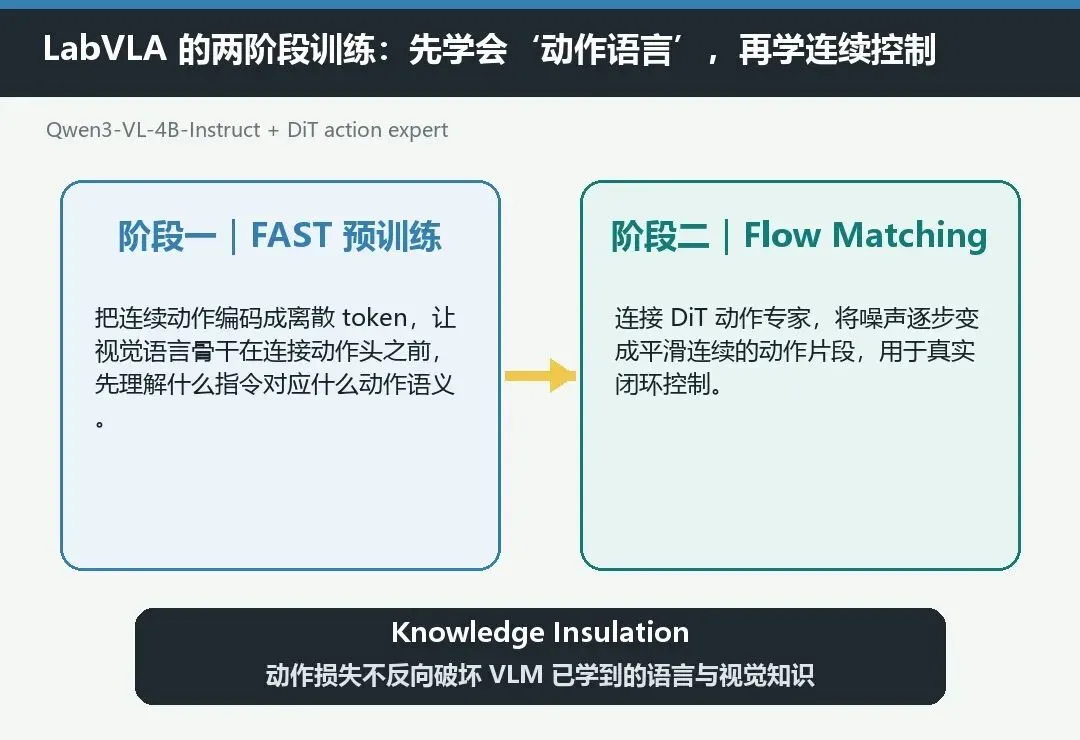
这里还有一个很关键的设计:Knowledge Insulation,知识隔离。
如果动作损失直接反向更新整个视觉语言骨干,模型为了适应控制任务,可能破坏原来已经学到的语言和视觉能力。LabVLA 因此阻断 Flow Matching 梯度进入 VLM 前缀,同时保留 FAST 与标注任务对视觉语言骨干的训练。
通俗地说,就是让“动作专家”专心练手,又不让它把模型原本会看的、会读的知识练坏。
SECTION 04
关键公式:它如何把噪声变成机器人轨迹?
论文中最值得理解的公式有两组。
第一组定义 Flow Matching 的路径。Xτ 是噪声 ε 与真实动作片段 Ã 的线性插值:τ 从 0 走向 1 时,输入便从高斯噪声逐渐靠近真实动作。Uτ 则给出这条路径应学习的速度方向。
第二组是 Knowledge Insulation 下的联合训练目标。它同时包含 Flow Matching 动作损失、FAST 动作 token 损失和若干标注交叉熵损失,其中动作损失权重 α 设为 10。
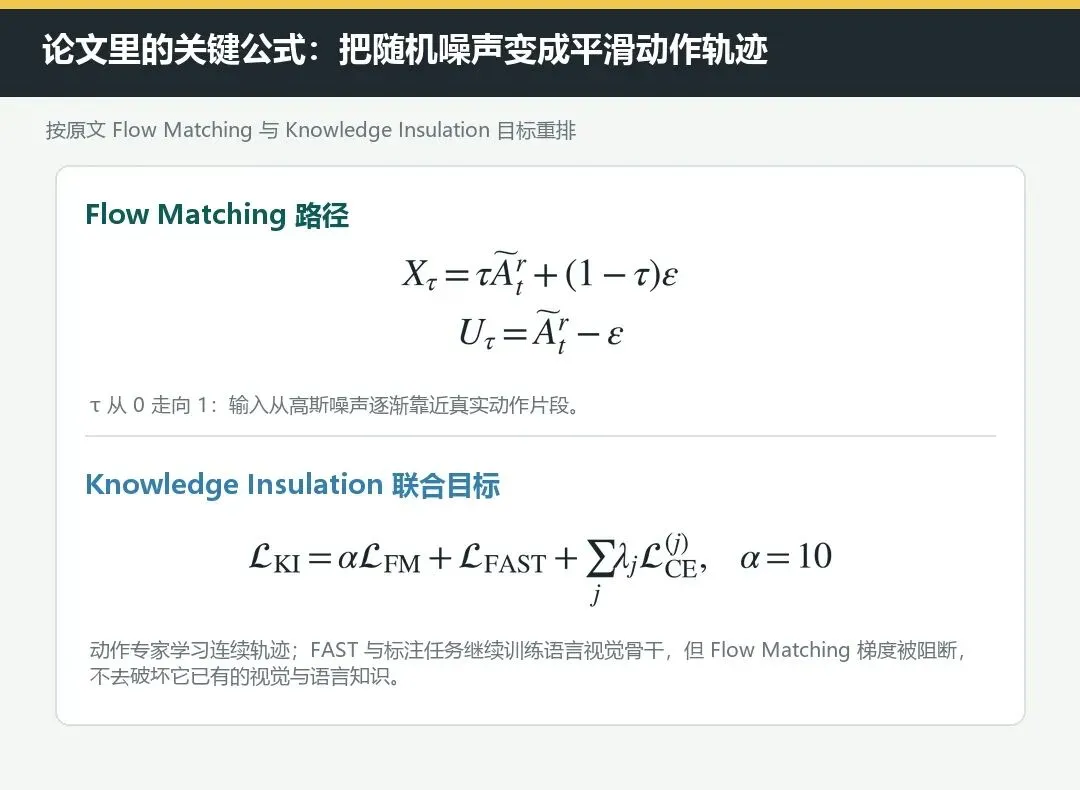
这两组式子合在一起表达了一件事:模型既要把连续动作学准,也要保住视觉语言骨干对指令、物体和场景的理解。
公式并不是额外发明一种神秘的新数学,而是把成熟的 Flow Matching 与动作 token 预训练重新组合到实验室 VLA 中。真正有用的是这套训练次序与梯度隔离方式。
SECTION 05
结果最亮眼的地方,不只是平均分第一
在 LabUtopia 的六类任务上,每个设置、每类任务测试 120 个 episode。
LabVLA 的六任务平均成功率达到:
分布内 ID:71.1%
分布外 OOD:70.0%
作为对比,次优的 π0 分别为 63.3% 和 63.2%。LabVLA 高出 7.8 和 6.8 个百分点。
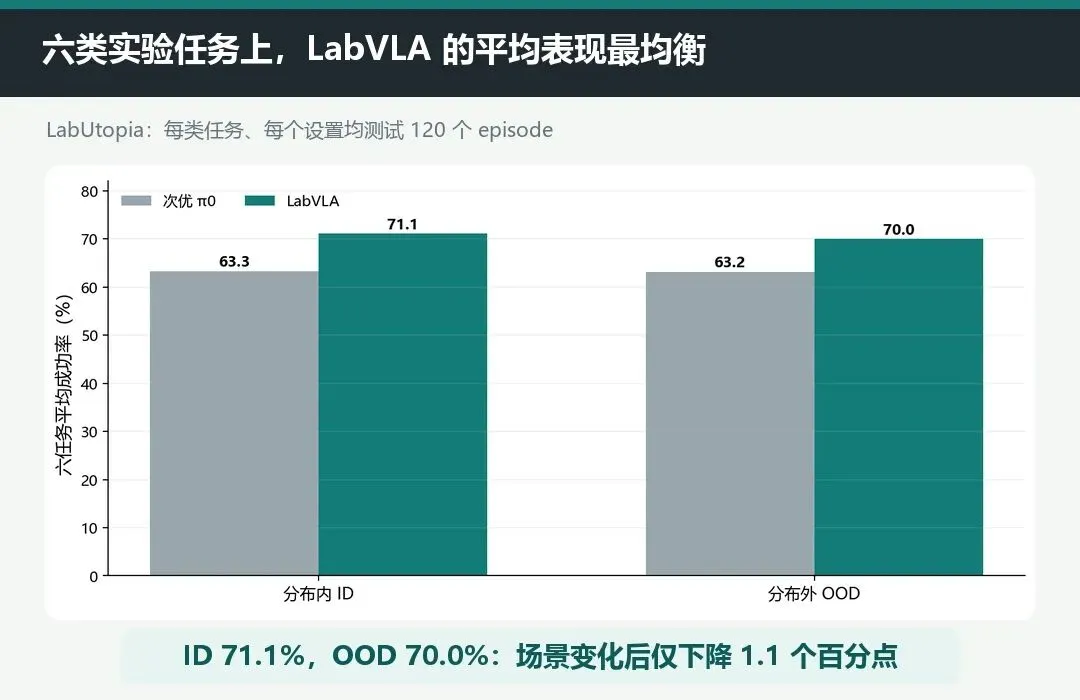
更值得注意的是,模型从 ID 到 OOD 只下降了 1.1 个百分点。
这并不等于它已经能适应任意新实验室,但至少说明:场景、位置或物体发生变化后,它没有立刻失去操作能力。
SECTION 06
换一个模型,数据仍然有效
为了确认提升并不是 LabVLA 架构“自说自话”,团队把同一份 LabEmbodied-Data 用在外部模型 X-VLA 上。
结果很清楚:五类非饱和任务的平均成功率,ID 从 49.3% 提高到 64.3%,增加 15.0 个百分点;OOD 从 43.7% 提高到 63.0%,增加 19.3 个百分点。
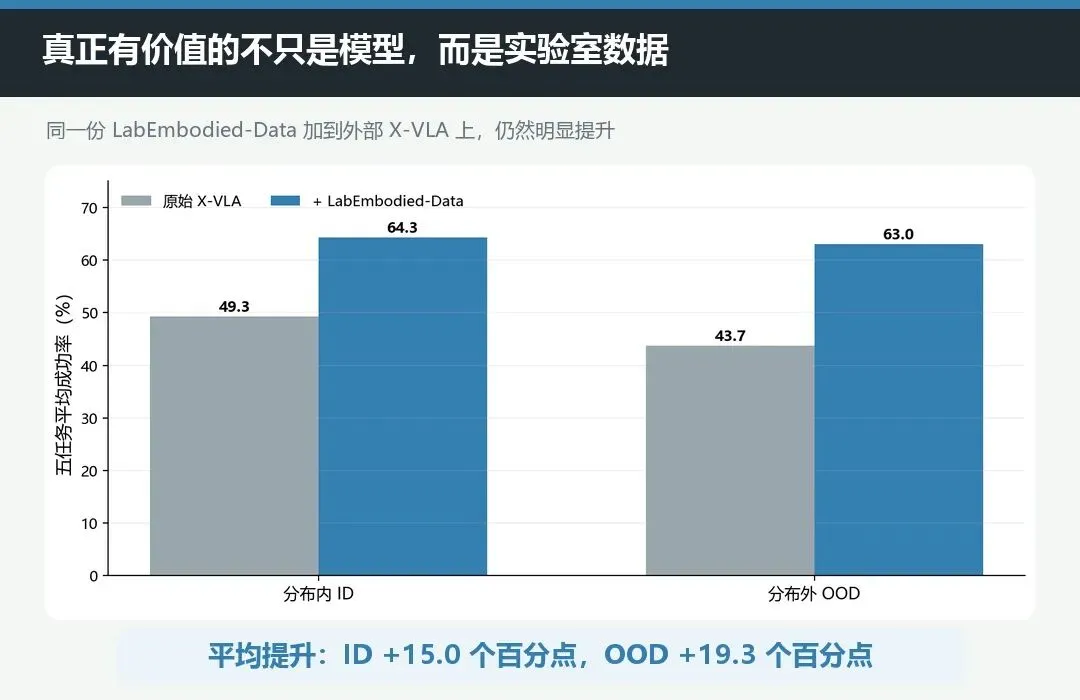
这组实验甚至比“LabVLA 平均分第一”更重要。
它说明团队造出的实验室数据并不只服务于一个模型。对这个方向而言,可迁移的数据资产可能比某一版网络结构更有长期价值。
SECTION 07
机器人真的被搬到了实验台前
论文还把 LabVLA 部署到真实 Franka 机械臂上,测试摇匀液体、倾倒液体、磁力搅拌和试管塞插拔四类任务。
每个设置进行 50 次 rollout,并同时测试干净与杂乱工作台、分布内与分布外位置。
LabVLA 四任务平均成功率为:干净 ID 86.5%,干净 OOD 80.0%,杂乱 ID 80.0%,杂乱 OOD 74.0%。
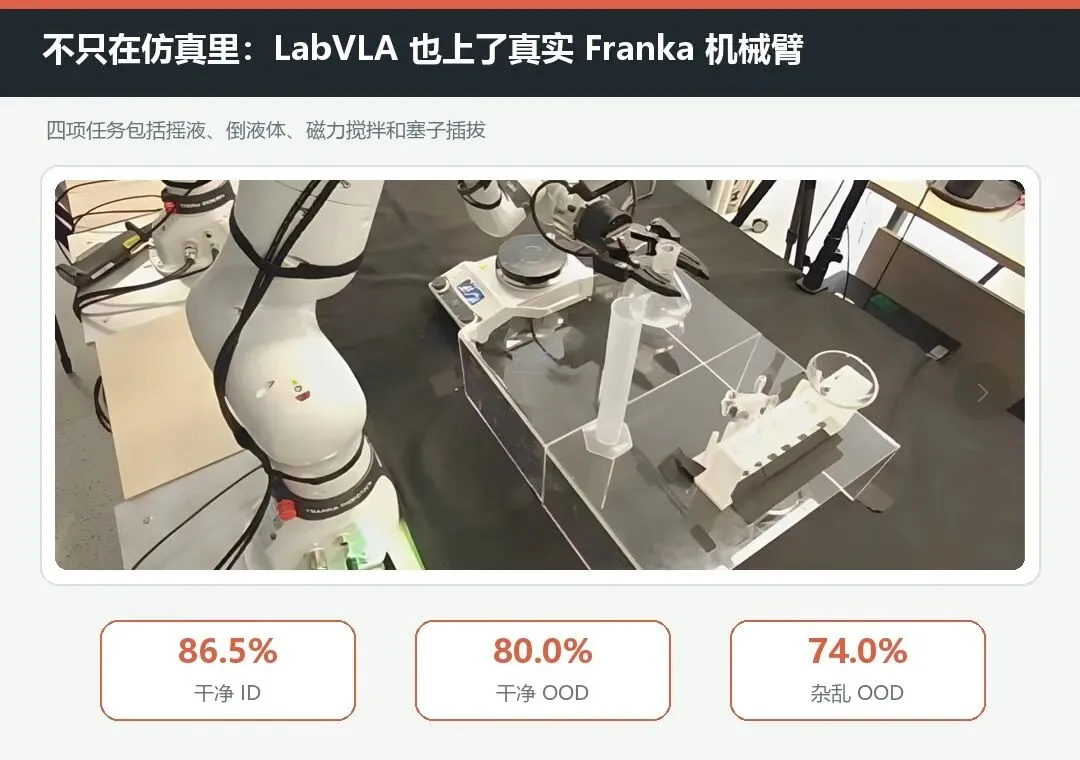
这证明仿真预训练确实可以迁移到真实实验台,但结果也需要冷静看待。
在杂乱环境中,DreamZero 的平均表现略高于 LabVLA;真实机器人实验也只覆盖一台 Franka 和四类台面任务。它更像一项可信的可行性验证,还不是可以直接部署到化学实验室的通用系统。
SECTION 08
最不会骗人的短板:倒液体依然很难
如果只看平均分,很容易错过这篇论文最有意思的部分。
按按钮几乎已经饱和,LabVLA 在 ID/OOD 中达到 100% 和 98.3%。但在仿真倒液体任务上,成功率只有 ID 43.3%、OOD 34.2%。

原因并不难理解。
倒液体要求机器人持续控制倾斜角度,保持容器抓握稳定,还要应对位置偏移、遮挡和液面难以观测的问题。任何一个小误差都会沿着长动作序列不断放大。
这也划出了当前系统的边界:LabVLA 已经开始像实验室技术员一样执行固定协议,但它还不能像科学家那样观察实验结果、判断异常、修改方案并重新设计实验。
论文自己也把系统定位在 Level 2“Technician”,而不是能够自主发现和验证知识的“Scientist”。
SECTION 09
这篇工作真正推进了什么?
它没有证明机器人已经可以替代实验员,也没有解决所有长流程操作。
它推进的是一条相当具体的路线:
用可编程仿真系统生成实验室专用数据;用动作 token 让视觉语言模型先理解动作语义;再用连续生成模型输出机器人轨迹;最后把仿真能力迁移到真实实验台。

这条路线的意义在于,AI for Science 不再只停留在“读、写、想”。它开始尝试补上最难自动化的一环:真正伸手去做。
不过,这项工作目前是 2026 年 6 月发布的 arXiv 技术报告,作者明确标注为 work in progress。多数验证仍在仿真中,真实硬件测试规模有限,液体操作和更长流程也远未解决。
所以,更准确的结论不是“AI 科学家来了”,而是:机器人终于开始学着把写在实验方案里的那句话,变成实验台上真正发生的一连串动作。
论文信息:
LabVLA: Grounding Vision–Language–Action Models in Scientific Laboratories
作者:Baochang Ren、Xinjie Liu、Xi Chen 等
机构:浙江大学、上海人工智能实验室、哈尔滨工业大学
状态:arXiv 技术报告 / work in progress,2026 年 6 月 11 日提交
论文:https://arxiv.org/abs/2606.13578
项目:https://zjunlp.github.io/LabVLA/
代码:https://github.com/zjunlp/LabVLA
你更期待机器人先接管哪一种实验操作:移液、配液、加热、搅拌,还是长流程样品制备?
