 夜雨聆风
夜雨聆风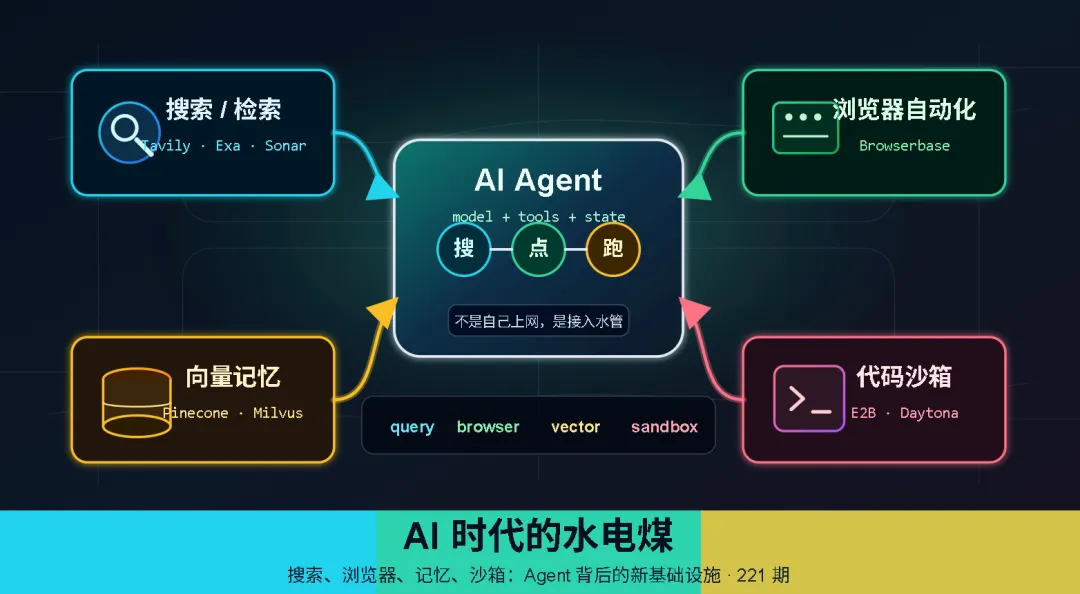
━━━━━━━━━━━━━━━━━━━━
◆ 起因:一次让我愣住的配置
━━━━━━━━━━━━━━━━━━━━
先说背景。我日常用的是御三家的官方 agent:Claude Code、Codex(OpenAI)、Gemini CLI——它们都自带"联网"开关,开了就能用,从来没让我配过什么搜索 API。所以过去一年我潜意识里以为,"AI 能上网"是一件理所当然的事——大模型自己接 Google,我管它后端怎么转的。
直到前几天试用一个叫 Hermes 的 agent 工具,配的是字节豆包大模型。装完启动,弹出一个对话框:"请配置搜索引擎"。
我下意识以为是让我在 Google 和百度之间二选一——选完它就帮我搜。结果点进去看:默认选项是 Firecrawl,下面的下拉里还有一长串——Tavily、Exa、SerpAPI、Brave、Jina Reader、Perplexity……一个都不认识。
愣了一下:御三家自己搞掂的事,第三方 agent 怎么就要我亲手从一整个货架上挑一家陌生公司的 key?豆包就豆包,我让它"搜一下 xxx",它为什么不直接 Google 或者百度?
先把读者最关心的问题答了:这些服务对个人用户基本免费。我去 Firecrawl 注册那个 key 的时候,免费档 1000 页/月,不要信用卡。一会儿你会看到,几乎整条 agent 基础设施栈对个人玩家都是这个调子——能这么从容免费玩,恰恰是这门生意整体设计的一部分。
但调子背后,是一整层在过去一年闷声起飞的赛道——AI agent 时代的"水电煤"。它们不写一行 prompt,不训一个模型,但 Cursor 每帮你 vibe 一行代码、Claude Code 每搜一次文档、你那个不知名的 RAG 玩具每查一次资料,背后都有一串第三方 API 在转动。
最便宜的一个估值约 3 亿美元,最贵的一个估值约 22 亿美元,最快的那家一年时间从 A 轮到被收购,溢价 98 倍。
而绝大多数程序员(包括我),是直到配 key 那一刻,才知道这赛道存在的。
━━━━━━━━━━━━━━━━━━━━
◆ 为什么 AI 不能直接用 Google?
━━━━━━━━━━━━━━━━━━━━
我们先解决最朴素的疑惑:豆包、DeepSeek、GLM 这些大模型自己难道不能上网吗?为什么非要一个中间商?
答案分两层:能不能技术上做到 ≠ 能不能稳定做到。
直接抓 Google 这件事,到 2026 年已经基本走不通了。原因不是技术不行,是 Google 那头早就武装到牙齿:
- SERP 强制 JavaScript 渲染
你不跑浏览器就拿不到结果,类名两个月一变,2024 年的爬虫脚本到 2026 全部失效 - reCAPTCHA v3 + IP 信誉系统
根据"行为评分"识别非人类访问,datacenter 段 IP 直接拒绝 - Cloudflare 默认屏蔽 AI bot
2025 年开始对新域名默认拦截 AI crawler,并测试 Pay-Per-Crawl;截至 2025 年 8 月,250 万+ 网站已经通过 Cloudflare 的 managed robots.txt 或托管规则拒绝 AI training,79% 的头部新闻站至少屏蔽一个 AI bot
这还只是技术层。法规层更狠:
- 2025 年 8 月,微软关闭了 Bing 公共搜索 API
——这是给 AI 应用准备的最后一条"官方搜索通道",说没就没 - Google 起诉 SerpAPI
(一家专门抓 Google 结果转卖的公司),整个"搜索结果转售"赛道格局被迫重构 英国监管机构 2026 年要求 Google 必须允许新闻站"opt-out"——意思是新闻内容能不能被 AI 用、由新闻站自己说了算
💡 翻译成人话:搜索引擎是给人看的,不是给 agent 看的。 给人看的网页可以挂广告、收 cookie、装 JS、藏反爬机关;agent 进来这套全是负担。所以诞生了一个新的中间层——专门把"给人看的 web"翻译成"给 agent 吃的 web"。
这就是 Firecrawl、Tavily、Exa 们存在的理由。
━━━━━━━━━━━━━━━━━━━━
◆ 这层赛道的核心玩家
━━━━━━━━━━━━━━━━━━━━
按功能分三家代表,路线不同:
Tavily:直接给 LLM 上菜的搜索 API
它不返回十条蓝链让你点。它直接返回已经按相关性排好序、切好块、清干净广告的纯文本片段——就是 LLM 喜欢的那种格式。你的 agent 调一次 API,进来的是"可以直接塞 prompt"的内容。
成绩单:2025-08 拿了 Insight Partners 的 A 轮 2000 万美元。2026-02 被 Nebius 以 2.75 亿美元 收购,约 98 倍收入倍数——这是过去一年这层赛道里最快的退出。SaaS 行业 10 倍收入倍数算正常、20 倍算性感,98 倍说明买方相信它会成为基础设施。
Exa(前身 Metaphor):语义搜索,500B URL 索引
它的特点是理解你想搜的东西的"意思",不是匹配关键词。你问"那家做 LLM agent 工具被 OpenAI 投资过的小公司",传统搜索引擎给不出答案,Exa 能给。
成绩单更猛:
2025-09 B 轮 8500 万美元 @ 7 亿美元 估值(Benchmark + Nvidia 领投) - 2026-05 C 轮 2.5 亿美元 @ 约 22 亿美元估值
(a16z 领投) ARR 1000 万美元,YoY 增长 1010% 客户名单:Cursor、Cognition、HubSpot、OpenRouter——半个 AI 圈的精品店都在用
Firecrawl:网页 → Markdown 的转码器
我配过的那家。它干的事最朴素——给一个 URL,返回一份 LLM 友好的 markdown,过滤广告、规整代码块、保留链接结构。
成绩单:2025-08 拿了 1450 万美元 A 轮,投资方包括 Nexus、YC、还有 Shopify CEO Tobi。35 万开发者,GitHub 48k 星——一年时间从 GitHub 项目长成估值过亿的公司。
────────────────────
类似定位的还有几家,捎带列一下:
- Jina AI
Reader(r.jina.ai)是它的产品之一,免费额度大、用法极简(URL 前面加个前缀就直接转 markdown)。Jina AI 公司 2025-10 被 Elastic 收购 - SerpAPI
传统 Google/百度结果抓取,被 Google 起诉了,前途不明 - Brave Search API
独立索引(不靠 Google),2026-02 砍掉免费版改全量按量计费——这事在开发者圈里炸过锅 - Perplexity Sonar API
把它的整套"边搜边答"能力打包卖 - You.com API
商业数据不公开
━━━━━━━━━━━━━━━━━━━━
◆ 等等——这些 API,个人玩家要付钱吗?
━━━━━━━━━━━━━━━━━━━━
看到这里你可能心里咯噔一下:我那个豆包 + Hermes + Firecrawl 的玩具,是不是默默在烧着别人的卡?
不烧。我把这一栈逐家查了一遍官方 pricing 页,得到一张很有意思的表:
| 要绑卡 | ||
| 要预付 |
简单结论:搞个人 RAG 玩具、做点 vibe coding、跑个低频自动化——全程零成本零信用卡都跑得起来。一个月 1000 次搜索 + 1000 页抓取,对个人玩家是绰绰有余的额度。要 Google 真实结果时再考虑给 SerpAPI 或 Brave 付点钱。
那问题来了:他们这么大方,钱从哪来?
答案藏在客户名单里。Exa 的 C 轮估值 22 亿美元,背后的客户是 Cursor、Cognition、HubSpot、OpenRouter 这种已经在按月卖订阅的 AI 公司。Tavily 被 Nebius 收购前的 ARR 大概是几百万美元,撑起这个数字的也不是个人开发者——是把 Tavily 嵌进自家产品里的 SaaS 厂商。
所以这条生态的逻辑很清楚:
真正给他们付钱的是"二次封装的 AI 应用",个人开发者是免费用户兼用户教育——你今天免费玩 Firecrawl 玩得爽,明天进了公司搭 RAG 系统就给老板推荐 Firecrawl 企业版。这是经典的 B2D(business-to-developer)策略,DigitalOcean、Stripe、Twilio 当年走的就是这条路。
换句话说:这门生意不靠你赚钱,靠你"教"你的同事赚钱。你免费用得越爽,他们二次封装层的客户基础越大,估值越高。
━━━━━━━━━━━━━━━━━━━━
◆ agent 供应链总览:不止搜索
━━━━━━━━━━━━━━━━━━━━
把镜头拉远一点。一个真正能干活的 AI agent,需要的不只是"搜资料"——它要执行代码、要操作浏览器、要持久化记忆、要管理多步任务。每一个动作背后都有一家(或几家)公司在收钱。
| 浏览器自动化 | Browserbase | ||
| 向量数据库 | |||
| 代码沙箱 | E2B | ||
这张表不是为了凑名单,而是为了说明一件事:agent 不是一个模型加一个 prompt,它背后已经拆出了一整条供应链。两年前还不存在的赛道,现在 VC 圈管这一片叫 "picks and shovels for agents"——卖给淘金者的铲子。
下面挑三层展开:浏览器自动化、向量数据库、代码沙箱。它们分别对应 agent 的三种现实约束:进网页、记东西、跑代码。
━━━━━━━━━━━━━━━━━━━━
◆ 浏览器自动化:agent 的云端 Chrome
━━━━━━━━━━━━━━━━━━━━
Browserbase 干的事是:让 agent 能"看见网页、点按钮、填表单",不是直接接管你的 Chrome,而是租一个云端的无头浏览器实例。任何需要"像人一样操作网页"的 agent(自动比价、自动填表、自动下单),都得过它这一关。约 3 亿美元估值不是它技术多牛,是它卡在了 agent 通往 web 的关键通道上。
━━━━━━━━━━━━━━━━━━━━
◆ 向量数据库:agent 的长期记忆,真要上云吗?
━━━━━━━━━━━━━━━━━━━━
你做过 RAG 玩具的话肯定见过——把文档切成片,每片用 embedding 模型变成向量,存进 Pinecone / Milvus / Chroma 这类数据库,提问时算相似度找出最相关的几片喂给 LLM。所谓 agent 的"长期记忆",本质就是这套东西。
看完表格里 Pinecone 7.5 亿美元的估值,你大概率会冒出一个直觉问题:
这玩意为什么不直接做在本地?
不就是存一堆向量、算个余弦相似度吗?SQLite 都能塞手机里,文档量再大能大过我硬盘?凭什么非要去云端开个账户?
答案是:完全可以本地。技术上没什么挡着,只是大家都习惯不本地。
先说"完全可以"这半句。
2026 年本地方案已经成熟得不像话:sqlite-vec(SQLite 的几兆扩展)、LanceDB(Rust 嵌入式向量库)、Chroma(默认就是 in-process 模式)、pgvector(Postgres 一个扩展,单台机器稳跑 1000 万向量)——10 万向量以下笔记本秒查,1000 万以下单机都扛得住。普通人和中小企业的知识库全在这个范围内。
embedding 模型这边也一样:BGE-small 这种 45M 参数的小东西,量化后 CPU 上单条 < 10 毫秒——比联网调 OpenAI(200-800 毫秒含网络往返)还快。Apple 在 iOS 18 的语义图库已经在用端侧 embedding,你搜"狗在沙发上"召回对应照片,全程在手机上跑,不上云。
所以从纯技术看:个人和大多数中小企业的 RAG 根本用不着云。
那为什么大家还在用云?
不是技术问题,是一整套省资源的习惯让所有人默认走云:
- 手机厂商不给端侧留空间
8GB 内存五年没涨,端侧跑大模型总是吃力——开发者一看本地不靠谱,就直接调云 - 开发者被教育成"开箱即用"
所有 RAG 教程 90% 都是 OpenAI ada + Pinecone 那套。连让 AI 帮你写代码,AI 默认推的也是这一套——本地方案的文档加起来还没 OpenAI 一家多 - 榜单文化反向加固云端依赖
你看 Qwen3-Embedding-8B 在 MTEB 多语言榜登顶,下意识觉得"应该用最强的"——但 8B 本地跑等于杀鸡用核弹(INT4 量化也得 5GB 内存、CPU 上 1-3 秒/条),而你的玩具知识库用 45M 的 BGE-small 召回质量根本看不出差别。榜单只奖励"上限",不奖励"够用",于是默认推荐永远偏向云 - 云厂商当然乐见其成
Pinecone、Tavily、Turbopuffer 整个估值前提就是"应用必须调云",他们没动力推端侧方案
这是一个多方共谋的省事稳态:手机厂商省 BOM、开发者省学习成本、AI 工具省"教育用户"的成本、云厂省自己的命——没有谁有动力打破它。
两家旗舰 AI 工具的真实选择正好印证这套稳态没那么牢:
- Cursor 走默认路径
本地切 chunk → 加密上传 → 云端算 embedding → 云端存进 Turbopuffer。每月 20 美元订阅费里有真实的云成本 - Claude Code 干脆不用向量索引
——Anthropic 官方理由:"embedding 不是我们的核心,Agent 推理足够。"它靠 Glob / Grep / Read 直接遍历文件,每次都重新读
两条路都跑通了,说明"RAG 必须有向量数据库"这个看似铁律的前提,连主流玩家都没共识。
据市场数据和媒体转述,Pinecone 的 ARR 曾被报出明显下滑——这个数字不是官方披露,但趋势本身不难理解:底下被嵌入式方案侵蚀,顶上被长上下文吃掉(语料能塞进窗口就不用 RAG),中间地带正在塌陷。这条路数据库走过:Oracle → MySQL → SQLite → 云原生,最后变成 U 型分布——超大规模上云、小规模嵌入式,中间被挤光。向量数据库正在重演。
━━━━━━━━━━━━━━━━━━━━
◆ 代码沙箱:云端 agent 的一次性电脑
━━━━━━━━━━━━━━━━━━━━
你想过没——ChatGPT 的 Code Interpreter 让你说"帮我跑一下这段 Python 看输出",它真在哪里跑?
如果跑在主推理集群上,agent 能改文件、能装库、能改环境变量,平台这条命就没了。所以云端 agent 工具必须有一层一次性隔离沙箱——可能自建,也可能采购 E2B / Daytona 这类能力:给一个隔离的 Firecracker microVM(AWS Lambda 用的同款技术)或等价容器环境,跑完销毁。一次几分几秒钱,agent 替你买单——最后还是平台从订阅费或企业账单里扣。
注意这一层和前面几层有个本质区别:代码沙箱只有云端 agent 用得着。像 Claude Code、Cursor、Codex 这类跑在你本地终端的 agent 直接在你电脑上跑命令,根本不需要远程沙箱(我帮你改这篇稿子,用的就是你自己的文件系统,没掏任何沙箱钱)。所以 E2B / Daytona 瞄准的真正客户,是各种 Web 端 vibe coding 平台、SaaS 类 agent、企业内部自动化平台——一切没法访问用户本地机器、又必须安全执行代码的应用。
这也解释了一个有意思的现象:为什么 Claude Code、Cursor 这类工具最近这一年长得最猛?除了 vibe coding 这股风,另一个隐藏优势就是它们不用付远程沙箱钱——同样一次 Python 执行,云端 agent 要么自建隔离环境,要么采购沙箱/浏览器基础设施,本地 agent 这笔账直接是零。利润率天差地别。
━━━━━━━━━━━━━━━━━━━━
◆ 中国侧:一个反常的空白
━━━━━━━━━━━━━━━━━━━━
这层赛道在中国是什么状态?盘点下来,前面两节其实已经摸到了——这里把两个案例放一起看,结论就清楚了。
搜索 API 那一层:百度千帆把"百度 AI 搜索"API 化了、字节豆包 1.6 内置工具搜索、火山引擎给企业出"联网搜索 API"方案——全是大厂内嵌。百度的 API 只在百度生态好用,字节的搜索绑死豆包模型。你要跨厂用(比如豆包配百度搜索),没有顺手方案——这就是为什么我用 Hermes + 豆包还得去填海外 Firecrawl 的 key。
向量数据库那一层:同样的故事,甚至更刺眼——embedding 模型层中国全球领先(阿里 Qwen3-Embedding-8B 登顶 MTEB 多语言榜、智源 BGE-M3 是开源主力),但独立向量数据库公司一家都没有,国内市场被阿里云 AnalyticDB-V、腾讯云 VectorDB、百度云 VDB、火山引擎 viking DB 瓜分干净。模型这种重资产、高门槛的层国内能造世界第一,独立中间件这种轻资产、靠 SaaS 模式吃饭的层却长不出来。
两个案例叠在一起,差别就不是"哪个赛道国内没做"了,是一个结构性问题:模型能造,独立中间件造不出。
为什么?这不是技术问题,是商业模式问题。美国的 SaaS 文化允许"小公司只做一层、靠下游 SaaS 厂商付费活下来"——前面讲过的 Tavily / Firecrawl / Pinecone 整个估值前提就是这个。中国的互联网文化倾向"大厂全栈、用户白嫖",任何"只做一层"的独立创业公司,融资 PPT 上第一个被问的问题都是"百度/阿里/字节做了你怎么办"。
对个人开发者反而有副作用是好的:你用 sqlite-vec + 国产开源 BGE-small,全程不花钱、不联网、不出国——是这条赛道里最舒服的位置。只是这条路得自己走,AI 不会主动推荐——它默认还是会让你调 OpenAI。
反过来想:这个空白本身就是机会。等中国的 agent 生态长出独立工具链,第一家做对的公司很可能就是这条赛道的国产 Tavily 或国产 Pinecone。
━━━━━━━━━━━━━━━━━━━━
◆ 这场暗赛跑的本质:AI 把 web 的消费者换了
━━━━━━━━━━━━━━━━━━━━
把这一切串起来,背后的逻辑就一句话:
Web 的主要消费者,正在从人类换成 AI agent。
过去三十年,整个互联网是为人优化的——网页要好看、广告要醒目、按钮要好点、推荐要上瘾。所有基础设施(CDN、浏览器、SEO、广告网络)都围绕"如何让人在网页上停留更久"建起来的。
现在多了一种新消费者,它不看广告、不停留、不滚动、不点赞——它只想要结构化的、可解析的、按相关性排好序的纯文本。人类那套基础设施对 agent 是负优化:JavaScript 渲染浪费它时间、广告挤占它注意力、反爬机制直接拒它进门。
于是必然有一批新基础设施长出来,专门服务这个新消费者。Tavily 是"agent 的 Google"、Firecrawl 是"agent 的浏览器"、Browserbase 是"agent 的 Chrome"、E2B 是"agent 的本地终端"、Pinecone 是"agent 的硬盘"。
每一个角色在人类世界里都已经有巨头,但 agent 的版本要重新来一遍——因为协议不一样、数据格式不一样、安全模型不一样、计费模式不一样。
这就是"agent 时代的水电煤"的真正含义:不是说这些公司像水电煤一样不可或缺(它们当然可替代),是说它们正在重建一遍 web 的底层水管——给一个新的、非人类的消费者用。
谁的水管接好了,谁就能卡住未来十年的 agent 流量。Tavily 的 98 倍倍数收购、Exa 的 1010% 增长、Browserbase 的 3 亿美元估值,VC 算的就是这本账。
━━━━━━━━━━━━━━━━━━━━
◆ 给程序员的一句实用提醒
━━━━━━━━━━━━━━━━━━━━
最后说点实际的。
个人玩家配个 key 跑玩具,确实零成本。但真到了"几十万行代码的 codebase 让 Cursor 帮我重构"这种场景,背后烧的就不是免费档了——可能是 Exa 这类搜索 API、Turbopuffer 这类向量存储、模型调用、自建索引和缓存系统共同在烧钱,再从你的月费里扣。你现在用的每一个 AI 工具(Cursor、Claude Code、各种 vibe coding 玩具、各种 RAG demo),背后都在悄悄烧基础设施的钱。这些钱大概率不是你自己掏,是工具厂商(Anthropic、Cursor 等)从订阅费里扣——但羊毛出在羊身上,订阅费迟早要涨。
哪天你看到 Cursor 涨价、Claude Max 限额、ChatGPT Pro 取消某项福利——别只骂这些大厂"割韭菜"。它们背后是一整条按 token / 按 query / 按 sandbox 秒数计费的供应链。Tavily 涨一次价、Browserbase 提一次 SLA,这些钱不会凭空消失,最终都会从某个地方咬回你的订阅费。
下一次你的 AI 工具弹出"请配置搜索引擎 API key"——你就知道,那个对话框背后,是一家估值几亿美元的公司在跟另一家估值几十亿美元的公司做生意,而你恰好是这门生意里那个不知情的中转节点。
━━━━━━━━━━━━━━━━━━━━
💡 本文涉及的公司与公开数据:
- Tavily
LLM 友好搜索 API,2025-08 A 轮 2000 万美元,2026-02 被 Nebius 以 2.75 亿美元 收购(~98 倍收入倍数) - Exa
(前 Metaphor):语义搜索 + 500B URL 索引,2026-05 C 轮 2.5 亿美元 @ 约 22 亿美元估值,ARR 1000 万美元 / YoY 1010% - Firecrawl
网页 → Markdown,2025-08 A 轮 1450 万美元,35 万开发者 - Jina AI / Reader
Reader 是 URL 前缀转 markdown 产品,Jina AI 公司 2025-10 被 Elastic 收购 - Browserbase
云端无头浏览器,B 轮 4000 万美元 @ 约 3 亿美元估值 - E2B
agent 代码沙箱,A 轮 2100 万美元,88% 财富 100 强客户 - Daytona
A 轮 2400 万美元(2026-02),两个月破 100 万美元 ARR - SerpAPI
传统搜索结果抓取,被 Google 起诉中 - Brave Search API
独立索引,2026-02 取消免费档 - Cloudflare Pay-Per-Crawl
微软 2025-08 关停 Bing 公共搜索 API:传统 web 抓取通道的双重坍塌
━━━━━━━━━━━━━━━━━━━━
「AI 把 web 的消费者换了一个物种。围绕新物种的整条基础设施,正在被重建一遍。」
「真正的护城河不在技术,在多方共谋的省事稳态:手机厂商省内存、开发者省学习、AI 工具省训练数据偏差、云厂省自己的命——没人有动力打破它。」
「你每一次让 AI'帮我查一下',背后都有一家估值过亿的公司在按 query 收钱。这门生意里你不是顾客——你是流量。」
━━━━━━━━━━━━━━━━━━━━
// 靳岩岩的 AI 学习笔记 × Claude 的严谨 × Gemini 的浪漫
// 2026-06-15
