 夜雨聆风
夜雨聆风本体论与数据智能
数据治理做了十年,AI 时代要推翻重来,还是终于能用上了?
本体建模规模化落地的真实障碍与破局路径
本体论Ontology数据治理企业架构AI Agent人机协作规模化落地
上一篇聊了「从业务对象到本体对象」的映射路径。
文章发出去之后,收到了一条非常真实的私信:
映射表我看懂了,但我们公司数据治理搞了三年,产出一堆架构文档根本没人看。你现在告诉我还要再搞一遍本体建模,我怎么跟老板交代?
这代表了一种非常普遍的情绪。
做过数据治理的企业,对「再来一次」有深深的 PTSD。
今天正面回答这个问题:本体建模在 AI 时代规模化落地,是注定重蹈覆辙,还是终于等来了不同的条件?
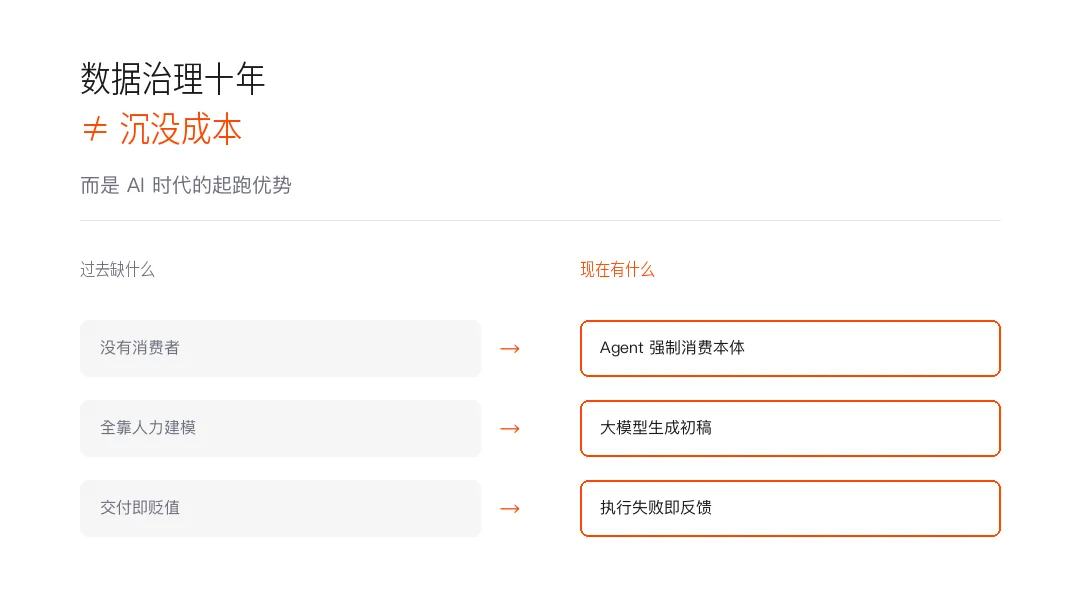
数据治理十年不是沉没成本,而是 AI 时代的起跑优势
▌数据治理的「三无困境」

三无困境:无人用、无回报、无闭环
先承认事实:过去十年,大量企业在数据治理上的投入,从业务部门视角看,效果不好。
无人用。
数据标准文档、ER 模型图、数据字典、元数据目录——存在 Confluence 或 SharePoint 里,业务人员几乎不会打开。
因为这些东西回答的是「数据应该长什么样」,而业务关心的是「我今天这个审批怎么走」。
中间隔着一层巨大的翻译鸿沟。
架构师觉得自己做了很重要的工作。业务觉得「你们又在自嗨」。双方都没错,问题出在产出形式上——它不在业务的工作流里。
无回报。
花了 500 万请咨询公司梳理数据标准,业务问:营收涨了吗?成本降了吗?
最后只能说「元数据覆盖率从 40% 到 85%」。
对高层来说,这约等于「所以呢?」
无闭环。
咨询公司来了,梳理三个月,交付文档,走了。
两年后数据架构文档和实际系统已经对不上。
没有持续运营的机制,成果在交付的那一刻就开始贬值。
员工的真实体感:又来一波人让我们填表、开会、对齐口径。折腾三个月,日常工作没有任何变化。过两年,又来一波。
这不是抱怨,这是事实。产出不能变成日常可感知的价值,每一次治理就是纯成本。
▌AI 时代,是重蹈覆辙还是历史契机?
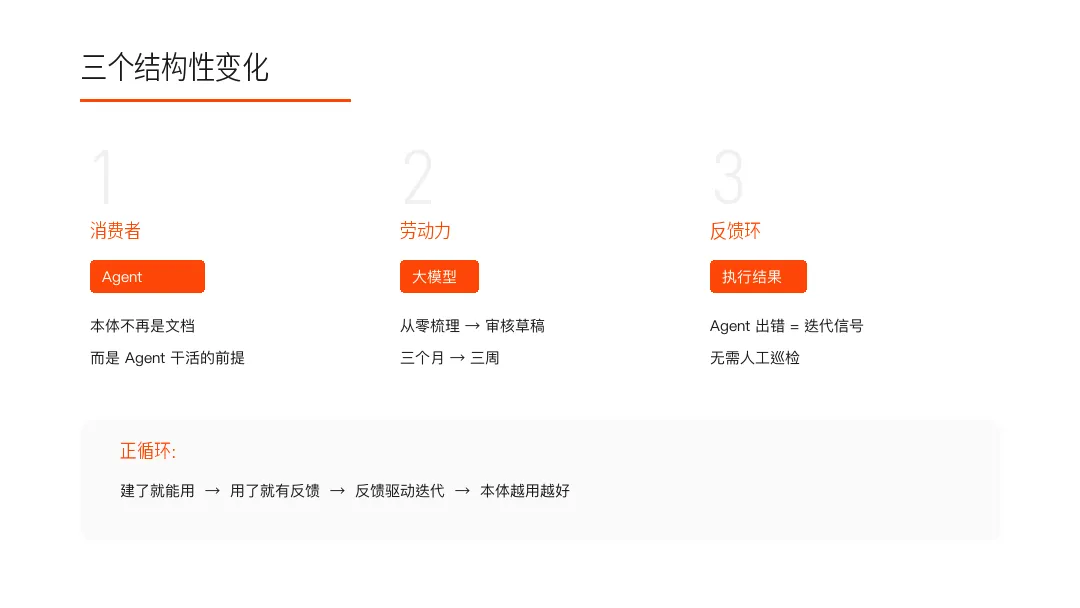
三个结构性变化:消费者、劳动力、反馈环
现在大模型来了,AI Agent 来了,又有人说「企业需要建本体」。
业务部门的第一反应:又来?
这个担心完全合理。
如果本体建模的落地方式还是——先花半年梳理、再花半年建模、建完放在那里等人用——结局一定一样。
但这一次,有三个结构性变化,使得境遇根本不同。
第一,终于有了消费者。
过去数据治理产出没有刚需消费者。数据标准文档的「用户」理论上是开发和分析师,但他们有自己的工作习惯,很少主动查阅。
AI Agent 不一样。它是一个强制性的消费者。
让 Agent 处理「查这个客户的历史订单,评估续约风险」,它必须知道:「客户」是什么对象、「订单」是什么对象、它们之间什么关系、「续约风险」怎么算。
没有结构化的业务语义,Agent 就是一个只会瞎猜的聊天机器人。
本体不再是「最好有」,而是「Agent 能不能干活」的前提条件。
有了刚性需求方,供给侧的投入才有明确回报。这是过去十年数据治理从未拥有的条件。
第二,建模成本断崖式下降。
过去全靠人。架构师一个一个访谈业务专家,一个一个梳理对象和关系。一家中型企业核心业务对象梳理,少说三个月。
现在大模型可以:读已有架构文档自动提取对象和关系初稿;读业务流程描述自动识别 Action;读 SQL DDL 自动推断属性和约束。
人的角色从「从零梳理」变成「审核 AI 草稿」。
不是效率提升 20%,是从三个月缩短到三周。
第三,反馈闭环天然形成。
过去数据治理没有闭环——建了标准,没机制知道有没有被遵守。
当本体被 Agent 消费时,反馈是即时的:
Agent 执行失败 → 本体定义不够精确或关系缺失。
Agent 理解错业务含义 → 语义描述需要补充。
Agent 跨对象导航走不通 → Link 定义有遗漏。
每一次 Agent 出错,都是本体需要迭代的精确信号。不需要人工巡检,不需要季度评审。
三个变化叠加:本体建模第一次有了「建了就能用、用了就有反馈、反馈驱动迭代」的正循环条件。
▌已有成果能用吗?——三个层次

已有成果三层判断:直接用 / 需加工 / 不能用
确认了「值得做」之后,更实际的问题:之前花的钱搞的成果,能不能直接拿来用?
答案是分层的。
可以直接用的——
业务对象清单。客户、产品、订单、供应商、合同、设备——这些是本体的骨架,名字、定义、分类体系可以直接翻译为 Object Type。
核心实体关系。ER 图里的主要关系——客户和订单的归属、产品和供应商的供应——直接映射为 Link Type。
数据字典。字段名、数据类型、业务含义、取值范围——Object Type 属性定义的起点。
共同特征:它们描述了「业务世界里有什么」,这正是本体的核心。
需要加工的——
从静态描述「激活」为运行时定义。文档写着「客户有信用等级属性」,本体需要知道:值从哪个系统同步?更新频率?谁有权限修改?
从结构定义补充行为定义。ER 模型有实体和关系,但没说「对这些实体能执行什么操作」。Agent 需要知道面对信用下降的客户能做什么——暂停发货?触发审核?调整授信?
从单系统升级为跨系统。大多数数据架构按系统画。但本体需要跨系统统一视图:同一个「客户」在 ERP、CRM、MES 三种表达,融合成一个 Object Type。
不能直接用的——
纯技术规范(数据库命名规则、接口协议)、过时流程文档、脱离语境的模糊指标定义。
判断标准:这份资产能回答「业务里有什么东西」「它们之间什么关系」「对它们能做什么」吗?前两个通常能,第三个通常不能。已有成果覆盖本体的 60-70%,剩下 30-40% 需要补。不是重来,是补完。
▌如何避免重蹈覆辙——四个原则

四原则路径:边用边建 / AI做苦力 / Agent验收 / 持续运营
知道了「有基础、要补完」,下一个问题:怎么补才不重蹈覆辙?
核心四个字:边用边建。
原则一:先让 Agent 跑起来,再迭代本体。
过去是「先治理完再上线」。用一年搞完标准,然后推广。结果一年后世界变了,标准过时了。
新做法:用最小可用本体,先让 Agent 在小范围场景跑起来。跑不通的地方就是需要补的地方。
先把「客户」「订单」「产品」三个核心对象建出来,让 Agent 尝试「客户续约分析」。它会告诉你缺什么——缺「合同到期日」属性、缺「客户-客户经理」关系、缺「发起续约提醒」Action。补上,立刻生效。
反馈周期从「年」缩短到「天」。
这意味着本体不需要一开始就完美。它可以从粗糙开始,在使用中长出来。
原则二:AI 做苦力,人做决策。
建模最耗时的不是判断,是收集信息——从各种文档和人脑中把业务知识挖出来整理好。
这恰恰是大模型擅长的。让 AI 读数据治理文档、API 文档、SQL schema,自动生成本体草稿。业务专家只需审核:定义对不对?关系有没有遗漏?操作前置条件是什么?
业务部门不再需要「参加三个月的治理项目」,只需要「每周花一小时审核 AI 草稿」。
原则三:验收标准是 Agent 能不能干活。
过去验收标准是文档覆盖率、元数据完整率——治理团队自己评自己,业务不认。
新标准简单粗暴:Agent 能不能正确完成业务任务。
让 Agent 处理采购审批——看它能不能识别审批规则和权限链。让 Agent 做客户风险预警——看它能不能正确获取数据、计算指标、触发动作。
Agent 干得好 = 本体建得好。不需要解释「元数据覆盖率」是什么。
原则四:持续运营,不是一次性项目。
本体不是建完就放的静态资产。业务在变,本体必须跟着变。
好消息:当 Agent 持续使用本体时,变化会自动被感知。执行失败 = 有什么变了。失败日志就是迭代的需求池。
运营可以很轻量:Agent 错误自动上报 → 每周整理高频错误 → 业务专家审核修复方案 → 修复后 Agent 立即生效。
不再是「每两年搞一次大运动」,而是「每周微调一点点」。员工感知不到被治理的痛苦,但本体在持续进化。
这四个原则的共同逻辑是:把建模从「前置的大工程」变成「伴随使用的小迭代」。
过去失败的核心原因不是方法论错了,而是建设和使用之间的时间差太长、反馈链太弱。现在 Agent 把这两个问题同时解决了。
▌这一次,三要素齐备
回到开头的问题。
过去数据治理失败的根本原因,不是治理本身不对,而是缺了三个关键要素:
三要素齐备,正循环就能跑起来。
那些年积累的业务对象、实体关系、数据字典——不是沉没成本,是这一轮建设的起跑优势。做过治理的企业比没做过的能快半年进入 Agent 实际使用。
但有一个前提:换一种方式来做。
不是先花一年建完整本体再上线 Agent,而是先让 Agent 跑起来,用它的失败驱动本体生长。
不是让业务部门「配合治理」,而是让他们「审核 AI 的理解是否正确」——心理负担完全不同。
不是追求文档的完美,而是追求 Agent 的有效。
数据治理做了十年,不是白做了。是终于等来了能把它们激活的那把钥匙。
【延伸阅读】
相关阅读
从业务对象到本体对象:你的数据治理成果,离 Ontology 还有多远?
大模型+本体=企业AI的终极形态:当 LLM 遇上 Ontology,终局是什么
RAG vs 微调 vs 本体:企业知识管理三条路,该走哪条?
近期新文
一个人就是一支团队:如何用 Claude Code 搭建你的 AI Agent 军团
经典热文
本体论与数据智能 · 系列目录 · 目录 ≡
