 夜雨聆风
夜雨聆风现在很多人每天都在用AI:帮写邮件、整理报告、翻译文件、做PPT……
但你有没有想过:你输入到AI里的这些内容,它都看见了,然后呢?
很多主流AI工具的用户协议里有这样一条:
"您的输入内容可能被用于改进我们的模型和服务。"
翻译成大白话就是:你输入的东西,可能会被拿去训练AI。
你打进去的那份合同内容、客户信息、公司战略——有可能成了AI下一个版本的训练素材。
不是说所有AI都这么干,但如果你没看协议,你根本不知道你的数据有没有被用。

公司内部文件(合同、财报、战略规划、客户名单)
个人身份证件信息(姓名+证件号+地址的组合)
密码、API密钥、后台账号信息
医疗诊断报告、病历等隐私数据
涉及商业秘密的研发资料
曾经有公司员工把完整的业务合同粘贴进ChatGPT提问,后来发现这份内容被其他用户在某些场景下间接获取——这件事当时引发了大规模的企业AI使用政策讨论。
ChatGPT (OpenAI)
设置→ Data Controls → 关闭"Improve the model for everyone"
Kimi / 文心一言 / 通义千问
各平台的隐私设置或账号中心里,找"数据授权"或"内容使用授权",选择不允许。具体路径可在各App设置页搜索"隐私"。
企业版AI工具
企业购买的专属版本通常默认不用于训练,但要和采购方确认协议里的条款。
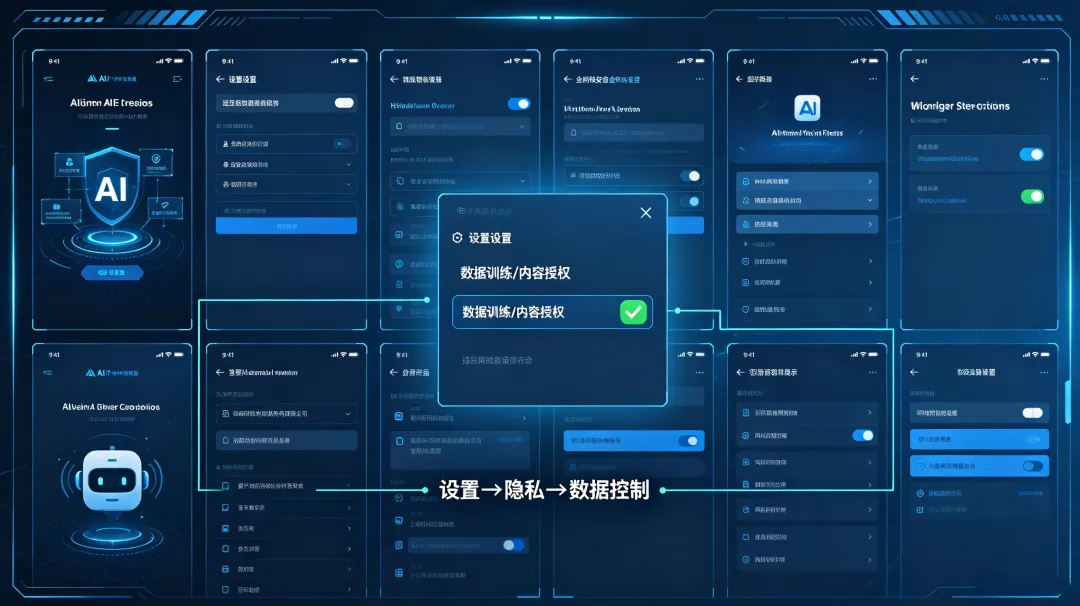
敏感内容先脱敏再输入(比如把客户名字换成"A公司")
公司重要文件用公司内部的私有化部署AI,不用公开云服务
个人信息类任务,用AI辅助结构,具体数字和名字自己填
定期清除AI工具的历史对话记录
用AI不是不行,但用之前要知道边界在哪。



