 夜雨聆风
夜雨聆风6 月 10 日,工信部印发了《「人工智能+信息通信」创新发展实施意见(2026—2028年)》。这份文件涉及的内容很多,网络、算力、行业治理都有部署。今天我们只挑其中一条线,从光电的角度聊聊它的影响。
先看它点名的那串器件名词:高速光电芯片、全光交换器件、光电共封装器件、智算超节点光电互联。一份部委级的纲领文件,把这几类器件并排写进同一段,本身就是个信号。
如果把这串名词按它们在网络里的位置摆开,会发现它们连成了一条线。光在通信链路上,从城域骨干一路往下沉,一直沉到芯片旁边。这篇就沿着这条线走一遍,看每一段光在替谁干活,政策为什么单独把它点出来,国产又走到了哪一步。
政策点名的,是一串具体器件
在聊之前,让我们先看下原文内容。文件在「夯实人工智能发展底座」这部分写道,要「加强高速光电芯片、高速转发/交换芯片、全光交换器件、光电共封装器件等技术和产品研发」,「开展光电混合组网技术试验」,「加强智算超节点光电互联技术攻关」;在网络这一侧,则提「有序推进城域 400Gbps 及以上、全光交叉等高速光传输系统设备应用」,以及「加快建设 400Gbps/800Gbps 等骨干传输网络」,并定了一个量化目标,到 2028 年,城域算力 1 毫秒时延圈覆盖率不低于 75%。
这里要先做个切分。那一串里还有「高速转发/交换芯片」,它是网络设备的电侧主芯片,不在本文要讲的光器件里,先放下。剩下的全光交换器件、光电共封装器件、智算超节点光电互联,再加上城域骨干的全光交叉,才是这条「光」的线。
还有个细节容易被略过,政策对不同器件用的动词不一样。对城域和骨干,用的是「有序推进……应用」「加快建设」;越往里到光电共封装、超节点这一侧,用的是「研发」「技术攻关」「技术试验」这类词。这一字之差,可以理解为它们各自走到了不同的阶段。一个在铺,一个还在攻。这是读这份文件的一个角度,后面会反复用到。
至于那个「1 毫秒时延圈」,政策把目标定在时延上。时延为什么是光的长项,我们在华为韬定律那篇里详细聊过,感兴趣的可以再去翻看一下。
一条从城域到芯片旁的「光下沉」过渡带
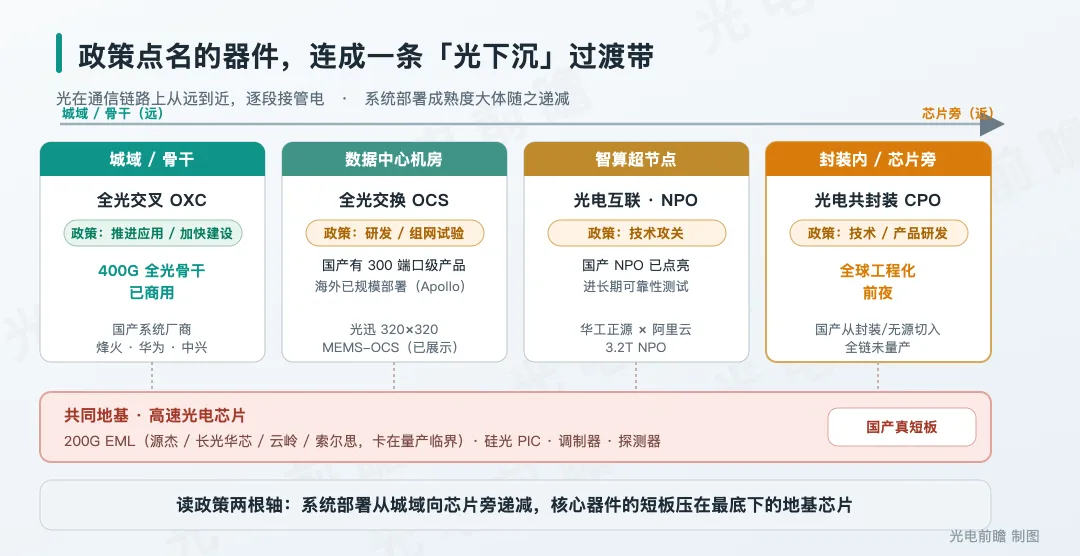
把政策点的这几样东西按距离从远到近排开,就是城域骨干、机房里的 OCS、机柜内的超节点、芯片旁的 CPO。
最远的一端是城域和骨干。几十到几百公里的传输,光早就是主力,这一段没什么悬念。政策里的「全光交叉」指的是 OXC(光交叉连接),让波长在光层直接调度,省掉一个个节点上反复的光—电—光转换。这是最成熟的一格。
往里走,到数据中心机房内部,是全光交换 OCS。它用光开关在物理层直接重构大流量的连接关系,把一部分本来要过电交换芯片的流量挪到光层,减少反复的光电转换和包交换压力。注意是「一部分」。OCS 处理的是相对稳定的大颗粒连接,并不替代全部电交换,两者是配合关系。这一层的格局,我们在OCS 光交换进入战国时代里详细聊过,这里就不具体展开了。
再往里,是智算超节点。这是一个应用场景,指把一柜或几柜的 GPU、NPU 在 scale-up 域里用高带宽连起来。这一段历来用铜,但速率和距离一起往上顶的时候,铜开始撑不住,光就往里接管。
NPO 是近封装光学,光引擎贴在 ASIC 旁边的板子上;CPO 是共封装光学,光引擎和 ASIC 做进同一个封装基板里。两者都是为超节点这个场景服务,只是光往芯片贴近的程度不同。铜和光在这一段按距离、速率分着用,不是谁把谁完全取代。
最里的一端是封装内的 CPO。把光直接下沉到 ASIC 同一个封装里,目的是缩短芯片到光之间那段高速电通道,降低 SerDes、retimer 和面板 I/O 的压力。这是「光替代电」这条线上最后、也是最难的一段。至于 CPO 那一颗光引擎从硅片到成品要走多少道工序,CPO 工艺流程全景那篇有详细的介绍。
把这四段连起来看,不能简单概括成「距离越长光越好」。光往哪一段沉、什么时候沉,由距离、速率、功耗、可维护性几个因素一起决定,是一条有先有后的过渡带。政策这次特别的地方,是把这条过渡带上的几格器件一次性都点了名。
政策的措辞梯度,对上国产成熟度的两根轴
把这条过渡带和国产的实际进度对一下,得用两根轴来看。一根是系统部署的成熟度,看某一段的光互连在真实网络里到底铺到了什么程度;另一根是核心器件的国产短板,看做这段光互连要用的关键芯片、器件,国产补齐了没有。我们现看第一根。
系统部署这根轴,大体从城域往封装内递减。
城域骨干这一端最实。中国移动的 400G 全光省际骨干网已经商用,首条是北京到内蒙古,国产系统厂商在这一层是主力。但要说清楚,系统强不等于每个核心器件都国产到位。相干 DSP、高端的 WSS / ROADM 这些器件,国产仍有一项项要补的缺口。所以这根轴量的是「系统部署到了哪一步」,不是「国产全链做齐了」。
往里到 OCS,国产已经能拿出产品。光迅科技在 OFC 上展示过 320×320 端口的 MEMS 全光交换,华为也有自己的 OCS 方案。但海外把 OCS 做进规模生产网络已经有几年,Google 的 Apollo 是公开可查的标杆。国产现在是有产品、有平台能力,离「在大规模生产网络里稳定跑很多年」还差调度软件和长期可靠性这两块。

再往里到超节点,国产这一段反而不弱。华工正源和阿里云联合点亮了 3.2T 的 NPO 模块,已经进入长期可靠性测试。它的工程取舍值得看一眼。用 Linear Drive 省掉了 DSP,功耗和时延都更友好;光源走 ELSFP 外置,激光器怕热又娇气,放在封装外面能单独拔插更换。

这里要避开一个常见误解。外置光源不是 NPO 的专利,主流 CPO 方案同样倾向把激光源外置,道理一样是怕热怕坏。NPO 在超节点这段先跑起来,真正的原因在封装本身。光引擎贴在 PCB 板上,组装难度和良率风险都比 CPO 那种基板级共封装低一截。
到最里的封装内 CPO,全球大体还在工程化的前夜,NVIDIA、TSMC、Lumentum 在前面探路。国产能参与的主要是封装和无源这些环节,而把交换 ASIC、硅光 PIC、电芯片、光源、封装、运维整条链做到规模量产,目前没有公开的证据。
再看第二根轴,核心器件的国产短板。它并不沿着距离单调变化。超节点这段国产 NPO 已经点亮,短距侧并不落后。真正吃力的,是这几层共同踩着的那块底层。
横在所有层下面的,是地基那块芯片
不管是 OCS、NPO 还是 CPO,往下扒到底,都站在同一块地基上:高速的光源、调制器、探测器,以及硅光 PIC。这块地基里,最容易用公开数据追踪进度的,是 200G 每通道的 EML。
国产在这一档上正卡在量产的临界线。长光华芯的 100G EML 已经量产、200G 在送样;源杰的 200G EML 在头部客户验证阶段;云岭光电的 112G 波特率 EML(对应单波 200G)也在送样;东山精密旗下的索尔思则已经能量产 200G EML(索尔思是收购来的资产,和长光华芯、源杰这种本土自研不同)。整体看,国产这一档还在从验证走向放量的路上,大致是这一两年的事。
要补一句,地基不只是 EML。CPO 可以走外置 CW 激光加硅光调制器,OCS 重度依赖 MEMS 和光纤阵列。EML 是一颗好用的钉子,但不是唯一的地基。
总的来说,上面的封装、系统做得再漂亮,地基的速率上不去,整条线就受制。这大概也是政策那串名词里,「高速光电芯片」被摆在第一位的原因。
写在最后
读这份政策,我们可以看到两件事。
一是它的措辞强度大致对应着推进阶段。在铺的用「推进应用」,在攻的用「技术攻关」,对着读能省不少力。二是看国产的真实位置,得两根轴一起拿。系统部署从城域往封装内递减,核心器件的短板则集中在最底下那块地基芯片上。
往后这条线怎么走,几个可以关注的点正好落在这两根轴上。系统部署这根,往里盯两头。国产 OCS 能不能从展会上的演示走进规模生产网络,城域 400G、800G 全光骨干又铺得多快。器件这部分,关注最底下那格,200G EML 的国产产能什么时候真正放出来,以及国产 CPO 那条从交换 ASIC、硅光 PIC、光源到封装的全链,什么时候出现量产闭环。这几个点动起来的快慢,就是这条「光下沉」之路真实的刻度。
我们也会持续跟踪关注,并第一时间给大家带来最新进展。
欢迎继续阅读:
从光模块到 CPO 都绕不开的有源光耦合:1.5 万字解读这道最难自动化的工序
CPO 工艺流程全景:一颗光引擎从硅片到成品的 10 道工序
200G EML 缺口超 50%,一份覆盖光模块 8 类芯片的供需报告
国内云厂商光模块采购图谱:阿里、字节、腾讯的供应商、份额与决策逻辑
谢谢你读完。觉得有用,欢迎 关注 / 点赞 / 在看 / 转发;想不漏推送,给「光电前瞻」加个星标⭐。我们下一篇见。
参考来源:工业和信息化部《「人工智能+信息通信」创新发展实施意见(2026—2028年)》原文(经新华网、安全内参、中国基金报转载核对);中国移动 400G 全光省际骨干网商用(央视网、财联社、光纤在线);光迅科技 320×320 MEMS-OCS(OFC 2026,新浪科技、C114 通信网);华工正源 × 阿里云 3.2T NPO 模块点亮(华工正源官网、光纤在线);200G EML 国产进展(长光华芯 2025 年半年报,源杰、云岭光电、东山精密公开材料);Google Apollo 光交换(arXiv: 2208.10041)。
