 夜雨聆风
夜雨聆风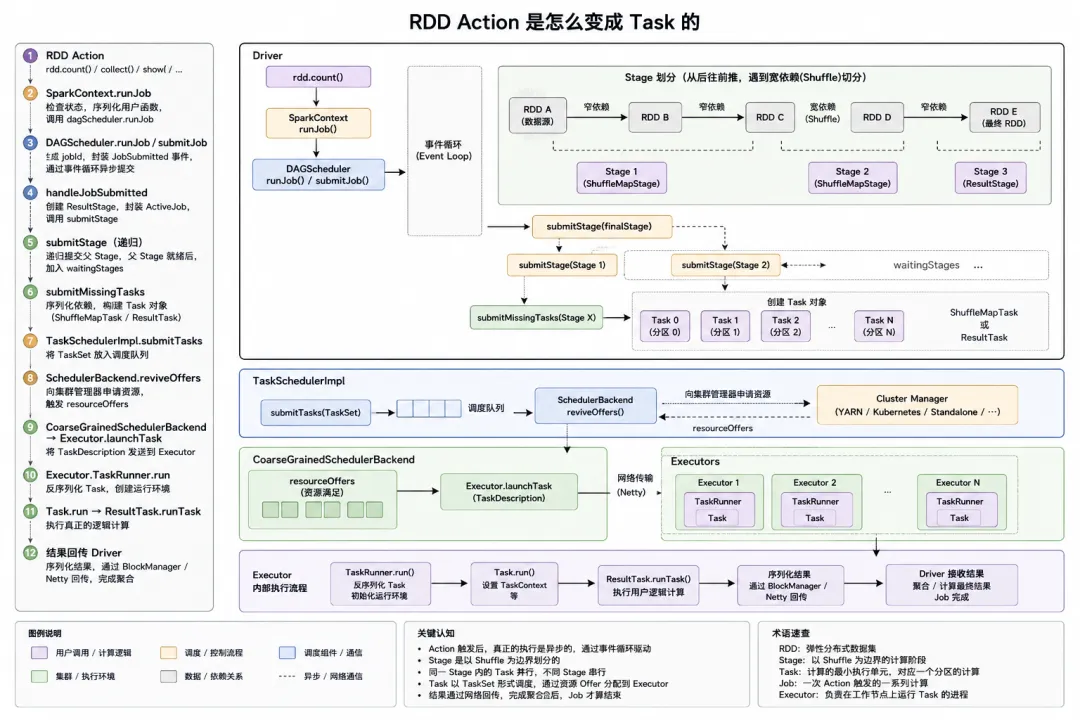
基于 Spark 4.2,分支
branch-4.2阅读时长约 10 分钟 · 入门到中级
背景
上一篇文章我们走完了「一条 SQL 在 Spark 中的一生」——从 spark.sql 一直到 executedPlan.execute() 产生了 RDD。
那 RDD 又是怎么执行的?
rdd.collect()或者哪怕你写的不是 RDD:
df.show()
df.count()
这些 action 背后触发的是同一个机制。这篇文章就回答一个问题:
rdd.count() 这一句话,从 Driver 到 Executor,到底经过了几步?
一、流程图:一条完整的调用链
rdd.count() ← RDD action↓SparkContext.runJob ← 入口↓DAGScheduler.runJob / submitJob ← 事件循环↓DAGScheduler.handleJobSubmitted ← 创建 ResultStage↓DAGScheduler.submitStage ← 递归提交父 Stage↓DAGScheduler.submitMissingTasks ← 创建 Task 对象↓TaskSchedulerImpl.submitTasks ← 调度层↓SchedulerBackend.reviveOffers() ← 调用集群管理器↓资源满足 → resourceOffers ← 分配 Task 到 Executor↓CoarseGrainedSchedulerBackend→ Executor.launchTask ← 网络传输 TaskDescription↓Executor.TaskRunner.run ← 反序列化 + 执行↓Task.run → ResultTask.runTask ← 真正的逻辑执行↓结果序列化 → 回传给 Driver
关键认知:从 count() 到真正的 ResultTask.runTask,中间隔了 10 层以上的调用。每一层都有自己明确的职责。
二、起点:RDD action
RDD 的方法分成两类:
transformation(map / filter / flatMap)—— 只构建 RDD 血缘,不触发执行
action(count / collect / reduce / take / saveAsTextFile)—— 触发真正的执行
看 RDD.scala:1320:
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum看 RDD.scala:1072:
def collect(): Array[T] = withScope {val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)import org.apache.spark.util.ArrayImplicits._Array.concat(results.toImmutableArraySeq: _*)}
所有 action 最终都调用 sc.runJob(...),传入 RDD 实例 和 一个分区处理函数。
三、SparkContext.runJob:守护检查 + 下发给 DAGScheduler
SparkContext.scala:2481:
def runJob[T, U: ClassTag](rdd: RDD[T],func: (TaskContext, Iterator[T]) => U,partitions: Seq[Int],resultHandler: (Int, U) => Unit): Unit = {if (stopped.get()) {throw new IllegalStateException("SparkContext has been shutdown")}val callSite = getCallSite()val cleanedFunc = clean(func)dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)progressBar.foreach(_.finishAll())rdd.doCheckpoint()}
SparkContext 在这里只做两件事:
检查应用是否已停止
序列化用户函数(
clean确保闭包里引用的外部变量是可序列化的)
然后立刻甩锅给 dagScheduler.runJob。
四、DAGScheduler:事件循环
DAGScheduler 的设计基于事件循环。所有操作都是通过 eventProcessLoop.post(event) 来异步触发的,而不是同步调用。
DAGScheduler.scala:984。下面是简化后的代码,保留关键路径:
def submitJob[T, U](rdd: RDD[T], func: ..., partitions: ...,callSite: ..., resultHandler: ...,properties: Properties): JobWaiter[U] = {// 校验分区范围// 预计算 RDD partitions(避免在事件循环里慢)val jobId = nextJobId.getAndIncrement()if (partitions.isEmpty) { /* 立即返回 */ }val waiter = new JobWaiter[U](...)// 异步触发eventProcessLoop.post(JobSubmitted(jobId, rdd, func2, partitions.toArray, callSite, waiter, ...))waiter}
DAGScheduler.scala:1043 的 runJob 进一步对 submitJob 包了一层同步等待。下面是简化后的伪代码,重点看 submitJob → await completionFuture 这个结构:
def runJob[T, U](...): Unit = {val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)waiter.completionFuture.value.get match {case scala.util.Success(_) => // job succeededcase scala.util.Failure(exception) => throw exception}}
五、handleJobSubmitted:Stage 划分
事件循环最终调度到 handleJobSubmitted。DAGScheduler.scala:1400。下面是简化后的伪代码:
private[scheduler] def handleJobSubmitted(jobId: Int, finalRDD: RDD[_], func: ...,partitions: Array[Int], callSite: ..., listener: ...,properties: Properties): Unit = {val finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)val job = new ActiveJob(jobId, finalStage, callSite, listener, artifacts, properties)submitStage(finalStage)submitWaitingStages()}
Stage 划分的核心逻辑在 getMissingParentStages(DAGScheduler.scala:837)。它的规则可以用一句话概括:
从最后一个 RDD 往前推,碰到宽依赖(ShuffleDependency)就切开,创建一个新的 Stage。
具体说:
createResultStage→ 从 finalRDD 倒推,找到最上游的 ShuffleDependency 边界每切一次创建
ShuffleMapStage,最后一个 stage 创建ResultStage每个 ShuffleMapStage 的输出被 Shuffle 持久化,结果可以被下游 Reuse
ResultStage 直接用 func 计算并返回给 Driver
这决定了 Stage 什么时候可以并行:
同一个 Stage 里的 Task 并发执行,但不跨机器 shuffle
不同 Stage 之间串行:上一个 Stage 的全部 Task 完成后,下一个 Stage 的 Task 才开始
六、submitStage:递归提交父 Stage
DAGScheduler.scala:1540。下面是简化后的伪代码:
private def submitStage(stage: Stage): Unit = {val missing = getMissingParentStages(stage).sortBy(_.id)if (missing.isEmpty) {submitMissingTasks(stage, jobId.get)} else {for (parent <- missing) {submitStage(parent) // 先递归提交父 Stage}waitingStages += stage // 当前 Stage 进入等待队列}}
这段代码很关键:
submitStage会递归调用自己遇到父 Stage 还没提交,就先提交父 Stage
直到某个 Stage 的所有依赖都已经就绪,才真正执行
submitMissingTasks下发 Task
七、submitMissingTasks:创建 Task 对象
DAGScheduler.scala:1635:
当发现某个 Stage 的所有父 Stage 执行完毕、数据(ShuffleMapStage 的输出)已经可用,就会创建具体的 Task 对象。下面是简化后的伪代码:
private def submitMissingTasks(stage: Stage, jobId: Int): Unit = {val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()// 序列化 RDD + func/shuffleDep 并 broadcast// ...val tasks: Seq[Task[_]] = stage match {case stage: ShuffleMapStage =>partitionsToCompute.map { id =>new ShuffleMapTask(stage.id, ..., taskBinary, part, ...)}case stage: ResultStage =>partitionsToCompute.map { id =>new ResultTask(stage.id, ..., taskBinary, part, ...)}}taskScheduler.submitTasks(new TaskSet(tasks.toArray, stage.id, stage.latestInfo.attemptNumber(), jobId, ...))}
两个关键细节:
Task 的种类对应 Stage 的种类:
| Stage 类型 | Task 类型 | 输出 |
|---|---|---|
ShuffleMapStage | ShuffleMapTask | MapStatus(元数据,不包含数据本身) |
ResultStage | ResultTask | 用户 func 的返回值 |
Task 的序列化是在 Driver 端完成的:taskBinary 是 Broadcast[Array[Byte]],包含 RDD + ShuffleDependency / func 的序列化字节,通过广播变量分发到所有 Executor。
八、TaskSchedulerImpl.submitTasks:进入调度层
TaskSchedulerImpl.scala:243。下面是简化后的伪代码:
override def submitTasks(taskSet: TaskSet): Unit = {val manager = createTaskSetManager(taskSet, maxTaskFailures)// 注册到调度池schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)// 通知 backend 分配资源backend.reviveOffers()}
这里做了三件事:
为这个 TaskSet 创建
TaskSetManager—— 负责跟踪每个 Task 的状态、失败重试、推测执行把 TaskSetManager 注册到调度池(FIFO / Fair)—— 决定了多 Job 时的优先级
backend.reviveOffers()—— 向集群管理器(Standalone / YARN / K8s)发送信号:"有新的 Task 要跑了,过来分配资源"
backend 就是 SchedulerBackend。它的实现取决于部署模式:
LocalSchedulerBackend(本地模式)StandaloneSchedulerBackend(Standalone 集群)CoarseGrainedSchedulerBackend(YARN / K8s)
九、resourceOffers:把 Task 分配给 Executor
集群管理器分配资源后,TaskSchedulerImpl.resourceOffers(TaskSchedulerImpl.scala:512)会被调用:
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = {// 打乱 offer 顺序(负载均衡)val shuffledOffers = shuffleOffers(filteredOffers)// 轮询每个 TaskSetManager,获取它想要的 Taskfor (taskSet <- sortedTaskSets) {// TaskSetManager 根据数据本地性(PROCESS_LOCAL > NODE_LOCAL > RACK_LOCAL > ANY)选择 Task}}
TaskSetManager 内部维护了每个 Task 的数据本地性等级。它尽可能让 Task 在数据所在的 Executor 上运行,避免网络传输。
最终产出的是 Seq[TaskDescription]——每个 TaskDescription 包含了:
Task ID
Executor ID
序列化的 Task 二进制数据
这会被 CoarseGrainedSchedulerBackend 通过网络发送给对应的 Executor。
十、Executor.launchTask → TaskRunner.run:在 Executor 上真正跑起来
Executor.scala:551:
def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = {val tr = createTaskRunner(context, taskDescription)runningTasks.put(taskId, tr)threadPool.execute(tr)}
TaskRunner(Executor.scala:687)是一个 Runnable。它的 run() 方法做的事:
反序列化
taskDescription.serializedTask得到真正的Task对象调用
Task.run(taskAttemptId, attemptNumber, ...)(Task.scala:87)Task.run内部调用runTask(context)的多态实现
对于 ResultTask(ResultTask.scala:78):
override def runTask(context: TaskContext): U = {val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](ByteBuffer.wrap(taskBinary.value), ...)func(context, rdd.iterator(partition, context))}
对于 ShuffleMapTask(ShuffleMapTask.scala:82):
override def runTask(context: TaskContext): MapStatus = {val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](ByteBuffer.wrap(taskBinary.value), ...)// 计算结果写入 shuffle,返回 MapStatusval writer = dep.shuffleHandle.asInstanceOf[BaseShuffleHandle[_, _, _]].shuffleWriterProcessor.createWriter(...)writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])Option(writer.stop(success = true)).orNull}
十一、结果回传
Task 执行完毕后,结果会通过 ExecutorBackend.statusUpdate 发送回 Driver。
ShuffleMapTask返回MapStatus(告诉 Driver:我这边的数据写到哪里了、每个 reducer 拉取的数据量是多少)ResultTask返回的是序列化后的用户函数结果
Driver 端 DAGScheduler.handleTaskCompletion(DAGScheduler.scala:2203)处理结果:
如果是
ResultTask完成且全部结束 → Job 成功如果是
ShuffleMapTask完成 → 检查此 ShuffleMapStage 是否全部完成,是则提交下游 Stage
十二、实战:把整条调用链看一遍
// 准备val rdd = sc.parallelize(1 to 100, 4)// 第一步:RDD actionprintln("Before count()")val count = rdd.count()println(s"count = $count")// 第二步:用 RDD.toDebugString 看 Stage 和依赖println("\nRDD Lineage:")println(rdd.toDebugString)// 第三步:看 Job 的 stage 信息// 注意:需要先设置 spark.ui.enabled = false,不然需要在 Web UI 上看println("\nDone")
输出:
Before count()
count = 100
RDD Lineage:
(4) ParallelCollectionRDD[0] at parallelize at RDDtest02.scala:41 []
Done
更直观的方式是开起 Spark Web UI 看 Job 视图:
http://localhost:4040/jobs/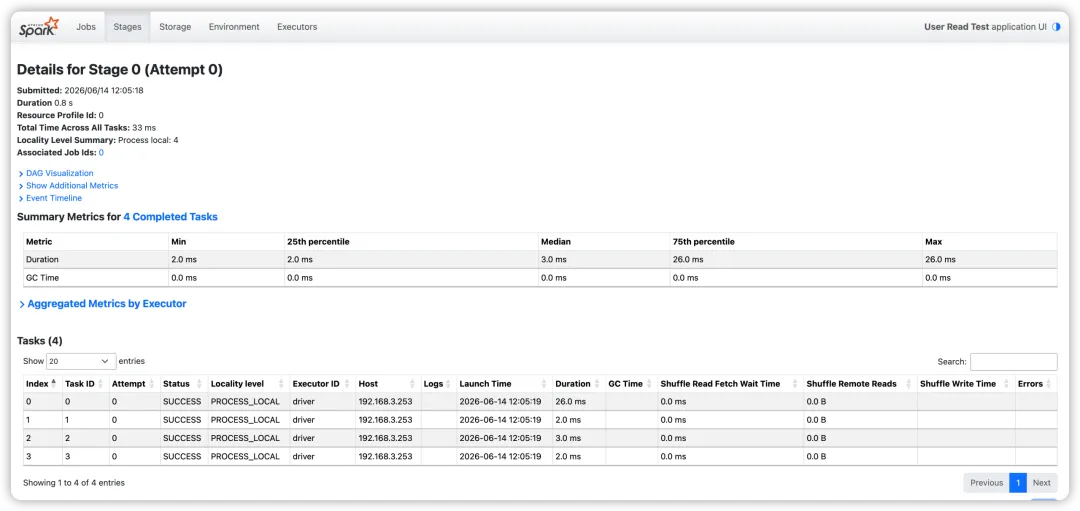
你会看到一个 Job(ID 0),展开能看到:
1 个 ResultStage
4 个 Task
每个 Task 的状态、时长、所在 Executor
十三、收尾
从 rdd.count() 到真正的 Task 在 Executor 上跑起来,完整调用链:
rdd.count()→ SparkContext.runJob:2481→ DAGScheduler.submitJob:984→ eventProcessLoop.post(JobSubmitted) ← 事件循环入口→ handleJobSubmitted:1400→ createResultStage:704 ← 创建 ResultStage→ submitStage:1540 ← 递归提交父 Stage→ getMissingParentStages:837 ← Stage 划分(按 Shuffle 边界切)→ submitMissingTasks:1635 ← 创建 Task 对象→ new ResultTask / ShuffleMapTask→ taskScheduler.submitTasks:243 ← 进入调度层→ backend.reviveOffers()→ resourceOffers:512 ← 分配 Task 到 Executor→ Executor.launchTask:551→ TaskRunner.run:806→ Task.run:87→ ResultTask.runTask:78→ rdd.iterator(partition, context)
最值得带走的三个认知:
DAGScheduler 不只负责"切 Stage"。它还协调了 Job 的完整生命周期:事件循环 → Stage 划分 → 父 Stage 递归提交 → Task 创建 → 结果处理 → Stage 推进。事件循环的设计让所有操作单线程串行化,避免了并发管理的复杂度。
Stage 的本质是一组无需 shuffle 的 Task。shuffle 依赖是 Spark 唯一"不得不串行"的边界,所以每个 shuffle 边界会天然形成一个 Stage 边界。同一个 Stage 内的所有 Task 可以并发跑。
Task 在 Driver 端序列化,在 Executor 端反序列化执行。
taskBinary是一个 Broadcast,包含 RDD + func/ShuffleDependency 的全量数据。这就是 Task 隔离性(分段执行、互不干扰)的来源,也是 Task Not Serializable 错误的源头。
每天花费10分钟学习spark,让你技术之路走得更稳、更快。
喜欢的点个关注。
