 夜雨聆风
夜雨聆风上周,HackerNews上一篇「如何在Mac上搭建本地AI编程助手」获得了468个点赞。作者用llama.cpp + Gemma 4 26B + MTP推测解码,在M1 Max上跑出了72 tokens/s的速度——而且完全免费。今天我把这个方法完整拆解,带你一步步复现。
🔍 这是什么?为什么值得关注?
这是一套完全免费的本地AI编程助手方案,核心组件:
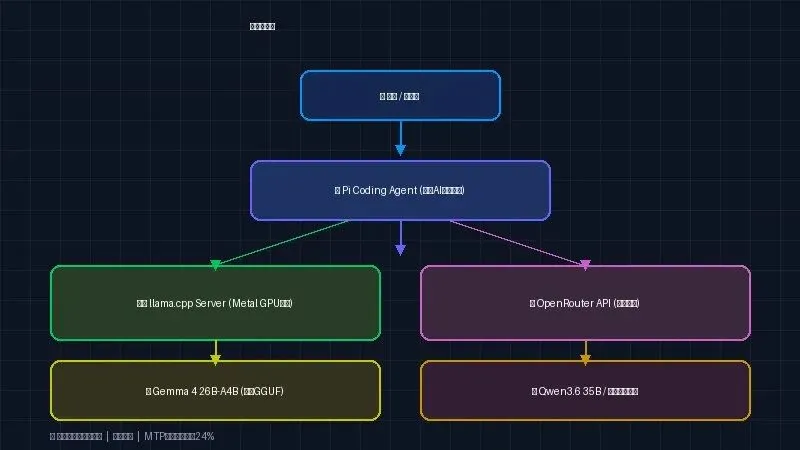
🤖 Pi Coding Agent — 开源终端AI编程助手,支持任何OpenAI兼容API ⚙️ llama.cpp — 高性能LLM推理引擎,支持Apple Metal GPU加速 🧠 Gemma 4 26B-A4B — Google开源MoE模型,仅3.8B参数激活,性能接近31B 🚀 MTP推测解码 — 用小模型草稿+大模型验证,提速24% 🌐 OpenRouter免费API — 云端备选,26个免费模型随时切换
⚡ 实测性能:72.2 tokens/s(MTP加速)| 58.2 tokens/s(基础)
测试平台:Apple M1 Max 64GB | 模型:Gemma 4 26B-A4B Q4量化
🏗️ 系统架构
整体架构分四层:用户 → Pi Agent → llama.cpp/OpenRouter → 模型。本地优先,云端补充。
📋 环境要求
- 硬件:
Apple Silicon Mac(M1/M2/M3/M4),建议32GB+统一内存 - 系统:
macOS 14+ - 内存:
最低16GB(跑26B模型需32GB+以获得足够上下文) - 磁盘:
至少20GB可用空间(模型文件约16GB) - 软件:
Xcode Command Line Tools、CMake、Python 3.10+
🛠️ 完整搭建步骤
步骤1:安装依赖
# 安装 Xcode Command Line Tools xcode-select --install # 安装 Homebrew(如未安装) /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)" # 安装 CMake 和 Python 依赖 brew install cmake python@3.11 pip3 install huggingface-hub 步骤2:编译 llama.cpp(Metal GPU加速)
# 克隆仓库 git clone https://github.com/ggerganov/llama.cpp cd llama.cpp # 编译(Metal GPU加速默认开启) cmake -B build -DCMAKE_BUILD_TYPE=Release cmake --build build --config Release -j $(sysctl -n hw.ncpu) # 验证编译成功 ls build/bin/llama-cli ls build/bin/llama-server 步骤3:下载 Gemma 4 26B 模型
# 创建模型目录 mkdir -p models cd models # 下载主模型(~16GB,Q4_K_XL量化) huggingface-cli download unsloth/gemma-4-26B-A4B-it-GGUF \ gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf \ --local-dir . # 下载MTP草稿模型(~1GB,用于推测解码加速) huggingface-cli download unsloth/gemma-4-26B-A4B-it-GGUF \ MTP/gemma-4-26B-A4B-it-Q8_0-MTP.gguf \ --local-dir . # 下载多模态投影器(如需图片输入) huggingface-cli download unsloth/gemma-4-26B-A4B-it-GGUF \ mmproj-gemma-4-26B-A4B-it.gguf \ --local-dir . 步骤4:启动 llama.cpp Server
# 启动服务(Metal GPU加速 + MTP推测解码) ./build/bin/llama-server \ -m models/gemma-4-26B-A4B-it-UD-Q4_K_XL.gguf \ --model-draft models/MTP/gemma-4-26B-A4B-it-Q8_0-MTP.gguf \ --spec-type draft-mtp \ --spec-draft-n-max 3 \ -ngl 999 \ -fa on \ -c 4096 \ --host 0.0.0.0 \ --port 8080 # 参数说明: # -ngl 999 → 所有层放GPU # -fa on → 启用Flash Attention # -c 4096 → 上下文长度 # --spec-draft-n-max 3 → MTP草稿token数(1-6,3最优) 步骤5:安装 Pi Coding Agent
# 安装 Pi(Node.js 18+) npm install -g @earendil-works/pi-coding-agent # 验证安装 pi --version 步骤6:配置 Pi 使用本地模型
# 方式A:使用本地 llama.cpp pi --model openai/gemma-4-26b-a4b-it:free \ --base-url http://localhost:8080/v1 # 方式B:使用 OpenRouter 免费API(无需本地模型) pi --model openai/gemma-4-26b-a4b-it:free \ --base-url https://openrouter.ai/api/v1 \ --api-key YOUR_OPENROUTER_KEY # 方式C:使用 OpenRouter 完全免费模型(无需API Key) pi --model google/gemma-4-26b-a4b-it:free \ --base-url https://openrouter.ai/api/v1 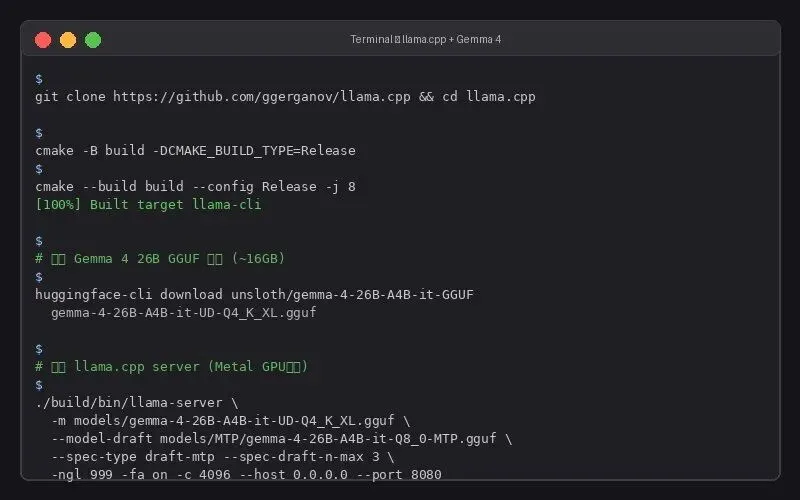
✅ 验证成功
启动后,在终端中输入问题,AI应该能正常回复。验证命令:
# 测试 API 是否正常工作 curl http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma-4-26b-a4b-it", "messages": [{"role": "user", "content": "用Python写一个快速排序"}], "max_tokens": 256 }' # 预期返回:JSON中包含 choices[0].message.content,内容是快速排序代码 ⚠️ 常见问题 & 踩坑点
- ❓ 模型下载太慢?
使用 huggingface-cli download支持断点续传。也可以从 hf-mirror.com 镜像下载。 - ❓ 内存不够?
换更小的量化版本(Q3_K_M约12GB,Q2_K约8GB),或换用更小的模型如Gemma 4 11B。 - ❓ MTP不生效?
确认草稿模型路径正确, --spec-draft-n-max从1到6逐个测试,不同硬件最优值不同。 - ❓ Pi连接失败?
检查llama.cpp server是否正在运行( curl http://localhost:8080/health),确认端口未被占用。 - ❓ 速度太慢?
确保 -ngl 999开启了GPU加速。用-ngl 0可强制CPU模式对比。 - ❓ 想要多模态?
添加 --mmproj models/mmproj-gemma-4-26B-A4B-it.gguf参数启用图片输入。
💰 成本对比
| ¥0 | |||
| ¥0 | |||
📝 总结
这套方案的核心思路是「本地优先,云端补充」:
🏠 本地运行:llama.cpp + Gemma 4 26B,零成本,数据不出本机 🚀 MTP加速:推测解码提升24%速度,72 tokens/s完全可用 🌐 云端备选:OpenRouter 26个免费模型,本地不够用时无缝切换 🤖 Pi Agent:开源编程助手,支持工具调用、代码编辑、多轮对话
整个过程完全免费,不需要任何API Key,不需要信用卡。如果你有一台Apple Silicon Mac,今天就能跑起来。
📱 关注「溜回几千里」
每周分享AI实战教程 · 开源工具 · 免费资源
觉得有用?转发给需要的朋友 🚀
