 夜雨聆风
夜雨聆风内容摘要
OpenDataLoader PDF 面向 RAG、文档解析和 PDF 无障碍自动化,支持 Markdown、JSON、HTML、Tagged PDF 输出。

一、为什么 PDF 解析还值得单独关注
RAG 做到文档场景时,PDF 往往是最麻烦的数据源:阅读顺序乱、表格断裂、双栏论文串行、图片和图表缺描述、扫描件还要 OCR。把 PDF 简单转成纯文本,通常会丢掉很多对检索和溯源有用的信息。
OpenDataLoader PDF 的定位正是解决这个问题:把 PDF 转成 AI 更容易消费的结构化数据,同时把 PDF 无障碍自动化也纳入同一条管线。
项目地址:https://github.com/opendataloader-project/opendataloader-pdf

二、它输出的不只是文本
README 里对输出能力写得很明确:Markdown、JSON、HTML、Tagged PDF,以及企业版 PDF/UA。对 AI 应用来说,最关键的是 JSON with bounding boxes:每个元素带坐标,意味着你不仅知道“抽出了什么文本”,还知道它在原 PDF 的什么位置。
这对 RAG 有三点实际价值:
- 更容易做引用溯源:回答可以关联到页面区域,而不只是某段文本。
- 更容易处理表格和多栏:结构信息比纯文本更接近原文档。
3. 更容易做人工复核:当抽取结果可视化回原文位置,排错成本会低很多。
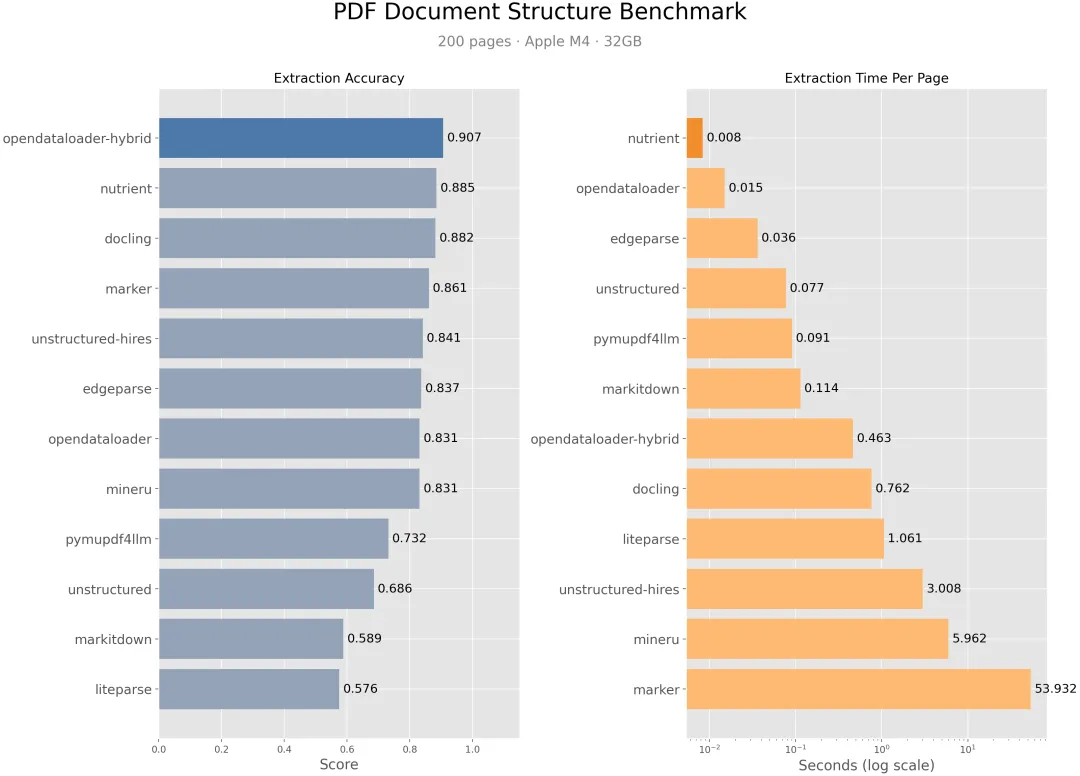
三、基准测试数据很激进
项目 README 称,opendataloader-pdf 在 hybrid 模式下综合抽取准确率为 0.907,表格抽取准确率为 0.928,并在 benchmark 中排名第一;local mode 则强调 0.015s/page 的速度表现。
这些数字当然需要结合自己的文档集再验证,但它说明项目目标不是“能转 Markdown 就行”,而是在阅读顺序、表格、标题等关键指标上做系统性优化。
四、Hybrid 模式:简单页面本地跑,复杂页面交给 AI
OpenDataLoader PDF 的设计不是把所有页面都丢给大模型,而是区分场景:简单页面走本地 Java 处理,复杂表格、扫描件、公式、图表描述等场景可以走 hybrid 模式。
README 里给出的场景包括:
- 复杂或嵌套表格:Hybrid;
- 扫描版 PDF:Hybrid + OCR;
- 非英文扫描件:Hybrid + OCR 语言参数;
- 数学公式:Hybrid + formula;
- 图表需要描述:Hybrid + picture description;
- 需要无障碍的未标记 PDF:输出 Tagged PDF。
这个分层思路比较务实:不是所有文档都需要 AI,但复杂 PDF 又确实很难只靠传统解析规则解决。
五、30 秒上手路径
Python 入口很直接,要求 Java 11+ 和 Python 3.10+:
pip install opendataloader-pdf批量转换时,README 特别提醒:每次 convert() 会启动 JVM,所以应尽量一次传入多个文件,而不是循环逐个调用。
import opendataloader_pdfopendataloader_pdf.convert( input_path=["file1.pdf", "file2.pdf"], output_format="markdown")除了 Python,它也提供 Node.js 和 Java SDK,对已经在后端系统里处理文档的团队更友好。
六、另一个重点:PDF 无障碍自动化
这个项目不只是 PDF Parser。它还把 auto-tagging 做进开源核心:未标记 PDF 可以生成 Tagged PDF,作为 PDF/UA 工作流的基础。
这对企业文档很现实。大量历史 PDF 并不适合屏幕阅读器,人工修复成本高,而且法规压力越来越强。OpenDataLoader PDF 的说法是:layout analysis + auto-tagging 属于 Apache 2.0 开源核心,PDF/UA-1 和 PDF/UA-2 export 则是企业版能力。
如果你只关心 RAG,它是解析器;如果你关心合规和无障碍,它又是自动化 remediation 管线的一部分。
七、适合谁评估
我会优先推荐这些场景试用:
- 企业知识库、合同、研报、论文等 PDF 密集型 RAG;
- 需要表格、公式、图片说明和阅读顺序的高质量抽取;
- 希望 JSON 中带 bounding boxes,便于溯源和复核;
- 批量 PDF 需要自动生成 Tagged PDF;
- 团队需要 Python、Node.js、Java 多语言接入。
不适合的场景也很清楚:如果只是偶尔把简单 PDF 转成文本,轻量工具可能更省事;如果对 PDF/UA 完整合规有强需求,也要注意 README 中企业版边界。
八、我的判断
OpenDataLoader PDF 的亮点,是把“AI 数据抽取”和“PDF 无障碍自动化”放在一个项目里,而不是做成两条互不相干的管线。
对 AI 应用来说,它值得关注的不是又多了一个 PDF 转 Markdown 工具,而是它把 bounding boxes、阅读顺序、表格质量、OCR、Hybrid AI、Tagged PDF 都放进了同一套工作流。对于严肃文档场景,这类能力会越来越像基础设施。
