 夜雨聆风
夜雨聆风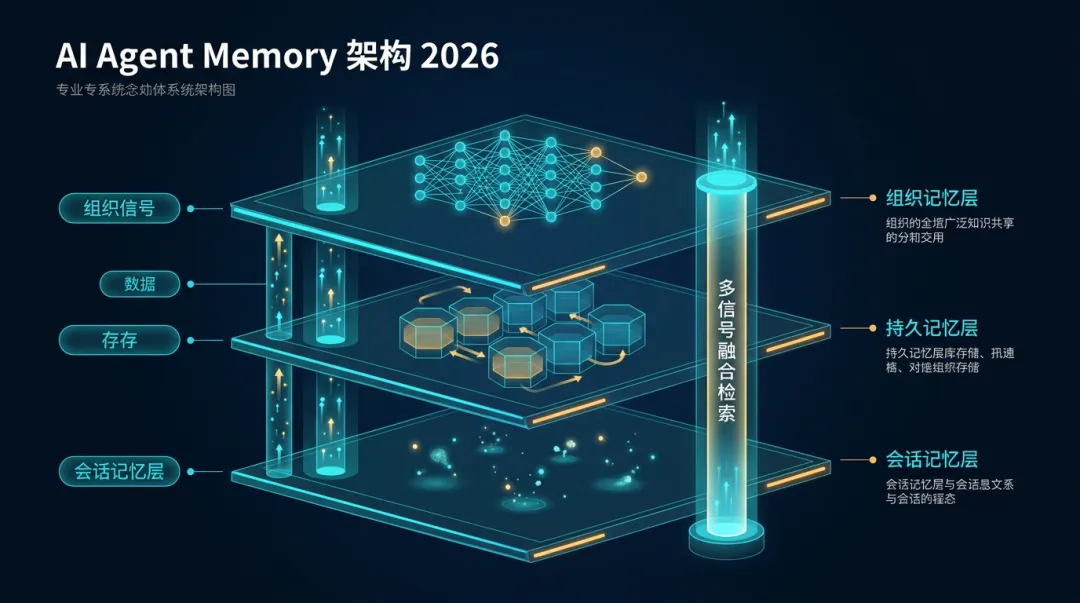
过去一周,你的 AI 编程 Agent 每次启动都要你重新解释项目结构吗?你的对话式 AI 产品每次会话都是"初次见面"吗?这背后是同一个根本问题——Agent 没有持久记忆。
2026 年 6 月,这个赛道发生了三件标志性事件:
Mem0 发布迄今最全面的《State of AI Agent Memory 2026》报告,覆盖 21 个 Agent 框架集成、20 个向量存储后端,以及三大标准化基准(LoCoMo、LongMemEval、BEAM)
MemPalace 以 96.6% R@5(零 API 调用、纯本地)登顶 LongMemEval 开源记忆系统,且明确警告了大量冒名诈骗网站,说明赛道热度已到新高度
agentmemory 凭借"一次安装,所有 Agent 共享"的产品策略,在 GitHub 快速攀升,成为 Claude Code / Copilot CLI / Codex CLI / Cursor 等主流 Agent 的内存后端
这不仅仅是三个项目的故事。这是 AI Agent 从"一次性会话工具"进化为"长期协作者"的关键基础设施变革。对正在探索 AI 产品的你而言,理解记忆层的架构选择、基准测试、集成生态和生产挑战,将直接影响产品体验设计和商业化决策。
AI Agent Memory 在 2026 年 6 月正式从"可有可无的附加功能"变为"生产级 Agent 的架构必选项"——三个标准化基准、21 个框架集成、多信号融合检索,标志着记忆层作为独立基础设施层的成熟。
什么是 AI Agent Memory?
AI Agent Memory 是指让大语言模型驱动的 Agent 能够跨会话、跨任务保持上下文和知识的能力。与传统的数据库不同,Agent Memory 需要处理:
非结构化对话历史的压缩和检索
跨会话身份和偏好的持续追踪
知识更新和废弃的时间感知
多 Agent 共享记忆的隔离与协同
2026 年之前,开发者主要依靠"把所有历史塞进上下文窗口"来模拟记忆。这种方式在会话超过 3-5 轮后迅速失效(成本随上下文长度线性增长,质量反比下降)。
2026 年的格局变化
三个标准化基准的出现(LoCoMo、LongMemEval、BEAM)使得不同架构的记忆系统可以公平比较。记忆性能首次有了"可衡量、可复现"的标准。
与此同时,21 个 Agent 框架和 20 个向量存储后端的集成,意味着记忆层正在从"每个团队自己造轮子"走向"标准化基础设施"。
技术/产品拆解
1. 三大基准:记忆系统的"高考"
2026 年,AI Agent Memory 领域形成了三个公认的标准化基准:
基准 | 题量 | 考核维度 | 最独特之处 |
LoCoMo | 1,540 题 | 单跳/多跳/开放域/时序记忆 | 跨多会话对话数据 |
LongMemEval | 500 题 | 用户记忆/助理记忆/知识更新/时序推理/多会话 | 更广的记忆场景范围 |
BEAM | 100 万级 token | 偏好遵循/指令遵循/信息提取/矛盾检测/事件排序 | 生产级数据规模(不可靠扩窗口解决) |
这三个基准的共同特点是:不只看准确率,还看 Token 消耗和延迟。一个需要 26,000 Tokens/查询的系统不是生产可行的——这正是 2026 年记忆系统的核心工程挑战。
2. Mem0:记忆基础设施的"标准件"
Mem0 是当前集成最广的记忆层。其核心架构:
四层作用域模型:
user_id(跨会话个人记忆)、agent_id(特定 Agent 实例)、run_id/session_id(单次会话)、app_id/org_id(组织级上下文)多信号检索:语义相似度 + BM25 关键词匹配 + 实体匹配,三路并行评分后融合
单通道只添加提取:Agent 生成的事实作为一等公民存储,Agent 确认和建议与用户陈述等权
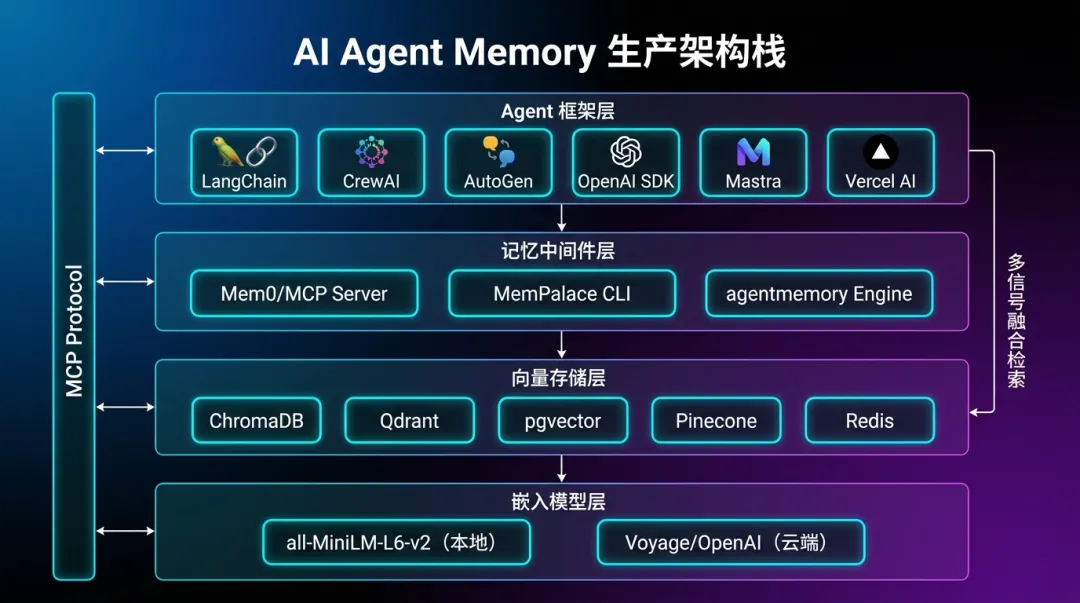
集成生态:LangChain、LangGraph、LlamaIndex、CrewAI、AutoGen、OpenAI Agents SDK、Google ADK、Mastra(TypeScript 原生)、Vercel AI SDK、ElevenLabs(语音 Agent)
Mem0 在 LongMemEval 上得分为 94.4%,在 BEAM(10M token 规模)上表现稳定。其最新算法相比 2025 年版本,时序推理提升 29.6 个点、多跳推理提升 23.1 个点——这正是 Agent 处理真实用户历史最需要的两项能力。
3. MemPalace:纯本地的"隐私优先"路线
MemPalace 采取了截然不同的技术路线:
原样存储 + 语义搜索:不摘要、不提取、不改写,直接存储对话历史原文
结构索引:人物/项目→"翅膀"(wing),主题→"房间"(room),原始内容→"抽屉"(drawer)
可插拔后端:默认 ChromaDB,支持 Qdrant、pgvector、SQLite 精确搜索
零 API 调用:使用
all-MiniLM-L6-v2本地嵌入模型,完全离线运行
MemPalace 在 LongMemEval 上的 R@5 原始得分为 96.6%(纯语义搜索,无启发式,无 LLM),混合管道 v4 达到 98.4%。
值得注意:MemPalace 明确拒绝与其他项目做横向对比,认为"检索召回率不能与端到端问答准确率放在同一张表里比较"——这个立场本身也反映了记忆评估领域仍在快速演化。
4. agentmemory:工程化最彻底的"开箱即用"方案
agentmemory 走的是完全不同的路线——工程体验优先:
一条命令安装:
npm install -g @agentmemory/agentmemory所有 Agent 共享同一内存服务器:Claude Code、Copilot CLI、Codex CLI、Gemini CLI、Cursor 等通过 MCP 协议连接同一后端
自动捕获:12 个 Hook 零手动配置,自动记录 Agent 会话
内存生命周期管理:4 级合并 + 衰减 + 自动遗忘
约 1,900 Tokens/会话(每年约 $10)的极致 Token 效率
agentmemory 在 LongMemEval 上 R@5 得分为 95.2%,在比较表中覆盖了 agentmemory vs mem0、Letta/MemGPT、Khoj、supermemory、MemPalace、Hippo 六个竞品。
5. 架构趋势:从纯向量到多信号融合
2026 年最重要的架构趋势是:
向量 + 关键词 + 实体,三合一检索成为标配
Mem0 的多信号检索、agentmemory 的 BM25 + 向量 + 图谱 RRF 融合、MemPalace 的混合管道——三个项目不约而同地走向了多信号融合。纯粹依赖向量相似度已经不够用。
另一个趋势是图谱记忆的实用化:Mem0 在 2026 年版本中将外部图谱存储替换为内置实体链接,在 add()阶段解析实体并存入独立集合,检索时通过实体匹配提升相关记忆的排序权重。这避免了部署 Neo4j 实例的运维负担,同时获得了实体感知的检索能力。
商业化拆解
目标用户与付费场景
用户群 | 核心需求 | 付费场景 |
AI Agent 开发者 | 让 Agent "记住"用户和项目 | API 调用量(Mem0)/ 自托管降本 |
独立开发者 / 小团队 | 开箱即用的记忆方案 | 免费开源 + 云服务增值 |
企业 AI 平台团队 | 多 Agent 共享记忆、合规审计 | 托管服务 + SLA + 企业集成 |
AI 产品公司 | 用户个性化记忆持久化 | 按用户量/存储量/查询量分级 |
商业模式分析
Mem0(开源核心 + 云服务):
免费 API 层 + 按量付费云服务
21 个框架集成作为生态护城河
开发者从本地开发到生产部署的迁移路径
MemPalace(完全开源):
目前仅开源,无云服务
零 API 调用、纯本地运行作为差异化卖点
未来可能的变现方向:企业托管版本、MCP 服务增值
agentmemory(开源核心 + MCP 生态):
开源引擎 + 15 个原生 Skills(8 个可调用 + 7 个参考)
"一次安装,所有 Agent 共享"降低切换成本
通过
iii-engine底层做差异化
竞争壁垒
基于公开信息推测,记忆层的竞争壁垒可能来自:
集成深度:覆盖的 Agent 框架和工具链越多,切换成本越高
基准表现:在标准基准上的可验证性能差异
Token 效率:每查询消耗的 Token 越少,生产部署成本越低
生态锁定:Mem0 已集成二十多个框架,agentmemory 的 15 个原生 Skills 都增加了用户粘性
成本结构
基于 2026 年 6 月数据:
Mem0 单查询约 6,900 Tokens(vs 2025 年全上下文约 26,000 Tokens,效率提升约 3.8 倍)
agentmemory 单会话约 1,900 Tokens(约 $10/年)
MemPalace 零 API 成本(纯本地运行)
记忆层的成本优势主要来自选择性检索而非全量上下文注入,这也是该赛道的核心价值主张。
创新产品模式启发
1. "记忆即基础设施"的产品定位
记忆层不是一个功能,而是一个独立的基础设施层。可以类比数据库在 Web 应用中的角色——不是"可选的附加功能",而是架构的核心。如果你的 AI 产品还没有独立的记忆层,它可能很快就会落后。
2. 四层作用域模型是产品设计的模板
Mem0 的 user_id/ agent_id/ session_id/ app_id四层作用域模型可以迁移到任何 AI 产品中。产品设计时应明确:用户记忆什么时候跨会话保持?Agent 的"性格"和"知识"如何隔离?组织级上下文如何共享?
3. 多信号融合是产品体验的护城河
纯向量搜索已经不够了。语义 + 关键词 + 实体的三路融合检索,能显著提升记忆召回质量。这意味着产品团队需要同时投资嵌入模型质量、关键词索引结构和实体抽取能力。
4. "隐私优先"也是一个产品策略
MemPalace 的完全本地运行 + 零 API 调用,对于处理敏感数据的企业客户是强卖点。在 AI 产品中,记忆系统默认本地运行、可选云同步,可能是兼顾隐私和功能的最优方案。
5. Agent 共享记忆是多 Agent 产品的核心能力
agentmemory 的"所有 Agent 共享同一内存服务器"模式,为多 Agent 产品提供了参考架构——一个中央记忆层,所有 Agent 通过 MCP 协议读写,天然支持信息共享和隔离。
对用户的行动建议
值得试用的项目
Mem0(https://mem0.ai):如果你的产品需要集成多种Agent 框架,从 Mem0 开始——集成最广,文档最完整
MemPalace(https://github.com/MemPalace/mempalace):如果你的核心场景是本地隐私优先,用MemPalace
agentmemory(https://github.com/rohitg00/agentmemory):如果你只用1-2 个编程 Agent 工具,用 agentmemory,一条命令即开即用
可验证的小实验
在 Claude Code 中接入 agentmemory,对比"有记忆"和"无记忆"模式下完成同一个跨会话任务(如逐步搭建一个 Web 应用)的效率差异
用 Mem0 的免费层构建一个简单的 AI 聊天产品,测试在 10 轮对话后用户是否需要重复信息
在自己的 AI 项目中实现最简单的多信号检索(向量 + BM25),与纯向量检索对比召回率
可观察的数据指标
跨会话任务完成率:用户第二次使用时,完成任务的时间是否缩短
记忆注入率:Agent 在每次会话中主动注入多少历史记忆
记忆召回精度:用户是否需要在对话中重复已提供过的信息
可跟踪的公司/项目
Mem0(https://mem0.ai):跟踪其集成生态增长和基准数据更新
agentmemory(https://github.com/rohitg00/agentmemory):关注其MCP 协议实现和 Agent 兼容性
MemPalace(https://github.com/MemPalace/mempalace):关注其云服务模式的演进
Mastra(https://mastra.ai):TypeScript原生 Agent 框架 + Mem0 原生集成
记忆系统可能不成立的场景
超短交互场景(一次会话即完成全部任务):记忆系统的 ROI 几乎为零
高度结构化的业务系统(业务流程完全预定义):记忆系统的灵活性反而是负担,增加运维复杂度和成本
大规模多租户场景:记忆隔离是一个尚未完全解决的问题。如果每个用户一个记忆空间,千万用户级别的存储和检索性能可能成为瓶颈
适用边界
记忆不是万能的:记忆系统擅长"记住事实和偏好",但不擅长"推理和规划"。Agent 的主要智能仍来自底层模型
记忆时效性:记忆会过时。Mem0 报告指出,"记忆陈旧"(memory staleness)是仍然开放的研究问题
记忆与隐私的张力:跨会话记忆越强,用户隐私风险越大。GDPR 要求"被遗忘权"的实现并不简单
成本风险
如果 Agent 会话非常长(100 轮以上),即使选择性检索,累积的存储和查询成本也不可忽略
Mem0 云服务的定价可能随着功能增加而上调——开源自建 vs 托管服务的成本选择需要持续评估
