 夜雨聆风
夜雨聆风

摘要:麻省理工学院联合科研团队针对沿用近百年的随机效用模型(RUMs)完成理论与方法革新,证实传统两两对比的数据采集方式无法捕捉人类偏好间的关联特性,而三项选项排序模式可高效挖掘偏好相关性、提升模型精度。该成果不仅补齐推荐系统、行为预测算法的短板,还能优化大语言模型人类反馈训练流程,为电商、流媒体、公共决策、AI对齐等领域提供全新的数据采集与模型训练范式。
一、行业背景:百年模型遇瓶颈,两两对比存在先天缺陷
早在1927年,心理学家L.L.瑟斯顿提出比较判断定律,奠定了随机效用模型(RUMs)的理论基础。该模型可以量化人类主观偏好,通过选择行为推导不同选项带给人的价值,长期被广泛应用于用户行为预测、个性化推荐、公共政策推演、交通规划等诸多领域。
在近百年的落地实践中,行业普遍采用两两对比的数据采集模式:让用户在A、B两个选项中选出偏好项。这种方式操作简单、用户认知负担低,成为Netflix、亚马逊、搜索引擎等平台训练推荐算法,以及大模型人类反馈(RLHF)标注的主流选择。但该模式存在致命短板:默认不同选项的效用相互独立,无法挖掘偏好之间的内在关联MITNews。
举个典型例子:喜欢独立电影的用户,往往也偏爱外语片、排斥好莱坞商业大片;支持某项社会政策的人群,大概率认同配套福利举措。两两对比完全无法捕捉这类关联关系,最终导致AI推荐内容同质化、大模型输出风格贴合度不足、公共行为预测出现偏差,成为长期制约模型精度的核心痛点。
二、核心理论与技术创新
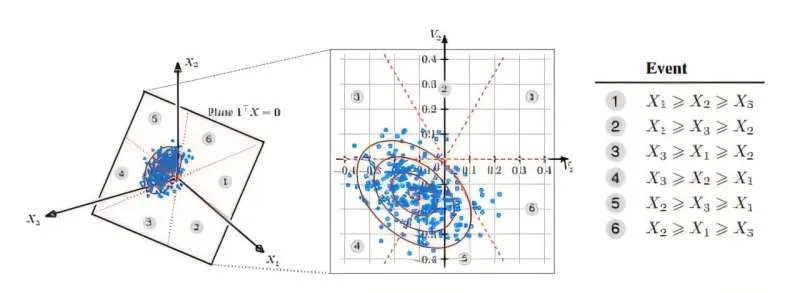
1.经典模型底层逻辑
随机效用模型(RUMs)核心是量化选择价值。人类无法给偏好打出精准数字,但会下意识选择效用最高的选项;同时个人偏好并非一成不变,会受场景、情绪影响,这也是模型带有“随机”属性的原因。长期以来,业界依赖两两对比数据训练模型,却忽略了该模式在关联特征提取上的理论盲区。
2.核心理论突破
MIT研究团队通过严格数学证明得出关键结论:仅依靠两两对比数据,永远无法识别不同偏好之间的相关性;而收集用户对三项选项的完整排序数据,能够精准捕捉偏好关联,完整还原人类决策逻辑MITNews。三项组合一共存在6种排序排列方式,团队通过划分平面区域统计不同排序的出现概率,即可量化选项间的关联强弱,填补了传统方法的信息缺失。此外,三项排序搭配少量两两对比数据,也能达到同等效果,兼顾数据丰富度与采集成本。
3.配套算法设计
团队同步研发适配三项排序数据的融合算法,重点解决两大问题:
数据聚合:将海量个体的三项排序结果整合为统一的全局偏好模型,提炼群体共性特征;
算力可控:随着商品、内容库规模扩大,所需实验与数据量呈多项式增长,而非指数级爆炸,保障系统在海量类目场景下可落地运行。
4.新旧采集方式对比
| 对比维度 | 传统两两对比 | 创新三项排序法 |
偏好关联捕捉 | 无法识别选项间关联,存在信息盲区 | 精准挖掘偏好相关性,还原决策逻辑 |
用户操作难度 | 低,仅需二选一 | 中等,完成三项优先级排序 |
数据信息密度 | 低,单条数据价值有限 | 高,单条数据包含多层偏好关系 |
扩展性 | 类目增多后偏差持续放大 | 类目扩容后算力可控,稳定性强 |
适配场景 | 简单偏好筛选 | 复杂推荐、AI对齐、行为预测 |
三、落地应用场景
1.互联网个性化推荐系统
流媒体平台、电商网站、资讯客户端是最核心的落地场景。借助三项排序数据训练模型,平台可以跳出“单一兴趣推送”的误区,理解用户兴趣组合特征,避免内容同质化推送,提升用户留存与使用时长。例如影视平台可根据观影偏好关联,组合推荐同类型、同风格影片,优化推荐体验MITNews。
2.大语言模型人类反馈训练(RLHF)
当前主流大模型依赖人工对多个输出结果做两两打分排序,以此训练奖励模型。改用三项排序模式后,标注数据能反映用户对文本风格、语气、内容的综合偏好关联,让奖励模型更贴合人类诉求,优化AI对齐效果,提升大模型对话、创作、问答的质量。
3.公共决策与城市规划
应用于交通疏导、财政分配、民生政策推演等场景。例如预判主干道封闭后民众的出行路线选择、分析财政拨款的最优分配方案。三项排序可更精准掌握公众集体偏好,辅助管理者做出更贴合民意的决策。
4.市场调研与产品选型
消费市场调研中,通过用户对三款产品、三种方案的排序,分析产品卖点之间的受众关联,指导产品迭代、营销策略制定,帮助企业精准定位目标客群。
四、技术价值与行业影响
1.理论层面:完善百年经典模型
本次研究从数学层面论证了两两对比的固有缺陷,为随机效用模型补上关键理论短板。延续近百年的研究框架得到系统性升级,为偏好建模、选择行为分析领域建立全新的研究基准。
2.产业层面:重构数据采集范式
对于互联网、AI行业而言,数据是模型的根基。三项排序模式用可控的采集成本,换取更高质量的标注数据,无需大规模改造现有算法框架,仅调整数据采集环节,就能显著提升推荐系统、奖励模型的精度,落地门槛低、收益明显。
3.AI领域:强化大模型对齐能力
AI对齐是大模型落地的核心环节,优质的人类偏好数据能让模型输出更符合人类价值观与使用习惯。该方法优化RLHF数据链路,成为提升大模型实用性的重要辅助手段,将长期影响通用大模型的迭代节奏。
4.通用价值:拓展行为预测边界
该方案不止局限于互联网与AI,还可广泛应用社会学、经济学、交通规划等领域,提升人类群体行为预测的准确率,为各行各业的决策分析提供更可靠的技术工具。
五、现存挑战与未来发展规划
1.当前技术短板
用户操作成本上升:相比简单二选一,三项排序需要用户思考优先级,部分场景会降低用户配合意愿,影响数据采集规模。
存量数据兼容问题:行业积累了海量两两对比历史数据,新旧数据融合、模型迁移需要额外适配工作。
细分场景适配:在极速选择、高频交互等轻量场景中,三项排序的流程略显繁琐,需要做轻量化改造。
2.后续迭代方向
混合采集模式:推行“三项排序+少量两两对比”的组合方案,平衡数据质量与用户体验,降低操作负担。
算法轻量化:优化数据融合与模型训练算法,降低中小平台的部署算力门槛。
场景定制优化:针对短视频、电商、大模型标注等不同场景,设计简化版排序交互界面,适配不同使用习惯。
行业标准推动:联合互联网、AI企业,逐步将三项排序纳入偏好数据采集的通用规范,形成行业共识。
六、总结与行业展望
从1927年随机效用模型诞生,到如今三项排序法完成革新,人类偏好建模走过了近百年历程。MIT团队的研究跳出了“二选一”的固有思维,用数学理论和工程算法证明:三项排序是破解偏好关联盲区、提升模型精度的高效路径。
短期来看,流媒体、电商、大模型厂商会率先试点该数据采集模式,在不大幅增加成本的前提下优化推荐与AI输出效果;中长期,三项排序结合传统两两对比的混合模式,将成为偏好建模领域的主流方案,渗透到更多行业。
在AI深度融入各行各业的当下,数据质量直接决定智能系统的上限。这项看似偏向基础方法论的突破,实则撬动了推荐系统、AI对齐、公共决策等多个领域的底层能力,将持续推动各类智能产品更懂人类偏好,实现从“被动匹配”到“精准预判”的升级。
 点击“阅读原文”查看更多
点击“阅读原文”查看更多