当前时间: 1970-01-01 08:00:00
分类:办公文件
评论(0)
AI的"失忆症",终于有人治了22K Star 爆火,一个新工具来了
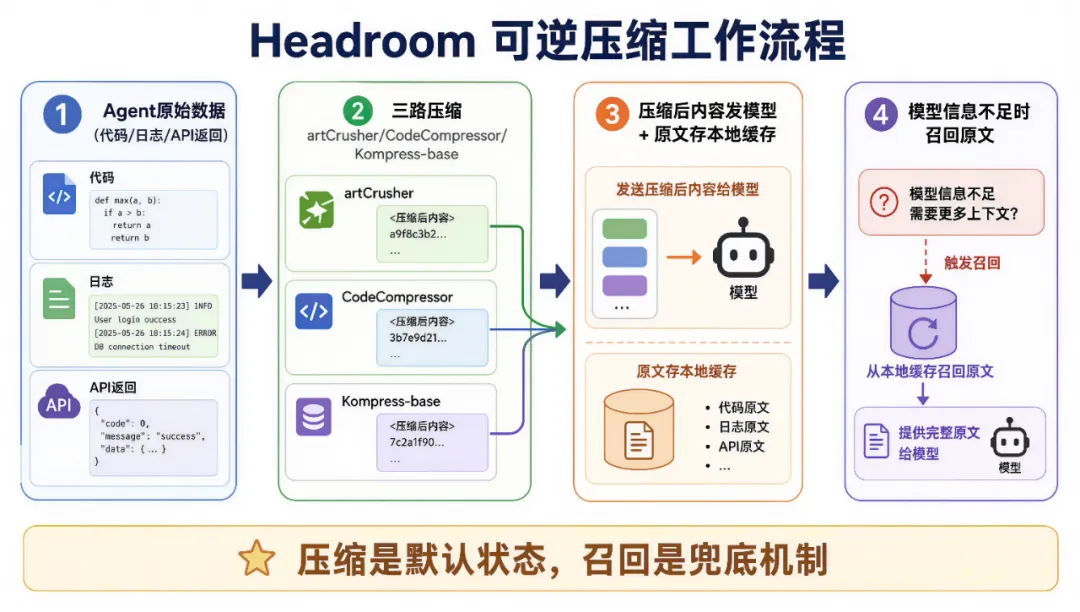
我这两个月重度用AI,在一个对话框里聊多了之后,它开始出现三个问题:第三,犯一些很低级的错误——比如把我们团队人员的名字叫错。行内人管这叫"上下文压缩"。但对使用者来说,就叫"AI失忆",或者更直接一点——"降智"。当AI开始成为工作流中的基础工具,一个被忽视德问题正在快速放大:上下文越来越长,Token越来越贵,但用起来却越来越笨。大量重复信息和低价值内容塞进对话框,不仅消耗Token,还会稀释模型对真正关键信息的关注度。塞得越多,响应越慢,成本越高,结果反而越差。最近,一个名为 Headroom 的开源项目在GitHub迅速走红,已经超过22.2K Star。它试图解决的正是这个问题。GitHub地址:https://github.com/chopratejas/headroom与其不断扩大上下文窗口,不如在数据进入模型之前,先把无价值内容压缩掉。可逆压缩:压缩是默认,召回是兜底
从架构上看,Headroom不是Agent框架,也不是新模型。它更像是一层插在Agent和大模型之间的中间件——官方叫它"Context Compression Layer"(上下文压缩层)。正常情况下,Agent会把日志、工具调用结果、代码内容和用户问题直接发给大模型。接入Headroom之后,这些内容先经过压缩处理,再进入模型。它不是简单的文本压缩器,而是针对不同内容走不同策略:API返回结果、数据库查询和JSON数据,交给 SmartCrusher 处理,过滤空字段、重复结构和冗余元数据,只保留有意义的业务信息。代码文件,用 CodeCompressor。它基于AST抽象语法树理解代码结构,保留函数关系和关键逻辑,删掉无关细节。Token大幅减少,但代码语义不丢。对话历史、日志和RAG检索结果,调用 Kompress-base 模型——专门训练的文本压缩模型,能识别错误信息、关键事件和重要上下文,同时过滤时间戳和噪声。但真证让Headroom区别于其他工具的,不是这些算法,而是CCR(Context Compression and Retrieval)。过去不管怎么压缩,本质上都意味着信息丢失——压完了就找不回来了。Headroom换了一种思路:压缩后的内容发给模型,完整原文保存在本地缓存里。如果模型推理时发现信息不足,可以通过检索机制重新获取原文。官方叫它"Reversible Compression"(可逆压缩)。这跟我做设计时控成本的逻辑一模一样——不是一味砍预算,而是把钱花在刀刃上。该留的留到位,该省的省到底。Cross-Agent Memory——团队同时用Claude、Codex、Gemini多个Agent时,可以共享同一个记忆库,实现跨Agent协作。headroom learn——自动分析历史会话中的失败案例,总结经验,写入 CLAUDE.md、AGENTS.md 等文件,相当于给Agent加了一套自动复盘系统。一条命令接入,几乎零代码
技术能力不是最大的障碍,改造成本才是。Headroom在设计时考虑到了这一点,提供了三种接入方式。Wrap模式——如果你在用Claude Code、Cursor、Codex或Aider,一条命令搞定:Proxy模式——适合已经上线的大模型应用。启动本地代理:headroom proxy --port 8787把原来的API地址替换为本地代理地址就行,业务代码几乎零改动。SDK模式——自研Agent团队可以直接在代码里调用,两三行代码就能接入。从体验来看,Headroom更像是在现有架构前加了一层缓存或者网关,而不是引入全新的基础设施。这也是它能快速拿到22.2K Star的原因——门槛极低。95% Token节省,准确率不变
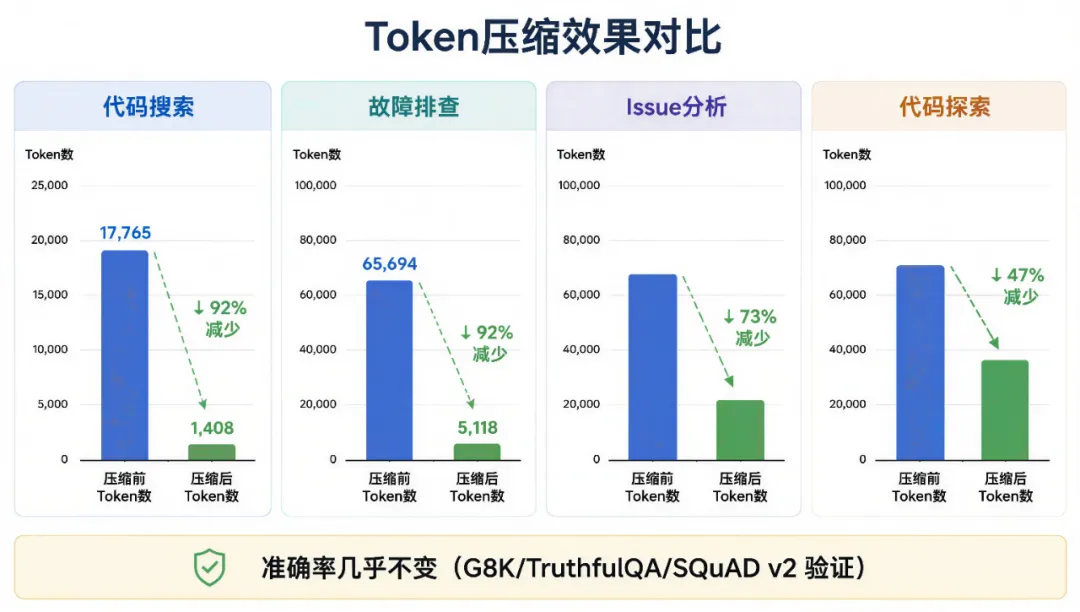
任何压缩工具最终都要回答一个问题:压缩之后,效果会不会变差?Headroom公布了一组真实Agent场景测试数据:代码搜索任务中,上下文从17765 Token压缩到1408 Token,节省92%。SRE故障排查场景,从65694 Token压缩到5118 Token,同样节省92%。GitHub Issue分析场景节省73%。代码库探索场景节省47%。在GSM8K、TruthfulQA、SQuAD v2等公开Benchmark上,压缩后与原始上下文基本保持一至,部分测试甚至略有提升。这意味着Headroom不是通过暴力删减内容来换取成本优势。它更像是在帮模型过滤噪声,让有限的注意力放在真正重要的信息上。AI不需要更长,需要更高效
随着AI Agent的普及,开发者面临的挑战正在发生变化。模型能力已经不是唯一瓶颈。代码文件、日志数据、RAG检索结果、工具调用记录、历史对话——这些内容正在持续推高上下文规模。当上下文越来越长,成本、延迟和效果都会受影响。所以,如何让模型读取更少但更有价值的信息,正在成为Agent系统优化的重要方向。Headroom提供的正是这样一种思路:不是让模型拥有更长的上下文,而是让模型拥有更高效的上下文。我用了两个月AI,最深的一个体会是:AI不是越"满"越好。塞给它越多,它越糊涂。真正好用的AI,是知道什么该记住、什么该放下。上下文管理的本质,不是技术的堆砌,而是对"什么才是真正重要的信息"这个问题的回答。AI的未来,不在于它能记住多少,而在于它能不能记住该记的。能看到这都是凤毛麟角的存在,如果觉得不错,随手点个赞、在看、转发三连吧,~谢谢您看我的文章,我们,下次再见。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-06-16 20:03:15 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/756899.html
- 运行时间 : 0.094959s [ 吞吐率:10.53req/s ] 内存消耗:4,815.86kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=1d959505f632050c232384463124394e
- CONNECT:[ UseTime:0.000549s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.000841s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000303s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000290s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.000479s ]
- SELECT * FROM `set` [ RunTime:0.000197s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.000514s ]
- SELECT * FROM `article` WHERE `id` = 756899 LIMIT 1 [ RunTime:0.000437s ]
- UPDATE `article` SET `lasttime` = 1781611395 WHERE `id` = 756899 [ RunTime:0.011075s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000246s ]
- SELECT * FROM `article` WHERE `id` < 756899 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.000397s ]
- SELECT * FROM `article` WHERE `id` > 756899 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.000695s ]
- SELECT * FROM `article` WHERE `id` < 756899 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.000919s ]
- SELECT * FROM `article` WHERE `id` < 756899 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.000808s ]
- SELECT * FROM `article` WHERE `id` < 756899 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.001000s ]

0.096631s

 夜雨聆风
夜雨聆风