 夜雨聆风
夜雨聆风一个关于"偷懒"的故事
如果你收到一沓厚厚的PDF,要求你在每一页的签名栏上签好字、填好日期,你会怎么做?
打开PDF编辑器,翻到第一页,把签名图拖进去,调整位置,填日期。然后翻到第二页,再拖,再调,再填。第三页、第四页……一共132页。
这,就是我上周接到的一个真实任务。
一、132页,纯手工要多久?
事情是这样的。三份发货清单,分别有22页、80页、30页,加起来正好132页。每页右下角有一个"发货人"签名栏——一条横线,等着签字。横线下面还有一行"日期:",等着填写。
签名有现成的——一张手机拍的签名照片。日期也不复杂,每页左上角"发货时间"后面写着。
如果纯手工操作,流程是这样的:
打开PDF → 翻到第一页 找到签名照片 → 抠出签名 → 调大小 → 拖到横线上 找到日期 → 逐字敲进去 翻下一页 → 重复步骤2-3 重复132次
保守估计,一页30秒。132页就是将近一小时的纯机械劳动。中间还得保证签名大小一致、位置对齐、日期不出错。
人干这种事,既慢又容易出错。
核心矛盾:
数量多(132页),手工逐页处理效率极低 签名是照片(有背景、方向不对),不能直接用 签名和日期位置必须准确对齐横线,否则不像正式签发的 不同PDF的页码布局有差异,不是简单的"同一位置粘贴"
二、让AI来解决,要分三步
这类问题,过去可能要写个专门的自动化脚本。但现在,直接跟AI描述需求就行。
我做的第一件事,是把三份PDF和签名照片一起丢给AI,写了一句话:
"提取签名照片上的人员签名字样,放在三份PDF每一页右下角'发货人'后面的横线上;每一页右下角'日期:',填每一页左上角'发货时间'后面的日期。"
就这一句话。没有写代码,没有画流程图,没有纠结"用哪个库"。
AI接收需求后,自动展开了三步工作:
🔹 第一步:签名提取
从一张手机拍的签名照片中,自动定位手写笔迹区域,抠掉纸张背景,生成透明底的高清签名图。
🔹 第二步:PDF精确定位
分析每份PDF的页面结构:找到"发货人"横线的精确坐标、找到"日期"文字的位置、提取每页左上角的"发货时间"日期。
🔹 第三步:批量填充
把签名放到横线上,把日期填到"日期:"后面,逐页处理,自动对齐。
其实还有一步——刚开始签名是竖着的(照片拍摄方向),AI还顺手把签名转成了横向,让它在横线上更自然。
三、签名提取:从一张照片到高清透明底
看似简单的一步,其实有几个隐形的坑。
签名照片是用手机拍的,画面上有纸张纹理、光影变化、微弱的底色。如果直接把整张照片放到PDF上,就像贴了一张小纸片,怎么看都不对。
坑1:怎么找到签名在照片中的位置?
照片里不只有签名,还有大面积的空白纸面。AI的做法是:扫描全图的像素亮度,寻找最暗的区域。手写笔迹是黑色/深色的,在灰度图中值最低,天然形成一个"热力分布"。
找到暗色像素聚集的区域后,自动裁剪出一个刚好包裹签名的最小矩形,再加少许边距——干净利落。
坑2:背景怎么去干净?
这是最讲究的一步。粗暴的做法是设一个阈值,低于某个值的像素保留,高于的直接变透明。但这样会让边缘变得锯齿状,就像把毛笔字用像素格强行描出来。
更好的做法是线性过渡:
# 不是非黑即白的二值化# 而是灰度到透明度的平滑映射alpha = clamp(255 × (1.0 - gray / 130.0), 0, 255)笔迹中心的像素(灰度值≈20)→ 几乎不透明;笔迹边缘的像素(灰度值≈100)→ 半透明;纸张空白(灰度值≈200)→ 完全透明。这样边缘就有了自然的抗锯齿过渡,视觉上像手写一样平滑。
坑3:方向不对
签名照片竖拍的,放到横线上得转90度。这一步倒是简单,但旋转后再缩放,又涉及到上一步的抗锯齿效果是否能保留。处理顺序有讲究:先转后缩,用LANCZOS算法保持边缘质量。
关键决策: 签名在PDF上的最终显示尺寸大约46×22像素。如果直接把源图缩到这个尺寸,细节损失严重。所以策略是:先缩放到一个中高分辨率(约332×160),让PyMuPDF引擎在最终渲染时再进行一次高质量缩小。多一次中间缩放,多保留一份细节。
四、PDF精确定位:找到那条横线
填签名最要命的问题:横线在哪?
PDF不是Word文档。Word里的元素有明确的名称和属性,PDF更像一张"画好的图纸"——文字是画上去的,横线也是画上去的,需要靠坐标来定位。
而且更麻烦的是:不同PDF的页面内容量不同。第一页可能只有几行数据,横线就跟着内容往前跑了;中间页数据多了,横线就推到了页面底部。
那怎么找?
策略:用直线段作为特征锚点
横线本质上是一条极短的水平线段。通过遍历PDF中所有的矢量绘图元素(drawings),快速筛选出水平线段(起止y坐标差小于2像素),再按x坐标范围过滤。这条签名横线的特征是:
这三份PDF虽然来自不同的系统导出,但这条签名横线的x坐标居然完全一致。这意味着:只要找到了这条线,签名就能精准就位。
找到横线后,签名居中放置,底部轻压横线——就像手写签字一样自然。
五、日期:自动抓取,一页不漏
日期在哪里?在每页左上角"发货时间"的后面。
有趣的是,这个日期并不是每一页都一样的。如果不同页对应不同发货批次,日期就会变化。所以不能偷懒填一个全局变量,得每页单独提取。
提取逻辑很简单:
扫描每页左上角区域(y≈88-108, x≈80-200)的文本 匹配正则 \d{4}\.\d{2}\.\d{2}(如 2026.06.17)找到后填入该页"日期:"后面
如果某页没找到,就跳过该页,不给错误信息增加噪音。
六、从脚本到工具:让所有人都能用
第一个版本处理完三份PDF后,我发现这其实是一个高频通用需求。任何需要批量在PDF上签名的场景——合同、发货单、报销单、确认函——都能用。
但命令行脚本对大多数人不友好。不是每个人都会打开终端敲 python fill_pdf.py。
所以我又做了第二件事:用一个完整的桌面程序把它包装起来。
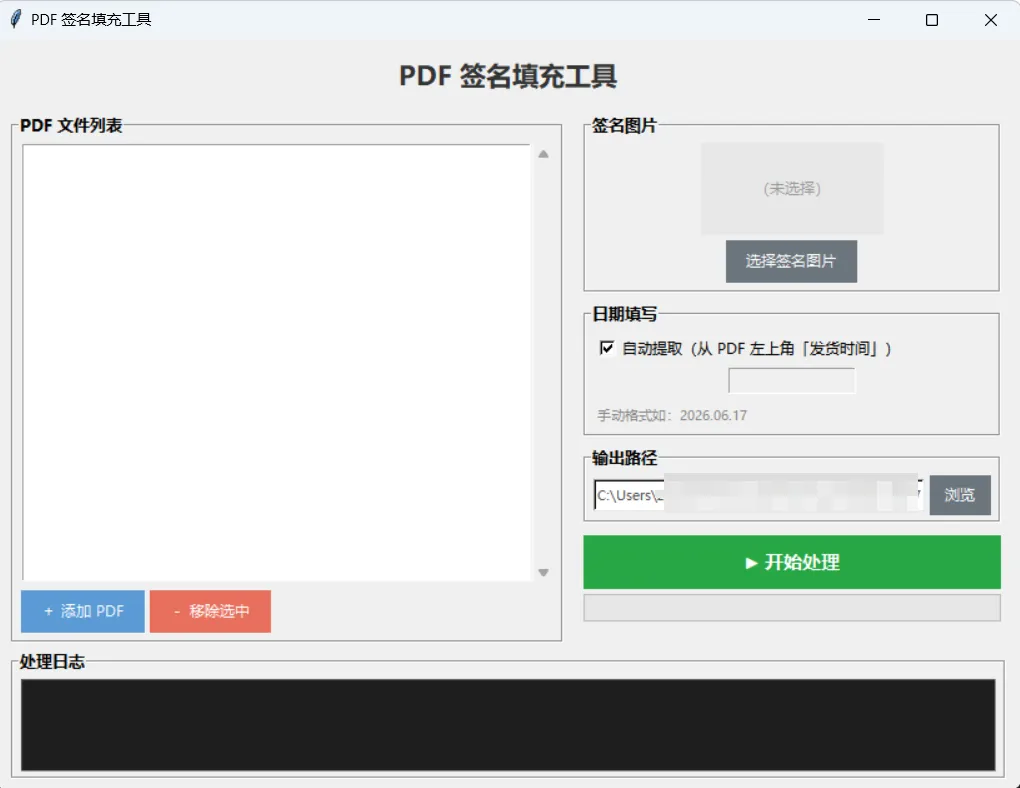
工具界面设计
整个工具不到400行Python代码,没有任何第三方UI框架依赖,用的是Python自带的 tkinter。双击运行即可,不需要安装任何额外的东西。
核心技术栈
PyMuPDF (fitz) — PDF 的底层操作:读取文本、遍历矢量图形、精确定位横线、插入图片和文字 Pillow (PIL) — 签名图片的全部处理:像素分析、抠图、旋转、缩放、锐化 NumPy — 加速像素级运算:灰度转换、暗色区域检测、Alpha通道计算 tkinter — 桌面界面:纯Python内置,零依赖
七、几个踩过的坑
坑1: 签名不清晰
第一版签名放在PDF上后,模糊得像打了马赛克。原因是源图分辨率太低,直接缩放丢失了太多细节。
解法:
提高中间分辨率(从80px → 160px),给渲染引擎更多像素去缩小 增加锐化步骤(UnsharpMask),强化笔迹边缘 alpha通道用线性映射代替硬阈值,保持抗锯齿
坑2: 中文文本提取乱码
PDF中"发货人"三个字用get_text()搜不到。原因是某些PDF使用自定义字体编码,内部存储的不是标准Unicode。
解法: 不依赖文字搜索,改用图形特征定位——横线的坐标特征(x≈466~515,水平短线)来间接定位签名区域。
坑3: 第1页和第N页布局不同
第1页内容少,横线在y≈261;第2页内容多了,横线被推到底部y≈742。横线x坐标一致但y坐标漂移,不能在代码里写死y值。
解法: 每页独立定位横线和日期标签,不做任何固定坐标假设。
八、这件事给我的启发
回想整个过程,有一个感受很强烈:
AI最大的价值不是替代人,是替代"不像人干的活"。
132页的机械复制粘贴,是机器该做的事。人的时间应该花在:判断签名是否合法、确认日期是否准确、检查整体合规性——这些需要经验和判断力的事。
以前,把这种需求变成自动化工具,可能要找开发同事排期,等一两周。现在,描述需求 → 验证结果 → 迭代优化 → 打包发布,全部在一小时内完成。
门槛的降低,让"自动化"从少数人的特权,变成了每个人的工具。
而这,可能才是AI最实用的那一面。
九、附:工具怎么用
如果你也有类似的PDF批量签名需求,工具的使用流程很简单:
🔹 第一步:添加 PDF
点击「添加PDF」,选择需要签名的文件,支持多选。
🔹 第二步:选择签名
选一张签名照片,工具自动抠图、转向、优化清晰度,右侧可预览效果。
🔹 第三步:设置日期
默认自动提取每页的"发货时间",也可手动统一输入。
🔹 第四步:开始处理
选择输出目录,点击「开始处理」,一键完成。原文件不会被覆盖。
程序运行依赖 Python 3.10+ 和 PyMuPDF、Pillow、NumPy 三个库。如果你对这些不熟悉,找人帮忙装一下环境即可,三行命令的事。
本文所有案例已做脱敏处理,不涉及任何真实商业数据。
技术从不复杂,复杂的是我们迟迟不动手。共勉。
往期
IT小农工
细想来,真不可思议。明明是一生之中最常见的东西,却从来不曾细细瞧上一眼。
意见交流、商务合作、农工服务请发邮件至:support@lan.wiki
或扫下方右侧小程序提交~

如果喜欢点击在看哟

