 夜雨聆风
夜雨聆风聚焦单细胞、空转与 AI 的交叉前沿。欢迎关注Cellspace AI,持续为您带来最新、最经典的硬核解读

6 月 17 日,OpenAI 联合 Tacit Labs 放出了一个叫 LifeSciBench 的评测基准。它要回答的问题不再是大模型背没背下生物学知识点,而是它能不能接住真实科研里那些没有干净答案、需要反复做判断的活。
它想补的是哪块空白
现有的生命科学评测大多停在两种形态。一种把问题做成结构化的选择题或填空题,配一个标准参考答案,本质上考的是事实检索;另一种集中在计算生物学,让 agent 跑代码、做多步数据分析,这方面已经有像 BixBench 这样被前沿模型接近刷满的基准,但整体范围偏窄,几乎都圈在计算生物学里。前者离真实研究太远,后者又不够宽。研究者每天在做的,是从不完整的证据里读出结论、调和互相矛盾的结果、设计难做的实验、排查 assay 出的毛病、评估转化风险,然后在不确定中决定下一步往哪走。LifeSciBench 想测的就是这一层能力,而且要同时覆盖生物学的多个子领域和药物研发的不同阶段。
750 道题是怎么搭出来的
基准一共 750 道题,全部由 173 位科学家亲手写成。门槛卡得很死:每个人都要有相关领域的博士学位,并且在生物技术或制药行业有至少两年一线经验,覆盖计算、实验、转化和临床各个方向。题目被组织成七类工作流,分别是证据梳理、数据分析、设计与优化、科学推理、验证与运营、转化、科学沟通,再叠加七个生物学领域,从基因组学、药物化学、蛋白与结构生物学,到分子细胞生物学、实验与筛选、生物信息学,以及临床转化科学。
每道题的形态都像科学家丢给一位懂行同事的请求:一段自然语言写的科学问题,加上回答所需的材料,然后让模型自由作答。这些材料不是摆设。整个基准挂了 1062 份附件,涵盖图像、PDF、表格、序列文件、分子结构文件和网页链接,53% 的题目要求模型至少读懂并综合其中一份材料才能作答。79% 的题需要多步推理或决策,平均每题四步。
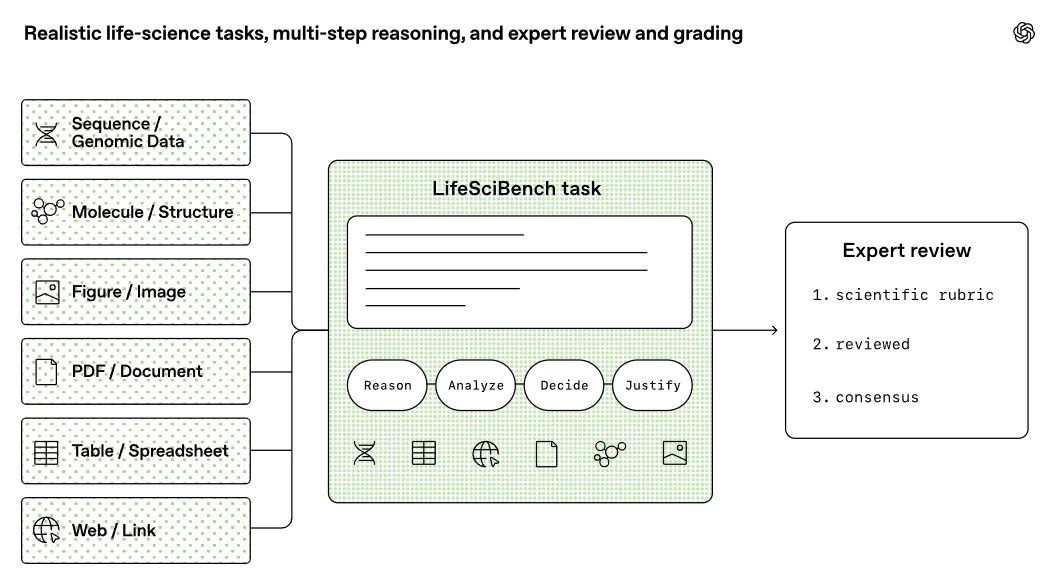
真正决定这个基准分量的是评分方式。每道题配一套专门写的 rubric,把一份理想回答拆成一个个具体的得分点:该提到的事实、该走的推理步骤、该算对的数值、该给出的判断和注意事项。全部 750 道题加起来,这样的评分细则有 19020 条,平均每题 25 条。这套设计背后是一个很务实的判断:很多科研任务没法只看最终答案对不对。一份回答可能结论方向是对的,却因为漏掉一个关键的 assay 局限、或者没主动点出一个后果严重的生物学细节,被判为不完整;反过来,一份没做完的回答,中间推理如果扎实,也能拿到部分分。
几道样题:从 Visium 到甲基化纠错
光看描述不够直观,论文里给的几道样题更能说明它在考什么。
其中一道空间转录组的题是这样的:给一张宫颈癌 FFPE 切片的 Visium 数据,要求模型把 spot 做 k-means 聚成四类,标注每一类的主导细胞类型,再根据肿瘤区与非肿瘤区之间的抗原表达差异,推荐一到两个最有希望的靶向疗法,范围限定在 ADC、TCE 或 CAR-T,并报告每个候选靶点在肿瘤和非肿瘤区的表达占比、odds ratio 和特异性。它的 rubric 细到什么程度:要认出其中两类是肿瘤 spot、一类是癌相关成纤维细胞、一类是基质,还要识别出这张片子里没有免疫细胞类群;靶点层面要点出 F3、TROP2、HER2、NECTIN4、HER3,其中 F3 在肿瘤 spot 的表达占比要落在 90% 到 100% 区间、odds ratio 在 11 到 13 之间;最后还要能推到 NECTIN4 对应 Enfortumab vedotin、HER3 对应 Patritumab deruxtecan,并且主动说明既然没有明显免疫类群,免疫检查点抑制剂的效果可能有限。这已经不是判断模型会不会跑聚类,而是看它能不能把一整条从数据到临床决策的链路走完。
另一道甲基化的题更能戳到做表观的人。背景是一项 NASH 肝活检研究,80 例患者、40 例对照,用 Illumina EPIC v2 芯片,作者直接把 GrimAge v2 套在 EPIC v2 的 beta 矩阵上,看到 NASH 组估计的 GrimAge 均值更高,就下结论说肝脏加速衰老。题目要模型去挑这套分析的毛病,而 rubric 里埋的恰恰是几个真实会犯的错:用原始 GrimAge 均值差当表观年龄加速本身就不对,加速量应该是 GrimAge v2 对实际年龄做回归后的残差;GrimAge v2 是在血液里开发和验证的,直接搬到肝组织缺乏依据;EPIC v2 那些带后缀的探针 ID 得先归一到标准 cg 编号;质控不该用 minfi 的 detection p 值,而该换成 sesame 的 pOOBAH;ComBat 要保护 NASH 状态这个协变量,并且应该作用在 M 值而不是 beta 值上;合并重复探针之前还得先查 Infinium_Design_Type,把 Type I 和 Type II 探针区分开。能把这些点都答出来的模型,基本相当于一个能审稿的资深表观分析师。
官方页面上还举了一个更偏临床的例子:一个治疗杜氏肌营养不良的 AAV9 微 dystrophin 基因疗法,要开 FDA 的 Type B 会议,让模型逐条质疑现有数据包能不能支撑以微 dystrophin 表达作为加速审批的替代终点。模型给出的回答把 Western blot 的抗体表位、定量标准、用自然史队列做对照的统计学问题、AAV 持久性、安全性一项项拆开批,最后给出否定结论。这类题想看的,是模型敢不敢、会不会当一个挑刺型审稿人。
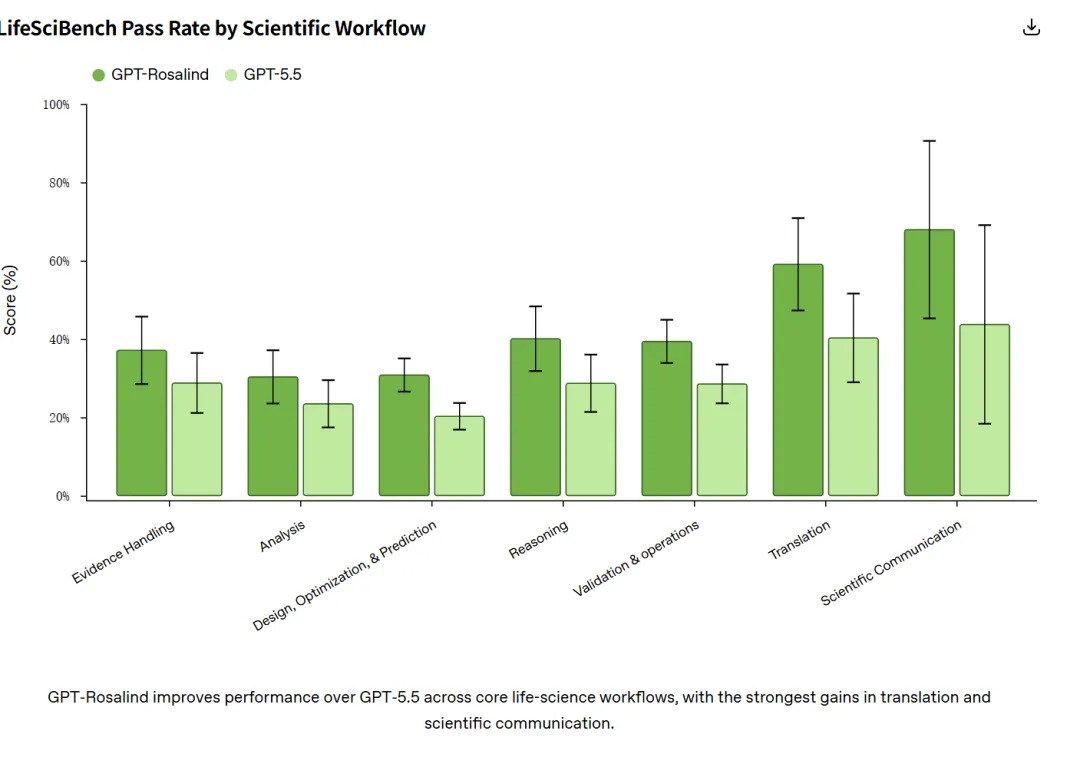
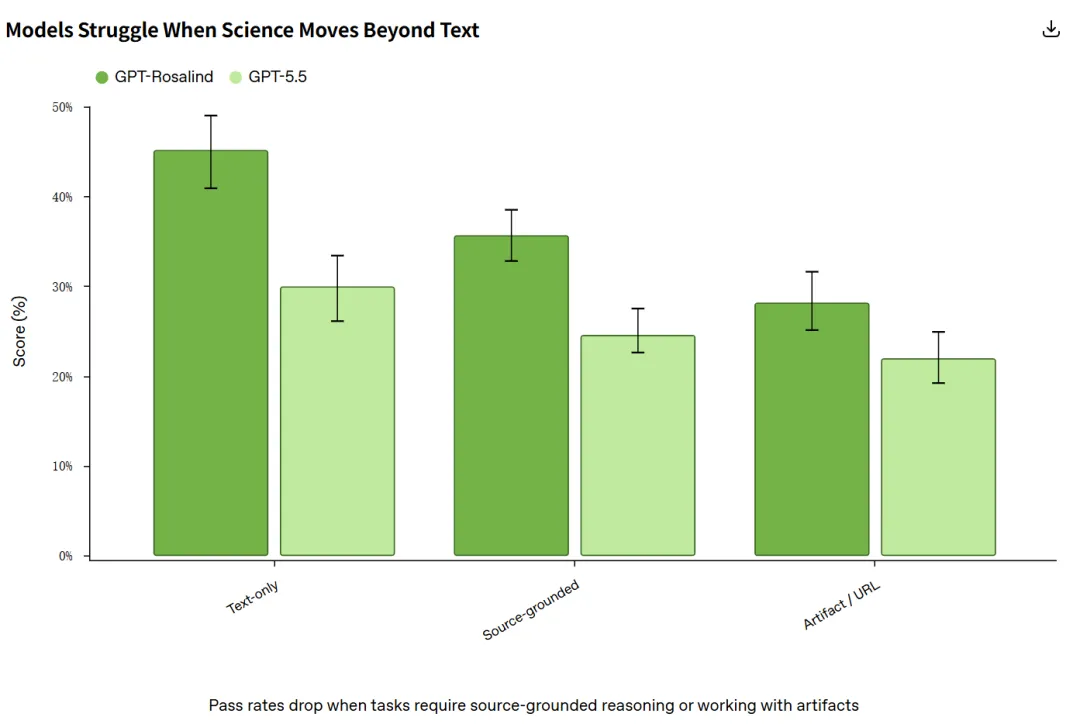
成绩单:最强的也只过了三成
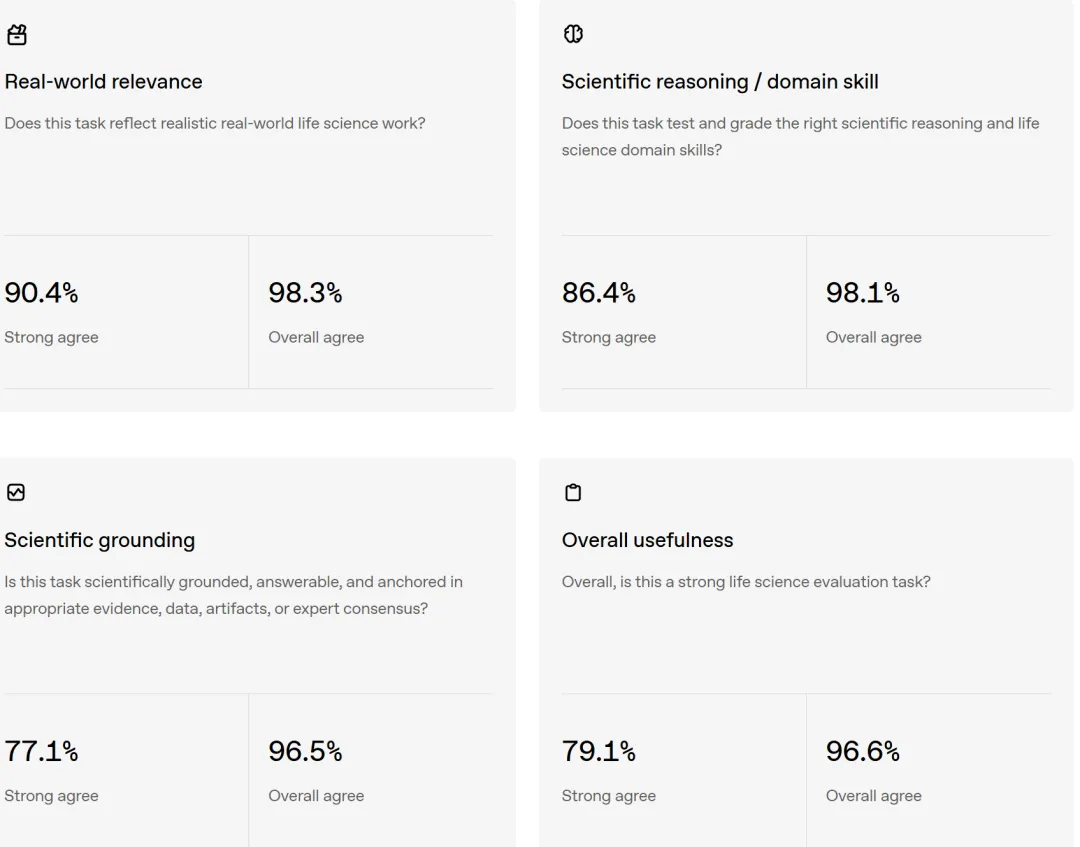
五个模型上场:GPT-5.4、GPT-5.5、GPT-Rosalind、Gemini 3.1 Pro、Grok 4.3。全部单轮作答,只给一次题目和材料,不许追问,但允许自由联网检索。
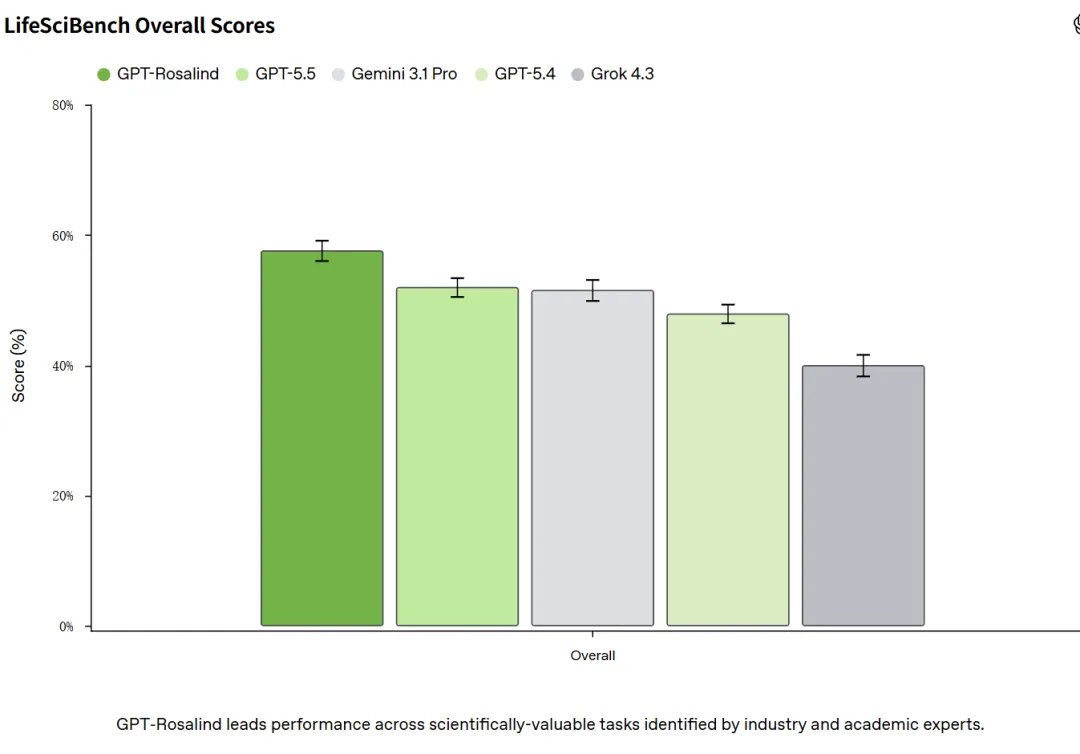
成绩说明问题。表现最好的 GPT-Rosalind,各题等权的归一化平均得分 0.576,任务通过率 36.1%。这里的通过率有明确定义:一道题的回答拿到该题 rubric 满分的 70% 以上才算通过。也就是说,即便是最强的模型,750 道题里也只在三分之一多一点上真正达标。其余几个依次是 GPT-5.5 的 0.519 和 25.7%、Gemini 3.1 Pro 的 0.515 和 23.6%、GPT-5.4 的 0.479 和 20.7%,Grok 4.3 垫底,0.399 和 13.0%。
更能看出天花板的是另一组数:把每道题上所有模型的最好成绩拿出来看,仍有 171 道题(22.8%)没有任何一个模型能通过,261 道题(34.8%)连最强模型的通过率都不到 20%。这个基准离被刷满还很远。
强在哪,弱在哪
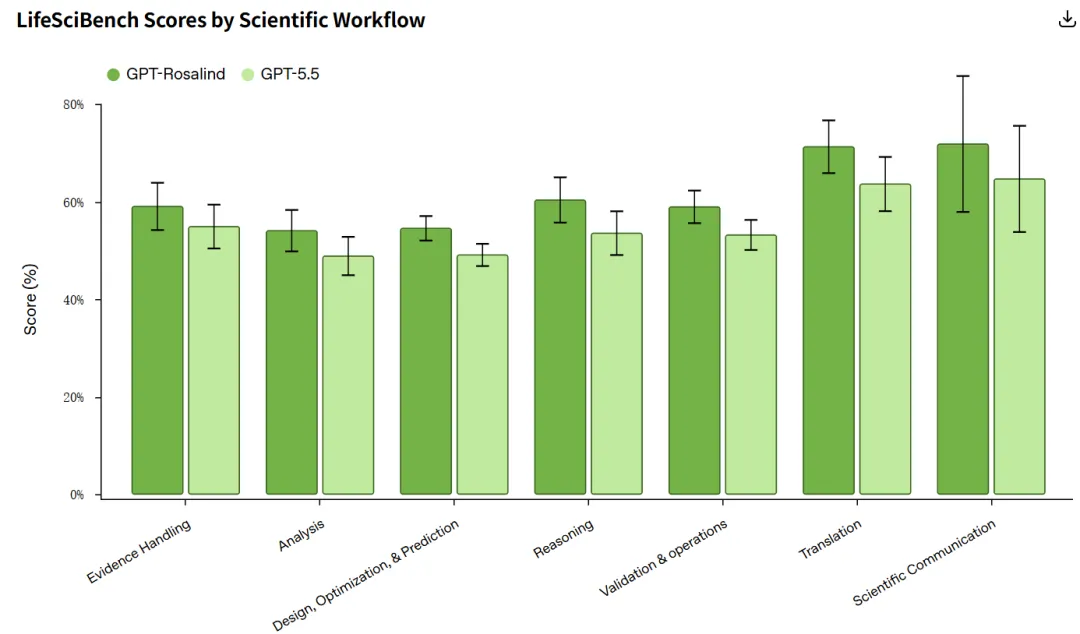
模型现在的强弱分得很清楚。相对强项集中在科学沟通和转化这两类。GPT-Rosalind 在转化任务上的平均分到了 0.712,科学沟通到 0.718,后者题量小,得谨慎看,但方向和别的结果一致。相比 GPT-5.5,它进步最大的几类是解释机制、设计实验、批判与验证。这些都是需要模型从证据里推、权衡取舍、给出能用于决策的答案的活,而不是单纯背书。在需要给出专家可直接采用、带不确定性和注意事项的回答时,它的得分也明显高于上一代。
弱项同样集中。设计优化预测和数据分析是两块最难啃的,GPT-Rosalind 的通过率分别只有 30.7% 和 30.3%,而那些连最强模型都过不了 20% 的难题,有六成集中在这两类里。
另一个清楚的短板是用材料。同样是 GPT-Rosalind,纯文本题的通过率是 45.1%,一旦题目挂了附件或网页链接,就掉到 28.1%;GPT-5.5 也是一样的走势,从 29.9% 掉到 21.9%。问题主要出在从大文件或复杂图里抠信息、再把这些信息接进最终判断这一步。
需要给出精确输出的题更难。涉及序列、结构、构建体这种要逐字逐位对的任务,是所有模型得分最低的一档,GPT-Rosalind 在序列结构类得分点上的命中率只有 46.9%,Grok 低到 18%。而 GPT-Rosalind 相比上一代,在生成构建体这类任务上几乎没涨,只多了 0.001。这件事对做实验设计的人不是小事,CRISPR 的 HDR 供体、siRNA 设计这类输出,差一个碱基就不能直接拿去用。
还有一个现象值得留意:模型经常走到一半。GPT-Rosalind 有 109 道题通过率不到 20%,却拿到了至少一半的 rubric 分。它能找对证据、给出看着合理的部分答案,但最后栽在漏掉某个约束、用错证据、算到一半、或者没把推理收口成一个能落地的结论上。
OpenAI 自己划下的边界
OpenAI 把话也说在了前面。LifeSciBench 测的是自包含的单轮任务,不等于模型在真实研究环境里的表现。真实科研是迭代的,不断拿到新数据、修正假设、设计后续实验,单轮、给定材料的设定还原不了这些动态。所以在这个基准上拿高分,应该理解成具备了真实任务层面的能力,而不是直接等于能加速发现。论文里也明确写了机构背景这一条:基准由 OpenAI 开发,被测模型里也包含 OpenAI 自己的三个模型,结果要带着这个前提来看。被测的五个模型来自 OpenAI、Google 和 xAI,没有纳入 Anthropic 的 Claude。
撇开谁家模型领先,LifeSciBench 这套方法本身更值得做生信和实验的人留意。它把评测从对答案,挪到了对一整套推理和判断是否站得住,而这恰恰是科研工作真正被评判的方式。从样题能看出,它考的不是大模型知不知道什么,而是它拿到一张 Visium 数据、一组 EPIC v2 探针、一份基因疗法数据包时,会不会像一个有经验的同行那样把活做完、做对、并主动说清边界。从目前的成绩看,最强的模型在这件事上也才走了三分之一,剩下的三分之二,正是我们这行短期内还得自己扛的部分。
