 夜雨聆风
夜雨聆风把一段 10 秒的录音丢进去,等十几秒,它就能用你的声音念出任意一段中文。全程不上传,模型跑在你自己的机器上。
这是 voicebox,GitHub 上 jamiepine 的开源项目。30K Star,MIT 协议,5 个月时间从 0 到 30K,定位很直接——本地优先的 AI 语音工作室,免费替代 ElevenLabs + WisprFlow 两家。

一个 app 把语音 I/O 全包了
聊这个工具之前,先把行业格局摆出来。
过去几年,「AI 语音」这块分成了两家公司:
• ElevenLabs 把「输出」做透了——克隆你的声音、生成任意文本的语音、23 种语言切换——但只管「说出去」。 • WisprFlow 把「输入」做透了——全局热键 + Whisper STT,按下说话松手贴到任何输入框——但只管「听进来」。
voicebox 的野心是:两个都做,并且都在你电脑上跑。
打开应用,界面分三大块:Clone(克隆声音)/ Dictate(听写)/ Create(生成语音)。三个场景共用一套声音档案,一次克隆,到处用。
技术栈值得展开说:
• 桌面端用 Tauri(Rust)写,不是 Electron——这意味着体积小、内存占用低、启动快。Electron 应用动辄 200MB+,Tauri 通常在 20MB 以内。 • 后端 FastAPI,本地跑,默认只监听 127.0.0.1。 • STT 用 Whisper(OpenAI 的开源语音识别),TTS 用 7 个引擎可切换。 • 本地 LLM 也内置了,基于 Qwen3,用来做声音档案的「人设」——比如让 AI 帮你改写一段话,让它听起来更「你」一点。
7 个 TTS 引擎怎么选
这是 voicebox 最硬核的部分——不是只能用 1 个模型,而是给你 7 个引擎,按需切换。
| 23 种 | ||
[laugh][sigh][gasp] 这些副语言标签 | ||
| 50 个预设声音,82M 小模型,CPU 推理飞快 |
怎么选? 这是我的判断:
• 个人开发者,CPU 为主,英文场景 → LuxTTS 或 Kokoro,跑得动 • 中文场景,需要自然度 → Qwen3-TTS,国产开源最稳的 • 多语种(超过 10 种)播客 / 视频配音 → Chatterbox Multilingual,唯一覆盖 23 种 • 要笑声、叹气、咳嗽这类表达 → Chatterbox Turbo,唯一支持 [laugh][gasp]标签的
一个细节:Qwen3-TTS / LuxTTS / Chatterbox Multilingual / TADA 看到 [laugh] 这样的标签会当成字面文本念出来,只有 Chatterbox Turbo 真的能识别。挑引擎前先想清楚你要什么。
给 AI agent 装个「嘴」是最大亮点
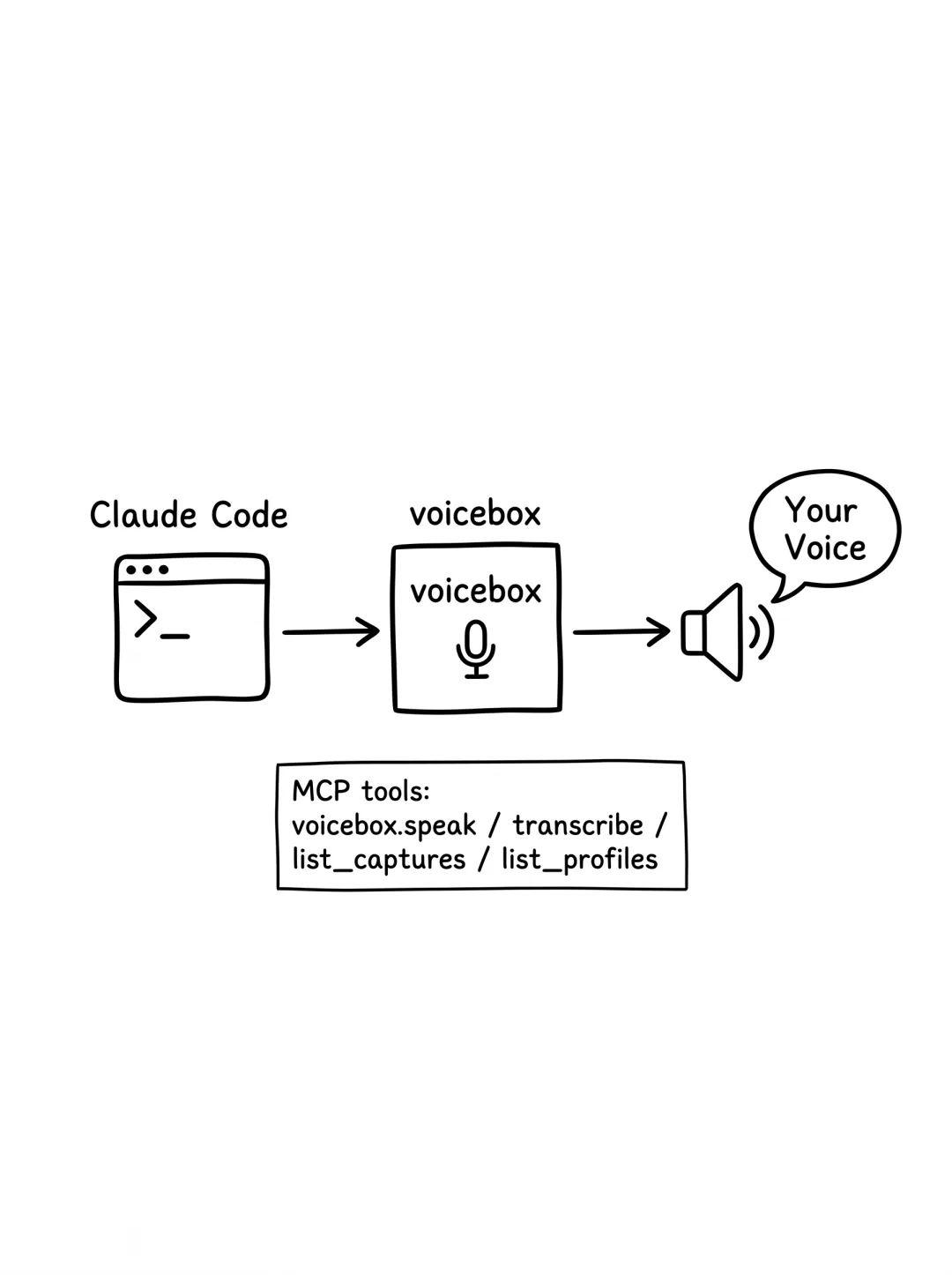
最后说 voicebox 最反常识的功能——它内置了一个 MCP server。
什么意思?你的 Claude Code / Cursor / Cline 这种 MCP-aware 的 AI agent,装上 voicebox 之后,能用声音跟你说话了。
打开 Claude Code,你说:
「帮我做个 CSV 分析脚本」
它不只输出文本,还会调用 voicebox.speak 这个工具,把你克隆好的声音(比如你的声音)念出来:
「好的,我来帮你写一个 CSV 分析脚本,先看看数据格式。」
这是其他 AI 语音工具都没做到的事——MCP 协议原生支持 + 内置 4 个工具(voicebox.speak / transcribe / list_captures / list_profiles),AI agent 直接能调,不用写胶水代码。
场景我想到 3 个:
• 开发者:长时间跑 Claude Code,不用一直盯屏幕,让 AI 用语音汇报进度 • 视障用户:屏幕阅读器 + 语音 agent,完整的双向语音工作流 • 播客 / 视频创作者:一个人就能产出多角色对话音频(用 Stories Editor 的多轨时间线)
我的判断
30K Star 不算大,但 jamiepine 这个人之前做的 Spacedrive 也是这个量级——单点突破、一个人扛全栈、用 Tauri 不用 Electron 的实用主义路线。voicebox 跟这条路一脉相承。
对 ElevenLabs 和 WisprFlow 的威胁:技术追平 + 隐私优势(全本地) + 免费——这三点同时具备,确实会让一部分人迁移。但 ElevenLabs 在「克隆质量」「企业级 API」上还有先发优势,voicebox 想吃下整个市场还有得打。
值得装吗? 取决于你的场景:
• 偶尔用 / 不想折腾 / 英文为主 → ElevenLabs 还更省心 • 中文为主 + 想要隐私 + 想跑 agent 语音交互 → voicebox 是目前开源里最完整的方案 • Linux 用户 → 暂时没有预编译二进制,需要从源码编译,门槛不低
装它之前先确认 2 件事:
1. 你的 GPU 显存至少 4GB(Qwen3-TTS 1.7B + Whisper 跑得动) 2. 你的场景是「真需要本地」还是「云端也行」——如果后者,ElevenLabs 起步体验更顺滑
真正的杀手锏是 MCP——其他语音工具都没把「让 AI agent 说话」做成原生能力。voicebox 这步棋走对了,后面如果 agent 生态起来,这个会变成它最大的护城河。
GitHub工具 地址: https://github.com/jamiepine/voicebox
