 夜雨聆风
夜雨聆风从 Ada Lovelace 到 ChatGPT:计算机究竟如何"学会"做事?
传统编程是程序员写规则,计算机来执行;机器学习是给计算机看答案,让它自己找规则。这一来一回的颠倒,就是整个 AI 时代的底层逻辑。
一、从 Ada Lovelace 说起
1843 年,Ada Lovelace(埃达·洛夫莱斯伯爵夫人)为查尔斯·巴贝奇的分析机写下了历史上第一段计算机程序——一段计算伯努利数的指令序列。她的方法很简单:写下一行行明确的规则,机器逐条执行,得到正确答案。这便是传统软件设计最核心的信仰:计算机是人脑的延伸,执行的是人已经理解并形式化了的步骤。
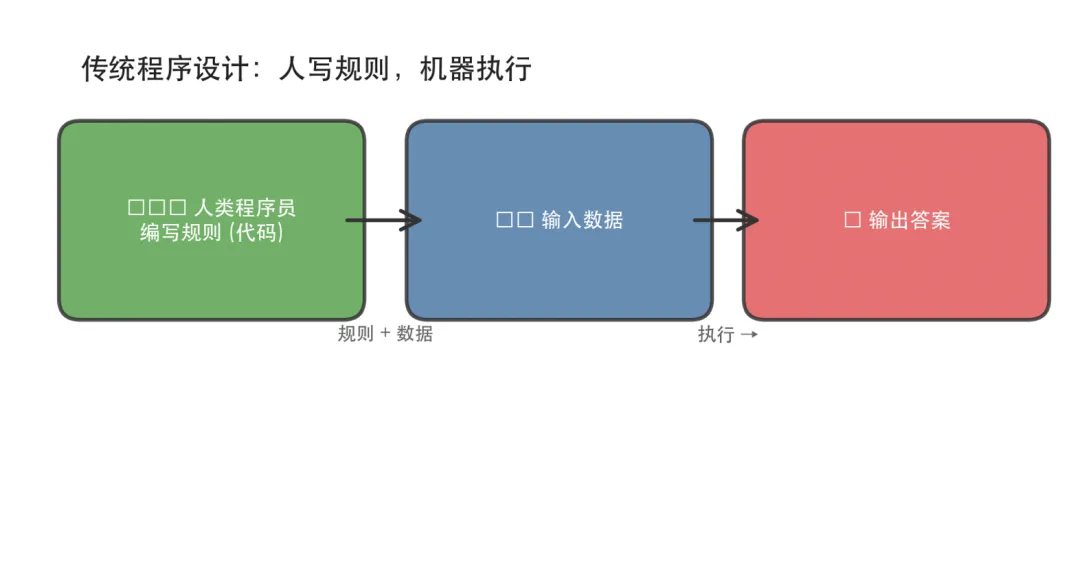
我们用 Python、Java、C++ 这些语言写的每一行代码,本质上都是在做同一件事——把人的逻辑翻译成机器能执行的指令序列。if-else 分支、for 循环、函数调用——这些都是规则的显式表达。
二、机器学习:把过程反过来
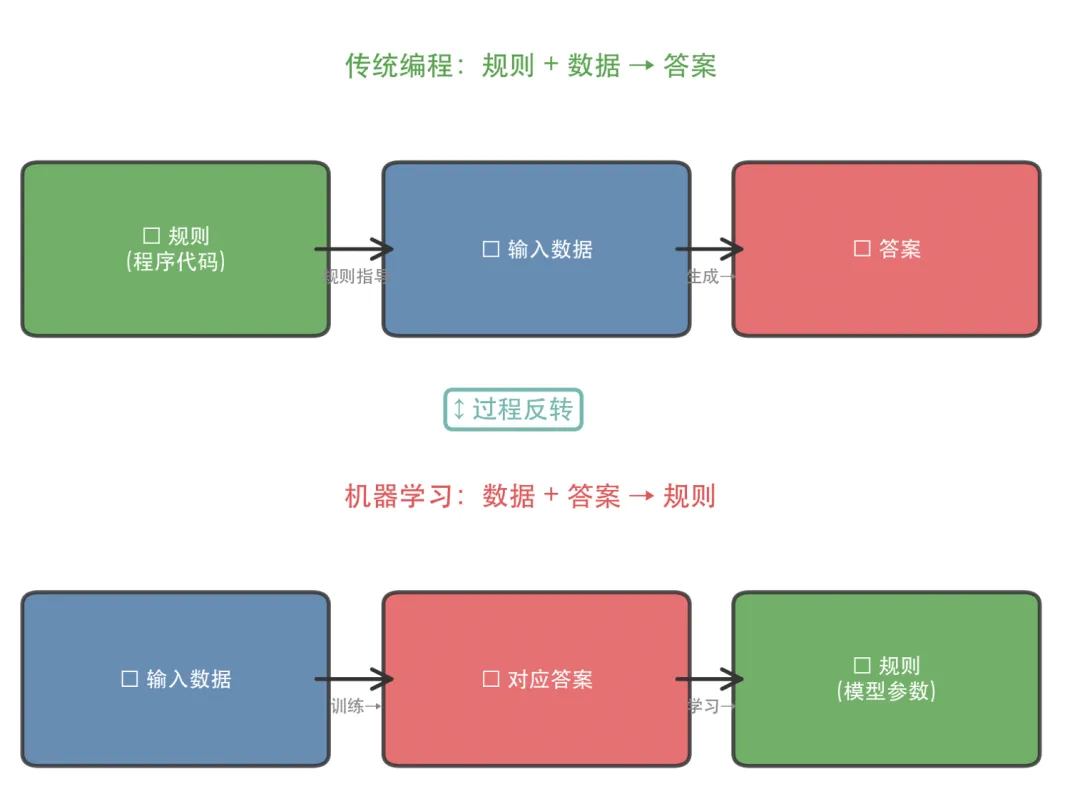
机器学习颠覆了这个延续了 170 年的范式。
传统编程:规则(程序)+ 输入数据 → 答案
机器学习:输入数据 + 答案 → 规则(模型)
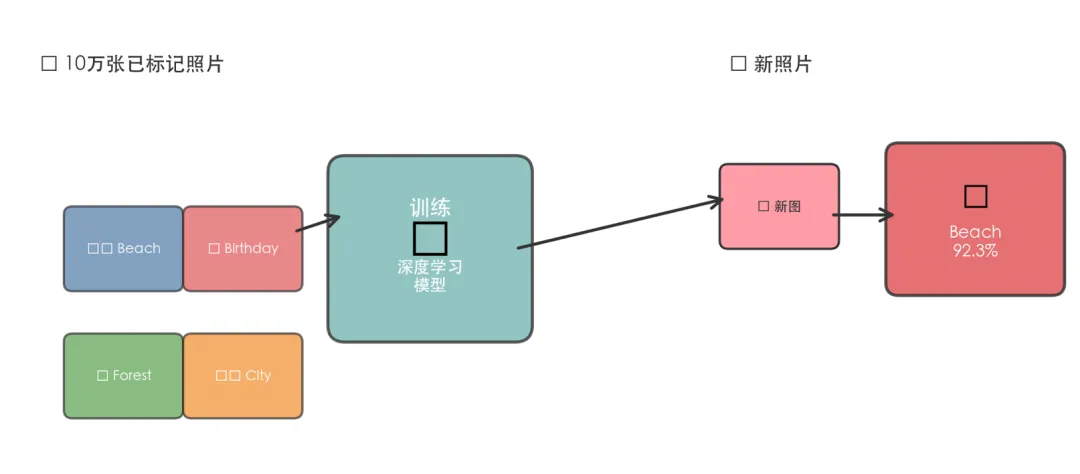
照片标签的两种实现方式
传统方式需要你写出每一种可能的场景的判断规则:沙滩需要检测蓝色和沙粒,生日需要检测人脸和蛋糕……规则数量随着场景增加呈指数级膨胀,很快就变得不可维护。
机器学习方式只需收集10万张人工标记好的照片,训练一个深度神经网络。它会自己学会"蓝色+沙粒=海滩"、"人脸+蛋糕=生日"的统计模式,甚至学会你从未显式定义过的标签概念。
三、范式差异的核心维度
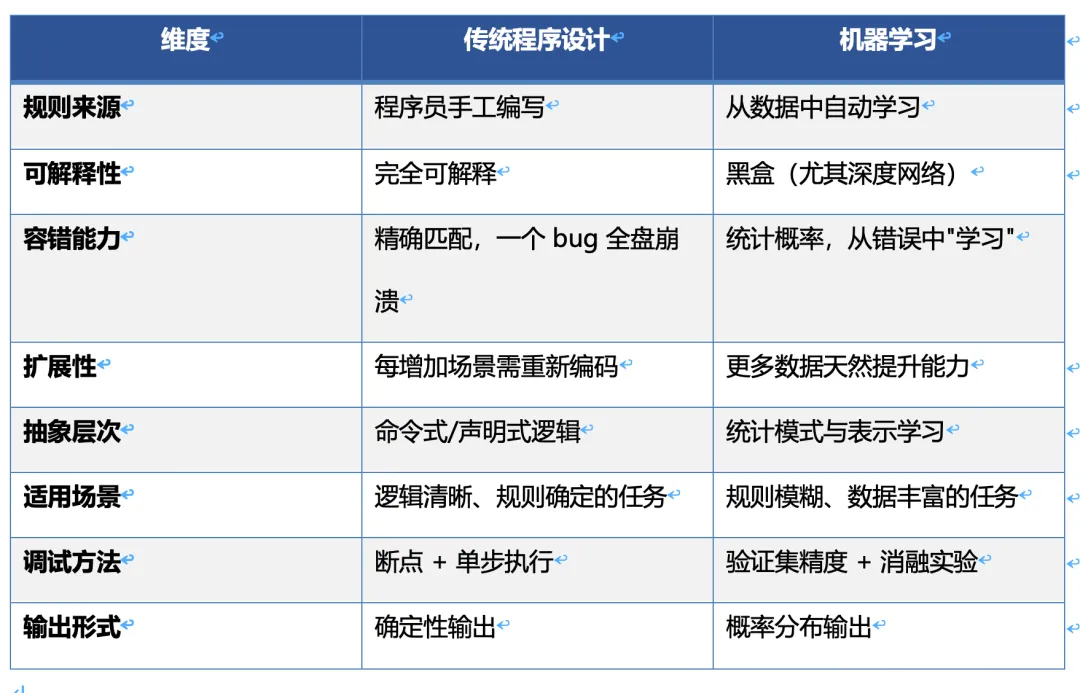
3.1 规则来源之辩
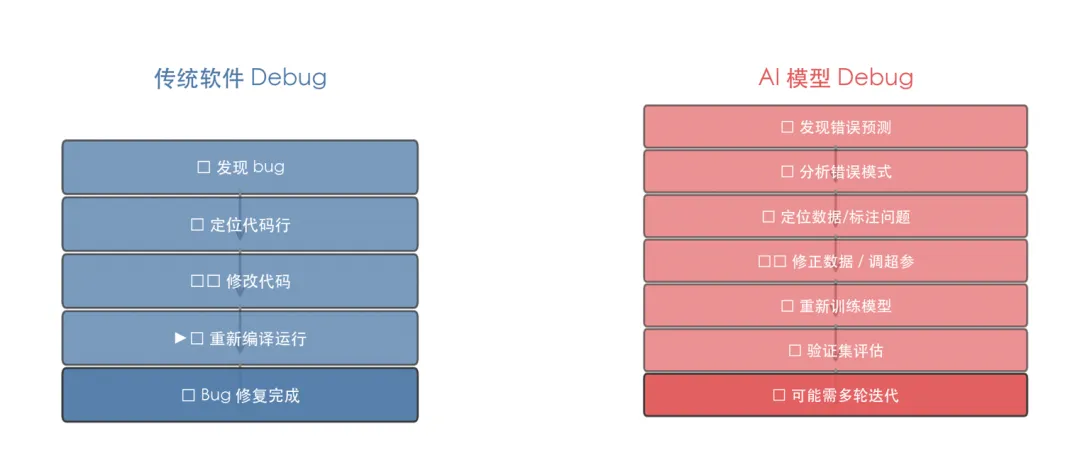
传统程序员的每一个 if 都是深思熟虑的结果——你要理解问题域,把判断逻辑显式写出来。ML 模型的行为则由数十亿个参数(权重)共同决定,没有一个"人"能说清楚某个参数的具体含义。这就引出了"可解释性赤字":传统软件出 bug,改代码就行;AI 模型表现不好,是数据问题、架构问题还是超参问题?
3.2 从确定性到统计性
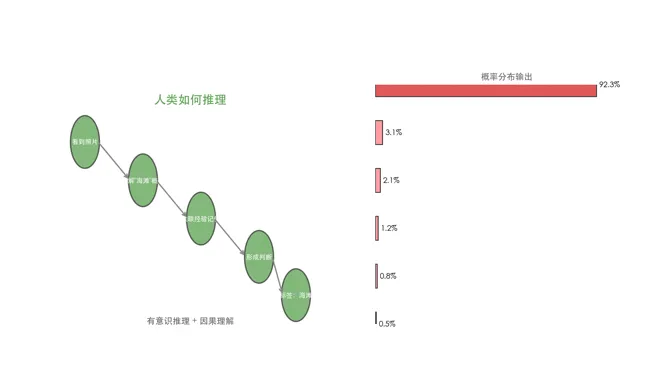
传统程序是确定性的:同样的输入必然得到同样的输出。这是冯·诺依曼体系结构的基石。机器学习模型是统计性的:它输出的是一个概率分布。"这张照片中有猫的概率是 92.3%",而不是"这张照片里有猫,是/否"。这个差异极其重要——它意味着 AI 系统天然带有不确定性。
四、认知盲区:人们为什么误解 AI
盲区一:把 AI 当成"超级 if-else"
很多人以为大语言模型就是更复杂的规则引擎——只是规则数量多了几个数量级而已。错。GPT-4 有约 1.8 万亿参数,没有一个参数对应一个具体的 if 条件。它的行为来自高维空间中统计模式的涌现,而不是显式的规则匹配。
盲区二:过度相信 AI 的"推理能力"
当 AI 像人一样组织语言、给出推理步骤时,人们天然会认为它像人一样在思考。但 AI 的"推理"本质上是:在训练数据的统计分布中寻找最可能的 token 序列。它没有意图、没有意识、没有因果理解——只是概率模式匹配到了看起来像推理的文本模式。
盲区三:低估数据的重要性
传统软件工程师常说"改个 bug 五分钟",但在 AI 系统里,修正一个错误可能意味着:找到错误模式对应的训练样本 → 修正数据标注 → 重新训练整个模型 → 验证修正没有引入新问题 → 部署新模型。修正周期从分钟级变成了天级。这就是为什么数据质量是 AI 系统的命门。
五、理解差异的实践意义
理解了传统程序设计和 AI 的本质差异后,对技术决策者有几点实际建议:
• 选型判断:任务规则明确且不变 → 传统软件;任务复杂且规则模糊 → AI
• 预期管理:AI 不会 100% 正确,需要设计容错机制
• 数据战略:AI 能力的上限取决于数据的质量和规模
• 可解释性需求:金融、医疗等监管敏感领域,慎用纯黑盒 AI
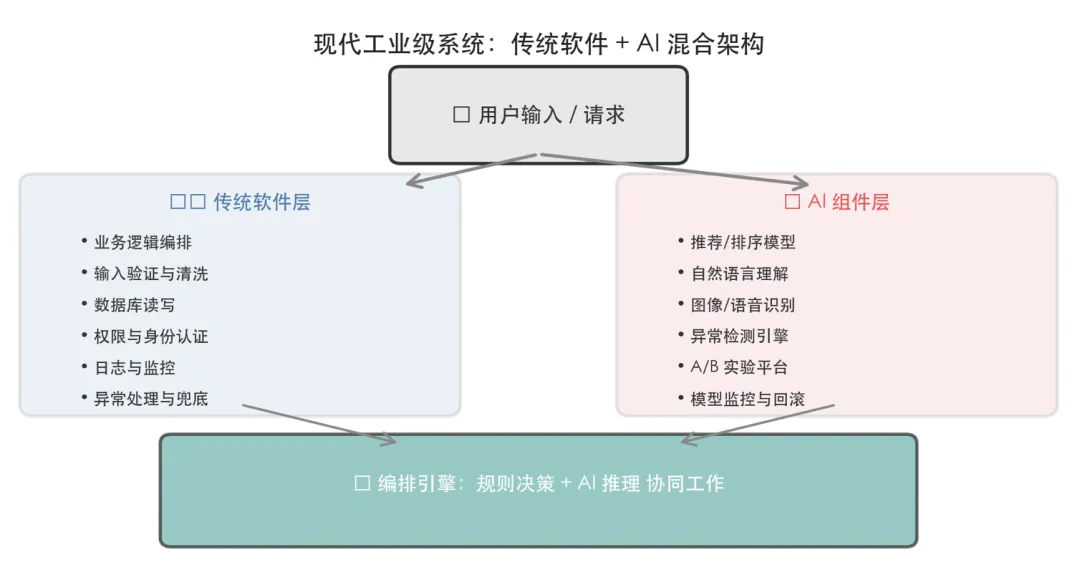
• 混合系统:大多数工业级系统 = 传统软件 + AI 组件的混合架构
结语
回到 Ada Lovelace 的时代,她写下第一行程序时,计算机的角色被定义为"按照人类写好的规则执行"。这个定义统治了计算机科学 170 年。
机器学习没有推翻它,而是把它升维了:机器不再只是规则执行者,它成了规则发现者。
但请记住——发现规则不等于理解意义。识别出"蓝色+沙子=海滩"的统计相关性,和真正理解什么是海滩、什么是度假,是两种不同的认知活动。
这正是 AI 能力的边界,也是人类不可替代的价值所在。
