 夜雨聆风
夜雨聆风
做临床研究的人多半有过这种经历。手里有一批数据,脑子里有个想法,可光是把分析代码写出来、调通、再反复优化,就能耗掉好几个月。真正用来想科学问题的时间被写代码挤没了。2026 年 5 月,谷歌 DeepMind 和谷歌研究院的团队在《Nature》上发表了一项工作。他们做了一套系统,能根据你定好的评分标准,自己写代码、自己跑、自己改,一步步把分数往上提。值得一看的地方在于:在单细胞数据整合、新冠住院人数预测这些医学研究里很常见的计算任务上,它自己琢磨出来的算法,在多个公开评测里跑赢了顶尖人类专家手工搭的方案。
01 /推文概览
研究把大模型和一种叫树搜索的策略接在一起,AI 就能自己生成、评估、反复改写复杂的科研分析代码。过去要花几个月才能搭好的定制工具,被压缩到几天,甚至几小时。
医学和公共卫生研究里,很多分析工具有个共同点:它的好坏可以用一个明确的分数来衡量。生物现象和疫情变化太复杂,没办法靠一条干净的数学公式直接算出来。研究者只能用代码把模型搭起来,再拿大量真实数据反复试、反复调参数,看哪一版分数更高。这套系统针对的就是这类活儿。
测试的数据跨度很大。基因组学这边,处理的是一百七十多万个单细胞的转录组数据,维度高,又非常稀疏。流行病学这边,分析的是全美五十二个州和地区好几年的住院时间序列,上报有滞后,噪音也多。除此之外,还做了斑马鱼全脑七万多个神经元的活动预测、卫星影像的地理分割,以及通用的时间序列预测。
它和大家平时印象里的 AI 写代码不太一样。平时多半是你给一句话,它给你一段代码,一次性交付。这套系统不止于此。它能读懂医学评测的打分规则,把生成的代码丢进一个隔离的运行环境里自动跑,提取出像批次校正效果、区间预测准不准这样的客观分数,再照着分数自己改代码。它会不断长出新的代码版本,像一棵树一样越分越多,最后在大量候选里挑出表现最好的那一版。
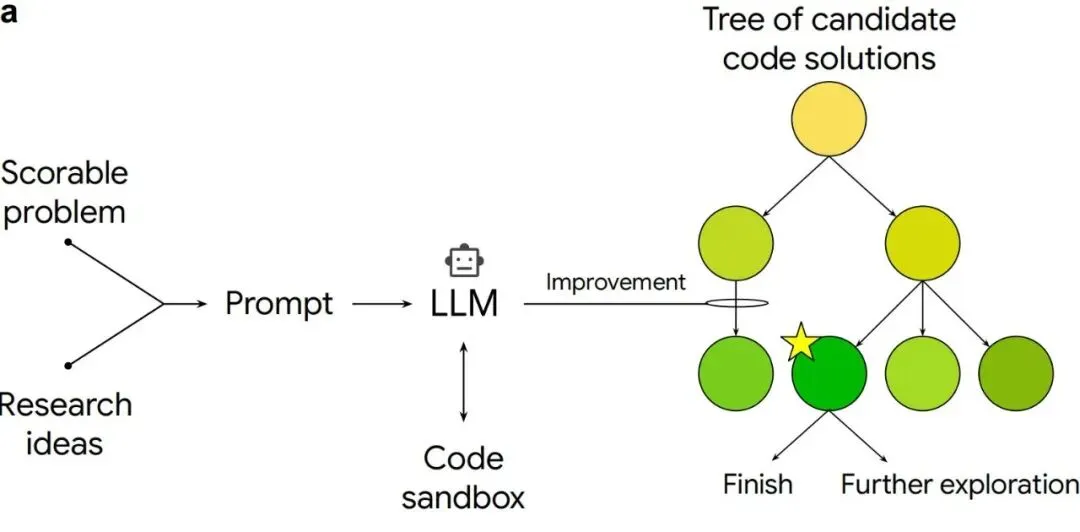
图 1a
图注:系统的总体工作流。把一个可打分的任务和相关研究思路一起喂给大模型,生成初始代码后丢进计算沙盒里跑分,再用树搜索不断扩大候选方案树,最终输出高分的科研代码。
02 /两个底层设计
它能在这么多专业领域都拿到好成绩,主要靠两个底层设计。
第一个:用树搜索来探索代码的各种可能
普通大模型写复杂算法,常见打法要么写一版就交,要么一口气生成上千版再挑最好的。问题是,这种打法很容易在某个瓶颈上卡住。一段核心逻辑只要差了一点,后面整个程序的输出就全废了。研究团队借用了下棋 AI 里常用的树搜索:系统每写出一版代码,先在隔离环境里跑一遍、打个分,再决定下一步从哪个版本接着改。所有历史版本都留着,这条路走死了,就退回去从另一个分支重来。
挑下一步改哪一版,系统不靠瞎猜。它会给每个版本算一个分,既看这个版本现在分高不高,也看它被试过几次、还有没有挖掘空间。那些被试得少、又可能有潜力的版本,会被优先探索。
这套思路,临床上其实很熟悉。面对一个还没摸清的耐药菌感染,医生不会认准一个方案一条道走到黑。每天看炎症指标、体温、脏器灌注的变化,在几套备选里动态调整。这一组联合用药把肝肾指标拖坏了,就赶紧退回来,换一条副作用更小、又有希望的路。这套系统也是这么干,把代码在运行环境里的得分当成"体征"盯着,不停地试,不停地回退,不停地长出新分支。
这么设计的直接好处是,系统不再被单次生成的上限卡住。研究团队先拿了 16 项机器学习竞赛任务来打磨这套系统。综合测试里,树搜索写出来的代码,明显好过单纯多调用几次大模型的做法。搜索过程中,系统还能抓住那些让分数突然跳一大截的关键改动,一小步一小步攒下来,最后搭出比一开始设想的强得多的算法。
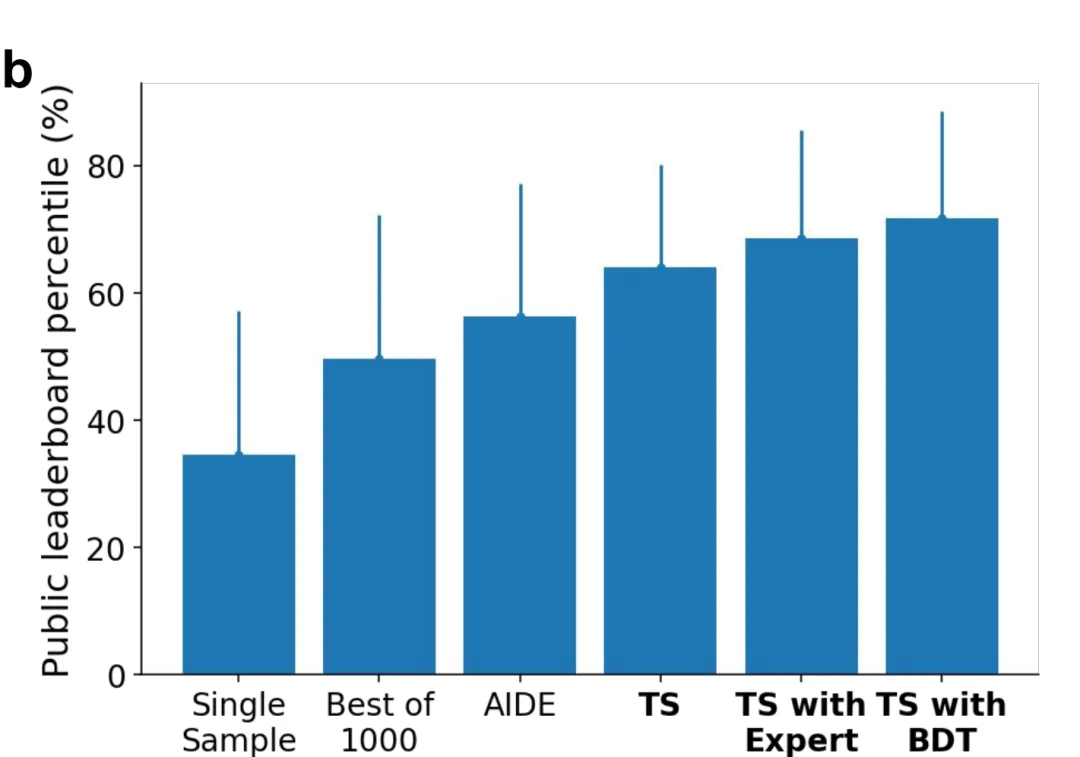
图 1b
图注:在 16 项竞赛任务上,几种代码生成方式的公开榜单百分位对比。从左到右依次是单次生成、从一千次里挑最优、AIDE,以及树搜索的几个版本。树搜索明显高出一截。
第二个:把文献思路喂进去,再做交叉重组
光让系统自己瞎调代码语法,效率还是不够高。真实的科研创新,很多时候是研究者读了不同领域的文献,把里头的核心机理拎出来、互相嫁接。系统模仿的就是这个动作。它先用大模型把顶级期刊里各种基准算法的原理读一遍、总结好,再把这些思路翻译成具体的写代码指令。
换个临床场景就好懂了。大医院的多学科会诊上,心内科的抗凝策略和神经外科的防出血原则,机制上常常打架。但有经验的会诊团队能把两边的核心原则各取一块,给合并症复杂的病人拼出一条全新的个体化方案。这套系统也能这么干。它不光能照着一篇文献把原方法复现出来,还能把两个看着八竿子打不着的算法逻辑,缝到一起。
重组出来的混合算法,表现常常超出预期。在单细胞数据整合任务上,系统把 11 种不同的基线算法两两配对,做了 55 种重组。每次都让大模型先分析两个"母本"各自的长短处,再取精华做杂交。结果是,这 55 种新算法里,有 44% 在客观评分上同时压过了它借鉴的那两个原始算法。更有意思的是,最后跑赢现有榜单的方法来源很杂:有的来自文献复现,有的来自重组,还有一部分思路根本没看文献,是大模型自己生成的。
03 /关键结果
这套系统的本事,在好几个严格的医学和科研计算基准上都验证过。下面挑单细胞和全美流行病预测这两块讲。
单细胞数据的批次效应校正
在单细胞层面看人体组织,是现在发现新细胞类型、推断基因调控网络、找治疗靶点的核心手段。但有个老大难问题:来自不同实验室、不同测序平台的数据要合在一起分析时,平台差异会带进明显的技术性批次效应。校正这事很难拿捏。手太重,真实存在的罕见细胞亚群信号会被一起抹掉。手太轻,又会冒出一堆根本不存在的假聚类。
这个领域有个公认的公开评测平台,标尺定得很严。算法要在六个涵盖人和小鼠的大型独立数据集上跑,输出 13 项指标,综合看它在保住生物学差异和去掉技术噪音之间平衡得怎么样。为了防止系统在测试集上过拟合,研究团队专门另找了两万个细胞的子集让它演化代码、调参数,最后拿到一百七十多万个细胞的盲测集上验真本事。
数据上,系统自己摸索出了 40 种全新的整合方法。它们在核心盲测集上的综合表现,整体超过了这个公开榜单上现有的、人类专家多年打磨出来的顶级算法。其中最亮眼的,是一个经过树搜索优化的 BBKNN 版本。
这个版本拿高分的路子挺有启发。常规做法是直接在主成分空间里找近邻。这个版本多走了一步:先借用另一种经典算法 ComBat 的全局降噪思路,把高维主成分里的全局线性技术差异先抹平,再在这个已经初步去噪的空间里搭出局部的批次平衡近邻网络。两步合在一起,既校准了全局,又平滑了局部。专家逐行审查也确认,这些机器写的脚本确实照着预设逻辑在跑,没出常识性的低级错误。
几个能核实的数字摆在这。这个树搜索版 BBKNN,综合得分比此前最好的已发表方法高出约 14%。在 13 项指标里,它有 11 项追平或超过了已发表的 BBKNN。把系统产出的所有方法算总账,87 种里有 40 种超过了榜单上已发表的全部方法。
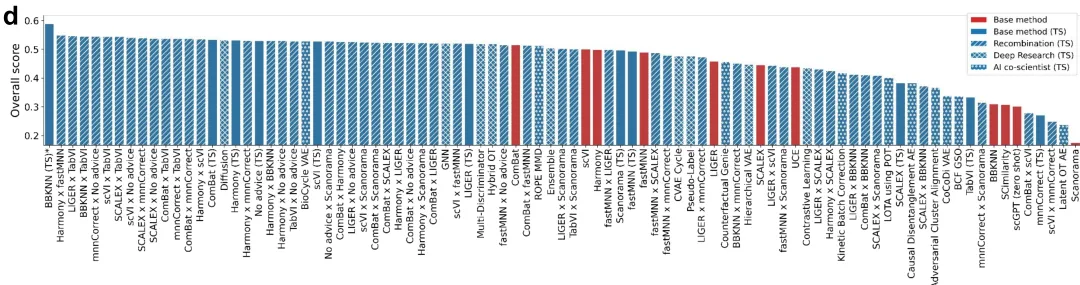
图 2d
图注:单细胞批次整合任务上,各种方法的综合得分排序。系统产出的方法占据了榜单前列,其中既有基线复现、也有重组和大模型生成的思路。
全美新冠住院人数预测
公共卫生决策和医疗资源调配,很依赖对疫情趋势的提前预判。美国疾控中心牵头建了一个权威预测平台,要求各团队用带滞后、带噪音的实时上报数据,每周提交全美五十二个州和地区未来四周的住院人数预测。光给个数还不够,得给出覆盖 23 个分位数的概率范围。官方用一个叫加权区间得分的指标打分,它既罚预测中位数偏得离谱,也罚那种把范围估得过窄、过于自信的预测。分越低,说明又准、对不确定性的把握又好。
长期占据领先的几类模型,有基于历史气候均值的简单基线,有统计学的自回归时序模型,也有梯度提升这类机器学习模型。疾控中心把所有顶尖团队的结果整合成一个官方集成模型,这个集成一直被当成美国流行病预测里很难撼动的标杆。
在这么个高手云集、噪音又多的环境里,研究团队做了一个严谨的回溯实验。系统拿 2024 到 2025 年度的真实历史数据,用六周一滑的验证窗口持续演化代码。结果是,它不仅复现出了多数公开的人类专家基线,还自动造出了 14 种能稳定压过疾控中心官方集成的全新预测架构。
它能突破的关键,在树搜索自己摸出来的一条杂交规律:把历史气候均值模型和现代统计模型深度融合。气候均值给出一个基于常年季节规律的稳底盘,免得模型一遇到局部数据暴涨或者节假日迟报就反应过激。在这个稳底盘上,再叠一个高灵敏的自回归组件,专门盯着突发聚集性感染带来的短期异常。一个管长期大势,一个管短期突变,正好互补。
注:得分越低越好。除最优混合模型外,系统另有 14 种架构稳定优于官方集成。
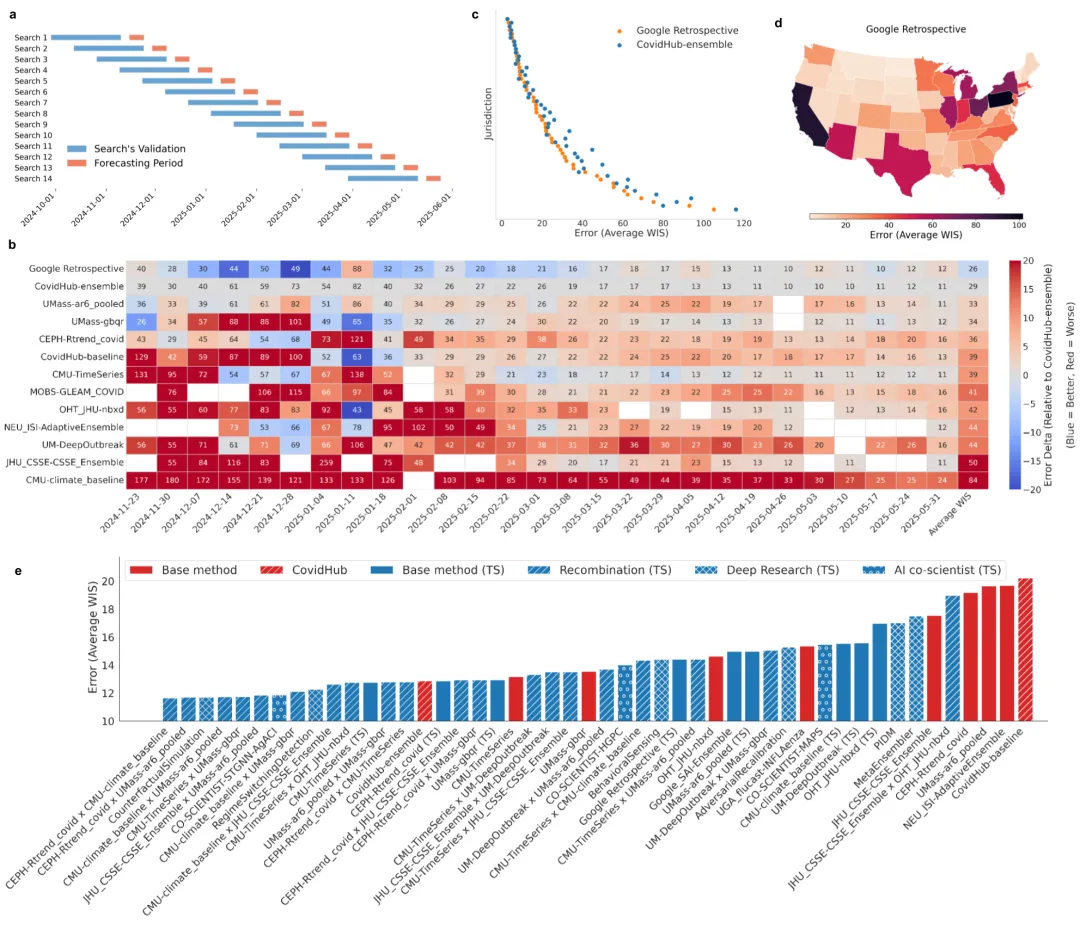
图 3
图注:各团队逐周预测表现的对比热力图。蓝色表示比官方集成更准,红色表示更差。系统的回溯模型大面积偏蓝。
除了这两块重头,系统的泛化能力在另外三个领域也得到了验证。神经科学这边,它写的代码能预测斑马鱼全脑七万多个神经元的活动。地理空间这边,它自动写出了给卫星影像做多标签语义分割的脚本。通用时间序列这边,它干脆从最基础的数学库起步,丢开所有现成的时序软件包,跑了上千轮树搜索,自己攒出一套带八套预设配置的统一预测代码库。这套库能自动剥离数据里的假期效应、趋势和周期噪音,在 97 个完全不同的时间序列数据集上都拿到了顶尖水平。
04 /延伸讨论
它打开的新方向
科研基础设施这一层,传统流程里,搭底层数据清洗管道、调神经网络超参数、写一堆评估脚本,往往得靠有深厚编程功底的生物信息学家耗大量精力。有了这套自动搜索的系统,临床科研人员有机会从这些繁琐的工程实现里抽身出来。
往后临床科研的分工可能会变。临床医生把精力放在提出有临床价值的假设、定义清楚什么样的数据算好、指出哪个方向的文献最值得参考。剩下那些枯燥又庞大的算法推演、特征工程和代码落地,交给系统去跑。门槛因此压低了不少。以前一个跨学科团队要协作几个月才能跑通的验证管道,现在可能几天、甚至几个小时就能拿到一份靠谱的数值反馈。
还有个细节:研究者用了五种不同的大模型来驱动这套系统,说明它不挑模型。同时也能看出来,模型越强,在简单任务上单靠它一次生成就已经很好,树搜索的价值更多落在难任务上。也就是说,大模型基础能力越往上走,这套系统能搭出来的代码上限也会跟着抬高。
局限性
在多个基准上拿了好成绩,不代表它没有短板。这些短板是工程设计和算法原理决定的。
第一个是算力消耗和数据取舍之间的矛盾。做单细胞算法寻优时,每变异一次代码,都得在隔离环境里完整跑一遍训练和推理。为了不让搜索拖太久,系统在工程上做了妥协,只截取两万个细胞的缩小样本来演化和评估代码。这么做搜索是快了,代价是它在打磨代码逻辑时,可能漏掉那些只有在上百万级全量数据、罕见细胞充分暴露时才会触发的细微生物学反馈。
第二个是它不懂因果。这套系统本质上是个死盯着分数往上爬的优化器。它靠算相关性、算残差,找到了让分数变高的数据处理组合,但它并不真的理解疾病怎么发生、细胞通路谁因谁果、药物分子之间在物理化学上如何相互作用。
这就埋了个隐患。如果你定的评分指标本身有缺陷、没能完整反映临床现实,系统很可能造出一个数值上完美贴合、生物学上却站不住脚的假模型。这种纯靠经验试错堆出来的代码,替代不了科学家基于理论推导去做的机制探索。
原文出处:Aygün, E., Belyaeva, A., Comanici, G. et al. An AI system to help scientists write expert-level empirical software. Nature (2026).
— END —
我们手上有个AI+医疗的行业小群,里面是创业者、临床医生、医药企器械这些真在一线做AI临床落地的人。群里更实在的是线下,我们差不多每两周就会攒一次小局,十来个人围一桌,喝咖啡吃点心,聊各自在做什么、卡在哪。线上没赶上的,线下能补回来。
另外还有个偏科研向的群,想去的可以一起跟我说。
备注你的方向,我看到回你。
