夜雨聆风
夜雨聆风


代码越写越快,审核和维护却越来越慢。
去年12月,美国韦氏词典把Slop选为2025年度热词。词典给的定义很简单,指的是通常由AI批量生成的低质量数字内容。
中文直译是泔水,完整叫法是AI Slop,也有程序员直接叫它AI屎山。这个词在2025年走红,最初是因为互联网上充斥着一眼就能认出来的AI图片、AI文章和AI视频,数量多到让人反胃。
但在程序员的世界里,AI Slop有一个更具体的含义。指的是大量由AI生成的代码进入了软件项目,表面上能运行,实际上充满隐患,最终需要有经验的人一点一点地发现和清理。

最近,这个话题在社交媒体上突然升温。来自海德堡大学、墨尔本大学、新加坡管理大学的研究者联合发了一篇论文,基于1154条开发者真实讨论,分析了AI辅助开发之后到底发生了什么。
研究者最终发现,AI确实让写代码变快了,但随之而来的问题,正在把效率收益一点一点地吃掉。
有经验的人一眼就知道
程序员圈子里流传着一套非正式指南,用来识别哪些代码是AI生成的。
有经验的人往往看一眼就能感觉出来,注释密密麻麻、格式整整齐齐,变量名字像教科书,逻辑链条乍看上去很自洽,但每一行都缺少一种东西,就是真正处理过这个具体问题才会留下的痕迹。
研究者整理出了AI代码的几种固定问题模式。
遇到报错不修改逻辑,直接用一个临时补丁绕开它,让代码暂时不崩溃但问题依然存在。类型不对不去找原因,直接把变量强制转换,把报错消掉。
测试跑不过不找问题出在哪,直接修改测试代码让结果看起来通过。还有更离谱的案例,AI虚构了一个根本不存在的外部服务,然后自己模拟这个服务的接口,生成一套逻辑上完整、实际上完全是假的集成方案。
这些代码在提交的那一刻能运行,问题是它们像定时炸弹。
改动一处可能在完全不相关的地方炸出新问题,几个月后没有人能看懂当初为什么这样写。

技术债,是程序员用来描述这类遗留问题的说法,今天省下来的工夫,未来要花几倍时间来偿还。一位开发者的总结很直接,用AI开发速度确实快,但技术债累积的速度也会变得前所未有地快。
这些来源正在被AI生成内容填满,看起来专业,但示例代码跑不起来,API名字不存在,关键步骤缺失,有时整篇教程的思路就是错的。
一位开发者说,他越来越频繁地遇到文档里缺少关键内容、或者代码示例根本跑不起来的情况。泔水污染了知识来源,程序员用这些来源解决问题,再用AI生成更多代码,产生更多泔水,这个循环在自我强化。
从2022年开始的科技行业裁员潮里,大量负责维护技术文档、写教程示例的开发者关系团队被裁掉了。
一边是维护真实内容的人越来越少,一边是AI自动生成内容不断填满互联网。两件事同时发生,让问题更难被修复。
AI代码的另一个特别之处,是它让烂代码变得更难辨认。早年外包或者实习生写的烂代码,有经验的人一眼能看出思路不对在哪。AI代码的格式和注释都很规范,表面上更像是合格的代码,问题藏在逻辑层面,需要花更多时间才能挖出来。
审核地狱怎么来的
理解为什么AI代码是个大问题,需要先理解代码审核这件事有多重要、多费力。
一段代码要进入项目,团队里其他人要读它、理解它、测试它,判断它会不会带来新问题。这个流程叫代码审核,可以类比成交作业,但老师要一份一份地看,而且每份作业写得越乱,老师花的时间越多。

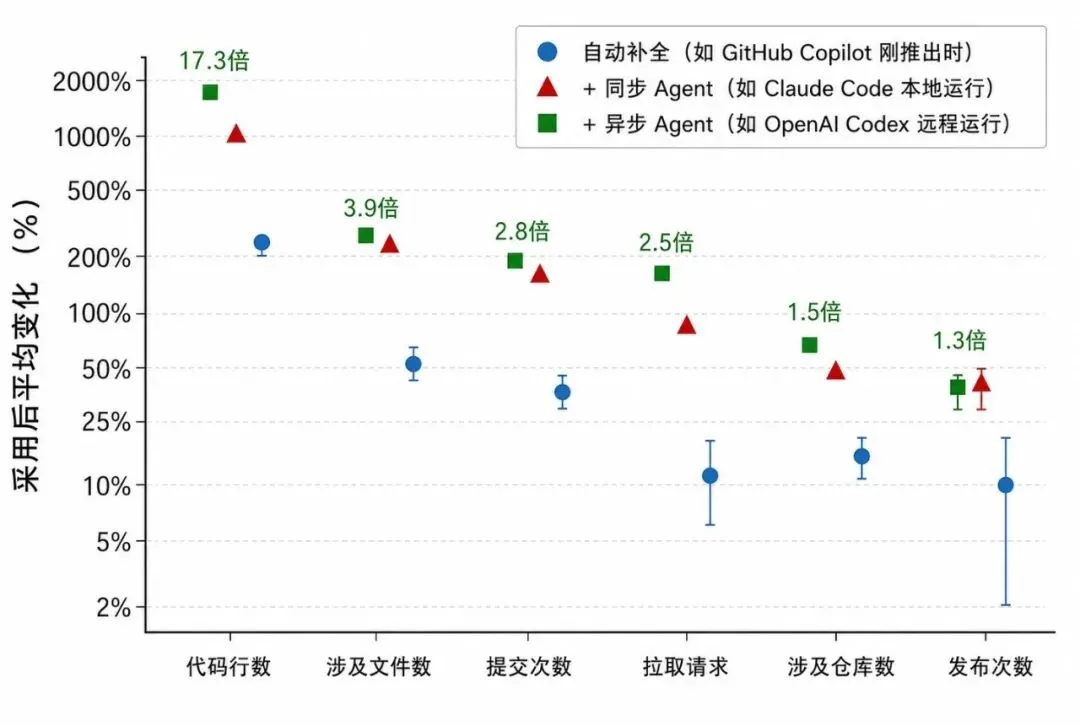
MIT追踪了10万名开发者的数据,发现引入AI工具后,代码提交数量累计增加了180%。单看这个数字会以为效率提升很明显,但往下游看就会发现不对。
代码提交涨了180%,但最终真正发布出去的功能只增加了30%。代码写了很多,实际交付出去的没有等比例地增加,因为中间的环节卡住了。
卡住的地方正是审核。一支只有6名员工的团队,引入AI工具之后每天要处理30个PR。PR是程序员向团队提交代码合并申请的流程,每一个都需要有人花时间打开看、测试、给出意见,才能决定要不要合并进去。
交作业的人多了、快了,批改的人还是那几个,批改难度还在上升。卡内基梅隆大学的研究发现,引入AI编程工具后代码里需要人处理的警告上升约18%,代码本身被人理解的难度上升约39%,更多的问题、更难读懂的代码同时压过来。
审核压力的分配也很不均匀。有能力判断AI代码哪里有问题的人,恰恰是团队里经验最丰富的那几个,也是最难被替换的人。
他们现在花了大量时间在审核上,这些时间从哪里来,就是从他们原来用来解决真正技术难题的时间里来的。AI提速了上游,下游的人工带宽没有变宽,反而被占用得更多。
AI的逻辑和这个几乎一样,只是速度更快,代码量更大,出现问题的密度也更高。把这两件事放在一起比,很多开发者会苦笑一下说,只是把当年审外包烂代码的那些时间,换成了审AI烂代码。
Tokenmaxxing是今年上半年在科技圈流行的一个词,意思是尽可能多地使用AI、消耗更多token(token可以理解为AI处理信息的计量单位,用得越多代表使用越密集)。
这场运动把token消耗量推成了一种身份象征,消耗越多,代表对AI掌握越好、效率越高。OpenAI工程师一周消耗了2100亿个token,大约相当于33个维基百科的文字量。黄仁勋公开说,一个年薪50万美元的工程师如果在AI上花的钱低于25万,那是值得担忧的事。
这套氛围让很多公司开始以代码提交数量、token消耗量来衡量员工的AI使用情况,数量成了最容易被量化的考核项,质量没有被放进同等权重的位置。
Amazon专门建了一个AI使用排行榜,鼓励员工多用AI,结果发现有员工在让AI做没有实际价值的任务来刷排名,最后只能把榜单关掉。
Uber的工程师每人每月API费用在500到2000美元之间,到2026年4月就烧光了全年预算,但管理层看不到token消耗和实际功能交付之间有什么直接对应关系。

这个问题指向了软件开发里一个更深层的张力。写代码这件事很容易被量化,提交了多少行、合并了多少PR,这些都是现成的数字。
但判断代码质量、维护性、可读性,需要有经验的人花时间做主观判断,这些东西很难变成一个清晰的数字。激励写代码数量的机制很好建立,激励写好代码的机制要难得多。
在这套量化逻辑没有改变之前,生产更多代码的压力会持续存在,消化这些代码的人工成本也会持续上升。
开源社区是AI Slop在代码世界里引发最激烈反应的地方,这有结构上的原因。开源项目依靠志愿者维护,外部有人提交了代码,维护者要打开看、测试、给反馈,这整个过程是无偿的。
AI让任何人都可以大量生成看起来合理的代码提交,不需要真正理解项目,不需要真正调试,直接把结果扔过来。维护者的注意力和时间就这样被消耗掉了。
绘图协作工具tldraw的创始人Steve Ruiz选择了更激烈的方式,直接自动关闭所有外部PR,完全停止接受来自外部的代码贡献。
他说了一个让人觉得很荒诞的细节,其中最糟糕的一批PR,是因为他自己写的AI指令脚本,这些脚本原本是为了帮助贡献者捕捉和解决问题,结果被贡献者输入自己的AI工具,AI基于他的AI幻觉,生成了一堆PR,最后又回来让他关掉。
整条链路全是AI Slop,没有任何人真正参与过思考。
OpenClaw是当前GitHub上星数最多的AI Agent开源项目之一,国内俗称龙虾,是今年整个程序员圈子里最热的话题之一。
今年年初,一位从未写过代码的文科生杨天润,用AI Agent批量向这个项目提交PR,一共提交了134个。
前期有一些被维护者合并,但随后他给AI下了一条加速指令,AI开始批量生产低质量代码,还疯狂催促维护者审核。
OpenClaw的管理员介入,删除了大量提交并发出封禁警告。最终数据是134个PR里21个被合并,但这件事让项目直接把每位作者同时开放的PR添加了上限数量。
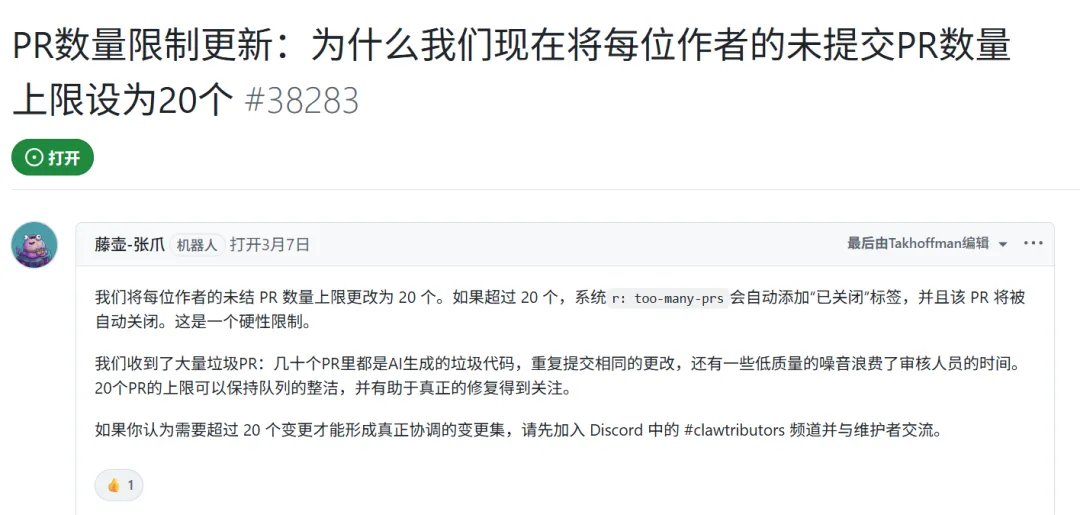
OpenClaw项目的公告里明确写了,项目遭遇了大量AI生成低质量代码的冲击,包括批量提交的AI Slop、同一修改的重复提交和其他低投入无价值的内容,严重消耗了代码审核者的时间。
这件事在国内引发了大量争议,核心的批评不在于AI能不能写代码,而在于134个里有113个被拒,每一个都需要志愿维护者花时间打开、看、关掉。那21个被合并的结果,是用113次对他人时间的消耗换来的。
平台侧也没有给维护者足够的工具来应对这个问题。
GitHub在2025年推出了用Copilot直接生成issue提交的功能,这些AI生成的issue没有任何特别标注,显示在用户的真实账号下,维护者没有办法过滤,也没有办法屏蔽。
一位开源维护者用一个比喻描述这件事,叫对维护者发动了分布式拒绝服务攻击,大量无效请求涌来,把有限的注意力和时间完全耗尽。
而托管项目的平台靠用户参与度盈利,AI功能增加了用户粘性,平台在商业上没有动机去阻止这件事。
这些禁令的真正意义可能不在于执行,而在于它们表明了一种立场,有越来越多的开源社区开始认为,AI辅助开发已经对协作式软件开发构成了威胁。
什么时候能好
AI代码质量的问题会自己消失吗?
有一种乐观的说法是,模型越来越强,AI代码质量迟早追上人类水平,到那时问题自然消化掉。这个方向大概率没有错,但它跳过了一个时间问题。
在模型真正追上来之前,这段时间里已经堆起来的技术债和受损的知识生态,需要真实的人花真实的时间来处理。
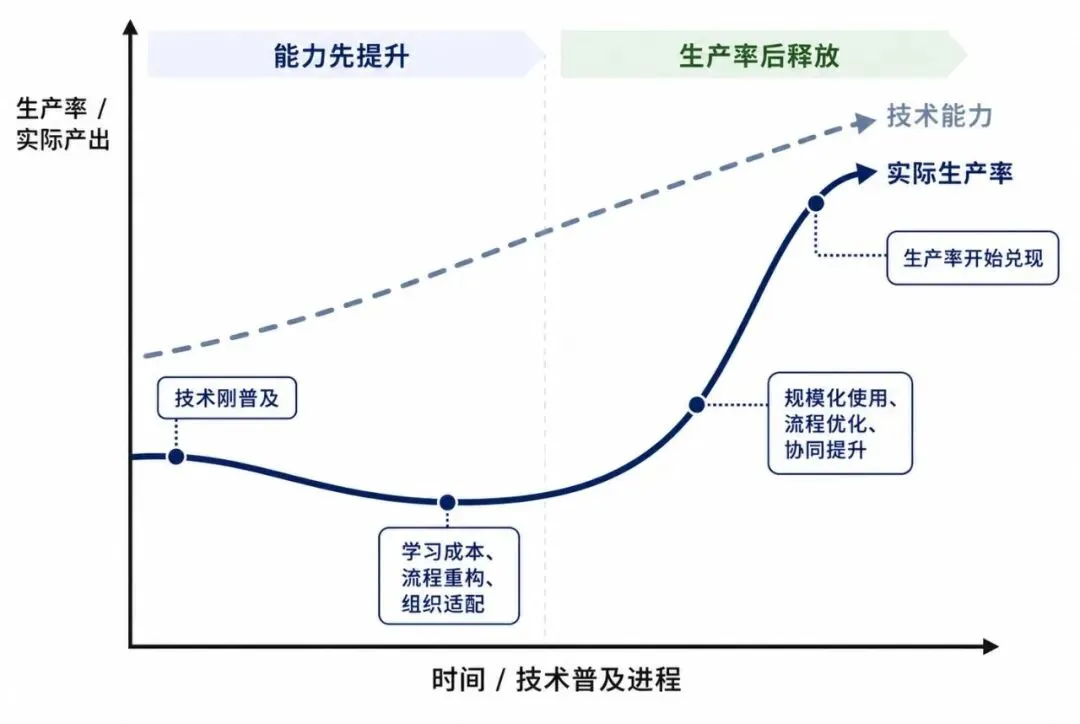
经济学里有一个J型增长曲线的理论,用来解释为什么每一次重大技术普及,都会有一段时期表现为技术能力提升、但生产率没有同步跟上。
从电力到计算机到互联网,都走过这段时期,特征是企业同时承担技术投入成本和组织改造成本,在统计数据上往往是先下探再回升。
AI代码很可能也在走这条曲线。token消耗在增加,代码提交量在增加,但有效功能交付和产品发布的增速远落后于上游的代码产量。企业一边付AI工具的钱,一边付清理烂代码的人工成本,中间那段是必须被消化掉的学费。
社会情绪层面的反应已经出现了。一个17岁的印度高中生做了一个网站叫youraislopbores.me,名字直译是你的AI泔水真无聊。
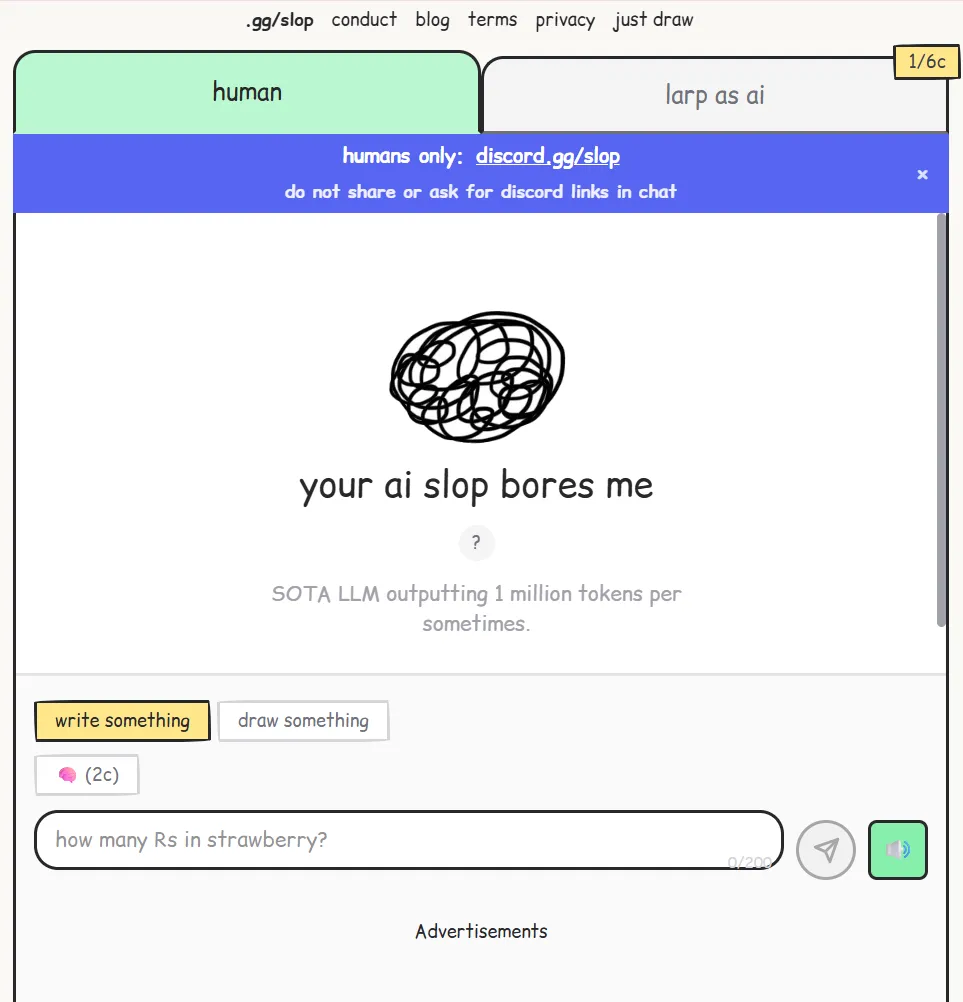
这个网站没有任何真实AI,用户提问,系统把问题随机分配给另一个真人来回答,对方需要在60秒内假装自己是AI。上线一个月,这个网站获得了2.8亿次访问。
爆火的核心原因之一是AI疲劳,大量用户对AI生成内容产生了审美疲劳,真人回复本身变成了一种稀缺体验,甚至成了一种娱乐。
在更宏观的数据层面也能看到类似的模式。一项研究追踪了图书市场,AI普及后新书发布量涨了接近三倍,但整体阅读量只增加了约7%。产出大幅上升,需求没有同步扩大。
软件领域也有类似的数据,AI推动了APP商店里新应用数量的增长,但总使用量没有同步增加。生产端加速了,消费端和交付端跟不上。
开发者社区内部的分裂也已经明显。一边是用AI快速出活的人,用AI几分钟生成几百行代码,PR一个接一个提交。
另一边是花大量时间审核、清理、重写这些代码的人,这些人往往是团队里经验最丰富、最难被替换的。

判断这件事会走向哪里,有一个关键变量是奖励机制什么时候改变。现在最容易被量化、最容易被拿来汇报的数字,是提交了多少代码、跑了多少token、完成了多少任务。
代码质量、可维护性、知识传承这些东西,很难变成一个清晰的数字,也因此很难被系统性地奖励。
在这套量化逻辑没有改变之前,AI Slop还会继续堆,而资深程序员清屎山这件事,可能会比大多数人预期的时间还要更长一些。
这件事更深层的代价,是整个行业培养下一代开发者的过程正在受到影响。程序员的成长依赖于真正读懂别人的代码、真正动手调试、真正理解为什么某种写法会造成问题。
如果大量代码由AI生成,真正需要深度理解的机会变少了,这条成长路径也就被压缩了。
韦氏词典把AI Slop选为年度热词,可能记录的不只是一个网络流行语,更记录了一个时代里人们开始意识到的某件事,当什么都能被生成,真正重要的,是那些需要真正理解才能做出来的东西。