 夜雨聆风
夜雨聆风
这两个月,每天都能看到大厂的AI PC和信创AI终端的发布会,这无疑成为了科技圈最热的话题。

但在发布会亮眼的技术参数外,一个现实的落地问题摆在了IT负责人面前:当一个机房或者办公室里,多人同时运行AI应用时,现有的GPU算力到底撑不撑得住?
从实际的部署和使用反馈看,许多公司和学校在引入高性能/大算力设备后,通常会面临三个难以绕开的痛点:
钱花了不少,但高配显卡平时大部分时间都在“吃灰”
部分学校和企事业单位为了紧跟前沿技术,采购了昂贵的GPU服务器或顶级显卡。
然而现实情况是,日常时间大家只是开网页、填Excel、写文档,那块昂贵的GPU基本就在那干瞪眼。
只有遇到特定的大模型推理或者图像识别任务,它才动一动。结果就是,IT砸了大笔预算,大牌显卡却在机房里天天“吃灰”,综合利用率低得让人肉疼。
一人在跑AI大模型,整个办公室电脑一起卡顿
有时候,问题并非GPU的性能不够,而是缺乏合理的分配与隔离机制。
以前为了省钱或者图省事,大家合用一台高性能服务器。结果只要有一个人在上面跑大模型或者剪AI视频,因为没有算力限制,瞬间就能把整张卡的显存榨干。
这就倒霉了同台服务器上的其他人,画面开始PPT式卡顿,手头的活儿只能在后台干排队。
几十人同时上课调用算力,没有先来后到,系统只能靠“硬抢”
这一痛点在学校的AI实训室或公共机房中尤为明显。
一堂实训课上,30名学生同时点击运行并调用GPU跑模型。在缺乏优先级和分配策略的情况下,算力请求只能“靠抢”。
结果通常是服务器因瞬间过载而直接崩溃,或者大部分终端卡在进度条上,导致一节课过去什么教学任务都没完成。
算力时代,GPU云桌面才是务实的解法
其实,上述问题的根源不在于GPU本身的性能好不好,而是算力没有被精细化管理起来。
用过GPU的运维人都知道,无序的流量需要调度。青葡萄GPU云桌面,就是这个“算力管家”,从底层把资源盘活:
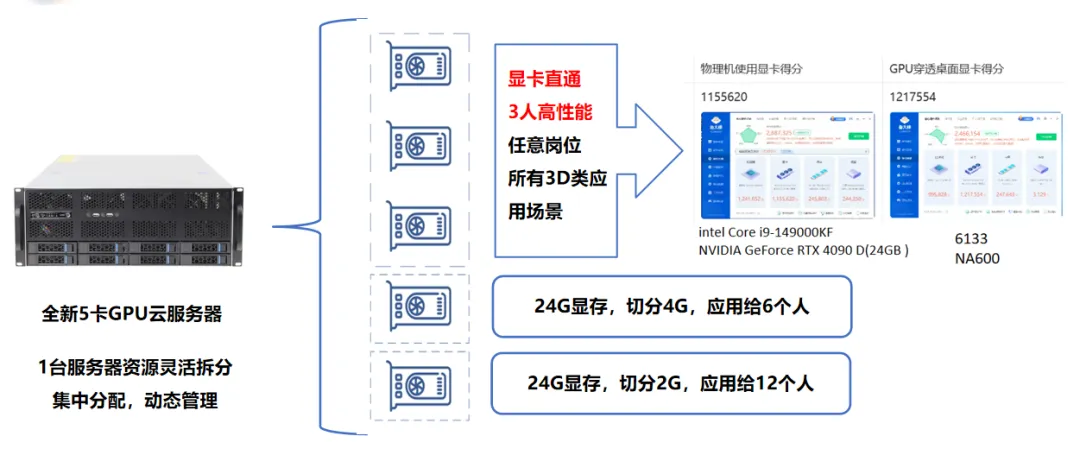
把算力共享出来,按需切开用:
简单来说,就是用虚拟化技术把一块物理GPU切成好几份,同时分给4到8台终端。日常大家敲代码、写文档时互不干扰,谁要跑AI了就从池子里调算力,再也不用担心一个人把整张显卡给榨干。
搞个弹性调度,上课时全力以赴,下课了自动让路:
在上AI实训课或者有大模型核心业务要跑的时候,算力可以一键集中分配给急需的机房;平时闲着的时候,它就会自动释放,退回到后台去支撑轻量办公,主打一个不浪费每一分硬件预算。
脏活累活后台统一搞定,不用挨个座位修电脑:
最让IT人员头疼的其实是装GPU驱动、配AI环境以及部署各种开源大模型,版本一冲突就是半天。现在这些全部在服务器端一键集中搞定。前端终端只负责画面呈现,IT管理人员再也不用去排查每台机器的软硬件冲突。
把GPU算力“池化”管理之后,IT的账本和运维逻辑也变了

最直接的就是省预算。以前总觉得跑AI就得人人配块独显,现在把核心算力往服务器一怼,前端哪怕用机房里的老旧设备、普通终端,一样能流畅跑大模型,资产利用率直接翻倍。
其次是别再想“拔河”了。依靠后端的流控和隔离,每个人的算力都被锁在自己的虚拟通道里,各用各的,彻底绝了那种“一人吃满、全员卡死”的恶性竞争。
另外,对IT老师和运维来说也省心不少。大模型镜像、AI框架直接在后台一键推送到所有桌面。老师上课不用花20分钟等学生配环境,员工办公不卡顿,这才是AI时代IT部门该有的效率。
AI PC的趋势浩浩荡荡,但硬件买回来怎么分、怎么管,才是真正考验IT部门含金量的必答题。工具不对,算力就只能变成固定资产的浪费!
想了解更多高校机房和企业中心重新定义算力分配的内容?可以一起私信聊一下~

